参考资料:
详细的背景原理介绍和优化方法 Paillier半同态加密:原理、高效实现方法和应用 - 知乎 (zhihu.com)
如何在一个月内入门密码学? - 知乎 (zhihu.com)
算法介绍和正确性推到 应用密码学 | Paillier同态加密算法简介 - 知乎 (zhihu.com)
对参数选择的讨论 paillier密码_paillier素数位数很短可以吗-CSDN博客
介绍和正确性证明 Paillier算法简介 - 知乎 (zhihu.com)
加密讲解、C++实现 Paillier半同态加密算法及C++实现 - S!no - 博客园 (cnblogs.com)
比较详细的讲解,算法推导 经典同态加密算法Paillier解读 - 原理、实现和应用_同态加密联邦学习csdn-CSDN博客
讲解、给出python实现 同态加密之Paillier算法_paillier同态加密-CSDN博客
数学基础 密码学(一):基础数学知识与密码学的简单介绍 - 知乎 (zhihu.com)
参考设计 基于Montgomery算法的高速、可配置RSA密码IP核硬件设计系列博文_密码学montgomery-CSDN博客
中国剩余定律优化 C/C++使用GMP库实现Paillier加密和解密,中国剩余定理(CRT)加速解密过程对比。<三>_使用中国剩余定理优化paillier-CSDN博客
代数基础
- 质数
- 质数,也称素数,是指只能被1和本身整除的自然数,即大于1的自然数中,除了1和它本身以外,没有其它的因数。比如2、3、5、7、11等都是质数,而4、6、8、9等则不是质数。
-
- 表示模 意义下,即 中所有与 互质的元素的集合。
-
- 表示模 意义下的可逆元素集合。具体地,对于正整数 , 包含了模 意义下与 互质的所有元素。也就是说,如果 属于 ,那么 满足以下两个条件:
- 和 互质,即;
- 在模 意义下有逆元,即存在 使得 。
- 表示模 意义下的可逆元素集合。具体地,对于正整数 , 包含了模 意义下与 互质的所有元素。也就是说,如果 属于 ,那么 满足以下两个条件:
- 欧拉函数
- ,其中 和 是两个质数
- 欧拉函数 即为 中的元素个数
- 更进一步, 的元素个数为
- 卡迈克尔函数(Carmichael’s Function)
- ,满足 ,其中 与 互质。
- 根据卡迈克尔定理(Carmichael’s Theorem),对于任意元素
- 根据卡迈克尔定理(Carmichael’s Theorem),对于任意元素
- n次剩余
- 在数论中,给定一个正整数 和一个奇素数 ,如果存在整数 使得 ,那么称 是模 的二次剩余(Quadratic Residue,QR),否则称 是模 的二次非剩余(Quadratic Non-Residue,QNR)。
- 类似地,如果存在整数 使得 ,那么称 是模 的 次剩余(nth Power Residue),否则称 是模 的 次非剩余(nth Power Non-Residue)。
- 当 时, 次剩余就是二次剩余。 次剩余和二次剩余一样,具有很多重要的应用,例如在加密算法和密码学中被广泛使用。
- 复合剩余类问题(Composite Residuosity Problem,CRP)
- 在模 意义下,给定两个整数 和 ,判断是否存在整数 ,使得 且 同时成立。其中, 是 一个合数。
0, 1比特串,长度任意 其中的最大公因数。 关于模 q 乘法运算构成阿贝尔群,当 q 为素数时为循环群。
模
- 对整数
- 同余
\begin{matrix} a\ \mod n = b\ \mod n\ a \equiv b\ (\mod n) \ 当k为整数时\ a \equiv b\ (\mod n) ⇒ ak \equiv bk\ (\mod n) \ 当k,n 互质时\ ak \equiv bk\ (\mod n) ⇒ a \equiv b\ (\mod n) \ \end{matrix}
- 模逆 $a,b$关于模$n$互为模倒数,也称模反元素或者模逆。\begin{matrix} ab \equiv 1\ (mod n) \ b \equiv \frac{1}{a}(mod\ n)\ \end{matrix}
\begin{matrix} b\ mod\ n = 1/a\ mod\ n\ (c/a)mod\ n = ((c\ mod\ n)(1/a\ mod\ n))mod\ n = (cb)mod\ n\ \end{matrix}
求模逆元可以通过遍历 ```python # find modular multiplicative inverse of 'a' under modulo 'n' def modular_multiplicative_inverse(a: int, n: int) -> int: for i in range(n): if (a * i) % n == 1: return i raise ValueError('{} has no multiplicative inverse under modulo {}'.format(a, n)) ``` 遍历效率不高,需要改进 [什么是模逆元-CSDN博客](https://blog.csdn.net/aaron67/article/details/109006977#:~:text=%E6%A8%A1%E9%80%86%E5%85%83%20%E5%8F%82%E8%80%83%E5%80%92%E6%95%B0%EF%BC%88%20xy%20%3D%201%20%EF%BC%89%E7%9A%84%E5%AE%9A%E4%B9%89%EF%BC%8C%E5%AF%B9%E6%95%B4%E6%95%B0%20a%20%E5%92%8C,b%20%E2%89%A1%20a%E2%88%921%20%28mod%20n%29%20%E7%B1%BB%E4%BC%BC%E4%BA%8E%E5%AE%9E%E6%95%B0%E9%99%A4%E6%B3%95%EF%BC%8C%E5%9C%A8%E6%A8%A1%20n%20%E4%B8%8B%E7%9A%84%E9%99%A4%E6%B3%95%E5%8F%AF%E4%BB%A5%E7%94%A8%E5%92%8C%E5%AF%B9%E5%BA%94%E6%A8%A1%E9%80%86%E5%85%83%E7%9A%84%E4%B9%98%E6%B3%95%E6%9D%A5%E8%A1%A8%E8%BE%BE%E3%80%82) # 同态加密 同态加密(Homomorphic Encryption,HE)是将数据加密后,对加密数据进行运算处理,之后对数据进行解密,解密结果等同于数据未进行加密,并进行同样的运算处理。同态加密的概念最初在1978年,由Ron Rivest,Leonard Adleman和Michael L. Dertouzos共同提出,旨在解决在不接触数据的前提下,对数据进行加工处理的问题。 满足下面的性质:\begin{matrix} 加法同态:E(a)+E(b) = E(a+b) \ 乘法同态:E(a)E(b) = E(ab) \end{matrix}
从**明文空间**和**密文空间**的角度来看,密文空间具有特定的算符。明文空间的加法对应密文空间的 ⊕ ,明文空间的乘法对应密文空间的 ⊙ 。 | 明文空间 | 密文空间 | | ---- | ------ | | 2 | Enc(2) | | + | o+ | | 3 | Enc(3) | | 5 | Enc(5) | HE是一种特殊的加密方法,它允许直接对加密数据执行计算,如加法和乘法,而计算过程不会泄露原文的任何信息。计算的结果仍然是加密的,拥有密钥的用户对处理过的密文数据进行解密后,得到的正好是处理后原文的结果。 目前,同态加密支持的运算主要为加法运算和乘法运算。根据支持的计算类型和支持程度,同态加密可以分为以下三种类型: - **半同态加密**(Partially Homomorphic Encryption, **PHE**):只支持加法或乘法中的一种运算。其中,只支持加法运算的又叫加法同态加密(Additive Homomorphic Encryption, AHE);**PHE 的优点是原理简单、易实现,缺点是仅支持一种运算(加法或乘法)**; - **部分同态加密**(Somewhat Homomorphic Encryption, **SWHE**):可同时支持加法和乘法运算,但支持的计算次数有限; - **全同态加密**(Fully Homomorphic Encryption, **FHE**):支持任意次的加法和乘法运算。FHE 有以下类别:基于理想格的 FHE 方案、基于 LWE/RLWE 的 FHE 方案等等。**FHE 的优点是支持的算子多并且运算次数没有限制,缺点是效率很低,目前还无法支撑大规模的计算。** 同态加密算法包括**全同态**(FHE)、**部分同态**(SWHE)和**半同态**(PHE)三种。FHE支持无限次的乘法和加法运算,当前算法复杂度高,实际使用较少。SWHE支持有限次的加法和乘法运算。PHE只支持加法或乘法运算中的一种。加法同态的算法有Paillier算法、DGK算法、OU算法、基于格密码的方案等。乘法同态有我们常见的RSA算法、ElGamal算法等。PHE在实际中使用的较多。 **FHE在计算有限次乘法后需要较复杂的去除噪声的操作,经典的通用MPC协议通信开销较大,而TEE的安全性高度依赖于硬件厂商,无法提供密码学上严谨的安全性。** **PHE的高效、支持无限次加法或乘法的特点,使其成为隐私计算的重要基本组件,可辅助完成多种隐私计算功能:** ## 中国剩余定理 中国剩余定理(Chinese Remainder Theorem, CRT),又称为孙子定理,源于《孙子算经》,是数论中的一个关于一元线性同余方程组的定理,说明了一元线性同余方程组有解的准则以及求解方法。 通用方程: $$ \left\{ \begin{matrix} x\equiv a_0(mod\ n_0)\\ x\equiv a_1(mod\ n_1)\\ x\equiv a_2(mod\ n_2)\\ ...\\ x\equiv a_k(mod\ n_k) \end{matrix} \right.解法流程:
- 计算所有模数的乘积
- 计算
- 解为:
Paillier:最著名的半同态加密方案
在Paillier算法出现之前,基于公钥加密的算法主要有两个分支:
- 以RSA为代表的,基于大数因数分解难题的公钥加密算法
- 以ElGama为代表的,基于大数离散对数难题的公钥加密算法 Paillier加密算法,由Pascal Paillier于1999年发表,给出了公钥加密算法的一个新的分支领域。Paillier基于复合剩余类难题,满足加法同态和数乘同态,具有非常高效的运行时性能。
Paillier是一个支持加法同态的公钥密码系统 [1],由Paillier在1999年的欧密会(EUROCRYPT)上首次提出。此后,在PKC’01中提出了Paillier方案的简化版本[26][8],是当前Paillier方案的最优方案。在众多PHE方案中,Paillier方案由于效率较高、安全性证明完备的特点,在各大顶会和实际应用中被广泛使用,是隐私计算场景中最常用的PHE实例化方案之一。
其他的支持加法同态的密码系统还有DGK [5]、OU [6]和基于格密码的方案[12]等。其中,DGK方案的密文空间相比Paillier更小,加解密效率更高,但由于算法的正确性和安全性在学术界没有得到广泛研究和验证,且我们的实验表明算法的加解密部分存在缺陷,不推荐在工业界代码中使用。OU和基于格的加法同态计算效率更高,也是PHE不错的候选项。其中OU的在方案中的使用频率相对较低,而基于格的方案密文大小较大,在一些特定场景有自身的优势。
算法思路
Paillier 半同态加密算法的安全性基于复合剩余类问题(Decisional Composite Residusity Assumption,DCRA)的困难性,即在给出 和 的情况下,很难判断模 的 次剩余是否存在: 。
加解密过程
密钥生成 KeyGeneration
- 选择两个随机的大质数 和 ,满足,且满足长度相等。
- 计算出 和
- 选取随机数 ,且满足 存在, 函数定义为
- 得到公钥为 ,私钥为
加密 Encryption
- 对于明文 ,选择随机数
解密 Decryption
- 输入密文
加法同态
对任意明文和任意,对应密文,满足:
即密文乘等于明文加
算法证明
高效加速
如果取
前面项都是的倍数,在模下,把模指数运算简化为1次模运算,即
蒙哥马利模乘
蒙哥马利模乘算法简介_montgomery modular multiplication-CSDN博客 从数学上介绍模运算: What is modular arithmetic? (article) | Khan Academy 介绍模逆元 什么是模逆元-CSDN博客
详细的从算法、代码实现讨论,并且结合一个例子。 高效幂模算法探究:Montgomery算法解析 - FreeBuf网络安全行业门户
sv实现 用SV写一个蒙哥马利模乘的参考模型 - 知乎 (zhihu.com)
蒙哥马利算法
详细的讲解,给出伪代码
- 模乘,
- 约减,
- 模幂, 集合是整数模N后得到的:,其在base-b进制下有位 这样的集合称为N的剩余环,任何属于这个集合Z的x满足下面条件
- 正整数
- 最大长度
蒙哥马利算法计算基于这个集合上的运算
剩余环上重要的运算有简单运算如加减,复杂运算如乘
 对于取模操作,一般有以下几种方法
对于取模操作,一般有以下几种方法 - 根据以下公式,来计算取模操作 取模运算即为 这种解法有以下特征
- 整个计算过程是基于标准的数字表示
- 不需要预计算(也就是提前计算一些变量,以备使用)
- 涉及到一个除法操作,非常费时和复杂
- 用Barrett reduction算法,这篇文章不细说,但是有以下特征
- 基于标准的数字表示
- 不需要预计算
- 需要次数乘运算
- 用蒙哥马利约减,也就是下面要讲的算法,有以下特征
- 不是基于标准的数字表示(后文中有提到,是基于蒙哥马利表示法)
- 需要预计算
- 需要次数乘运算
蒙哥马利预备知识
1. 除法转换
计算其实是诸位乘法相加
在十进制下又可以做简化(霍纳法则)
 例如:
对于,也可以类似处理
例如:
对于,也可以类似处理
 在剩余域下的模如,其中除于10会有小数,但可以选择一个u,,可以被10整除
在剩余域下的模如,其中除于10会有小数,但可以选择一个u,,可以被10整除
 在某些情况,除于可以转化为进制操作,因此不需要除法
在某些情况,除于可以转化为进制操作,因此不需要除法
2. 约减转换
考虑两个算法:
- 输入,计算
- 输入,计算 转化为了上面两个算法的结合即模乘和模约减 蒙哥马利算法的特点就是基于蒙哥马利表示法,将输入参数转化。 定义下面概念
- 蒙哥马利参数 给定N,N在b进制下(如2进制)有l位,gcd(N,b)=1,预计算几个值
- 指定一个最小的k,使得
- 这两个参数就是用来计算前面演变中的1000和u
- 蒙哥马利表示法 对于x,,x的蒙哥马利表示法为
蒙哥马利约减
给定整数t,
 约减可以当作模乘当x=1的特例,也可以用来计算模,如将约减可得
约减可以当作模乘当x=1的特例,也可以用来计算模,如将约减可得
蒙哥马利模乘
输入参数,结果也即

b = 10
N = 1000
b^k > N => k = 3
p = b^k = 1000
w = -667^{-1}(mod p) = 997
x = 421; xhat = 123
y = 422; yhat = 456
xhat * yhat * p^-1 = 547(mod 667)

蒙哥马利模幂
普通幂运算,通过分解,转化为一系列模乘
 用蒙哥马利做改变:
用蒙哥马利做改变:

正确性与安全性
C++ 实现
同态加密算力开销如何弥补?港科大等提出基于FPGA实现的同态加密算法硬件加速方案_澎湃号·湃客_澎湃新闻-The Paper FPGA-Based Hardware Accelerator of Homomorphic Encryption for Efficient Federated Learning
A Programmable SoC-Based Accelerator for Privacy-Enhancing Technologies and Functional Encryption
Abstract
privacy-enhancing technologies (PETs) based on additively homomorphic encryption (AHE) Present: a hardware/software (HW/SW) codesign for programmable systems-on-chip (SoCs) Impelmentation: a microcode-based multicore architecture for accelerating various PETs using AHE with large integer modular arithmetic
introduction
Many privacy problems can be avoided by encrypting the data before storing it into the cloud. Partially homomorphic encryption allows computing a limited set of operations over encrypted data.(AHE Paillier encryption) AHE are simpler and more efficient than FHE. Paillier & SEDs on the cyphertext & FE contributions:
- a programmable Soc-based architecture for accelerating large modular arithmetic(for AHE); accelerator utilizes a microcode-based architecture; a multicore structure that allows exploiting the inherent parallelism
- Instantiate in Soc and use the implementation for SEDs and FE scheme for inner products
preliminaries
A. Additively Homomorphic Encryption
AHE allows computing additions with ciphertexts
- Paillier Encryption
- Key Generation: Given a security parameter k(e.g., k = 2048), choose two random primes p, q of the length k/2, N = p*q, select a group generator g for the multiplicative group \lambda = lcm(p-1, q-1)$
- Encryption: Take a message and pk (N, g), select a random
- Decryption: take and sk
B. Use Cases of Paillier Encryption
- privacy-preserving computation of SEDs between the user’s query and the service provider’s database
- FE that is a new paradigm for encryption that permits the service provider to compute only a specific function
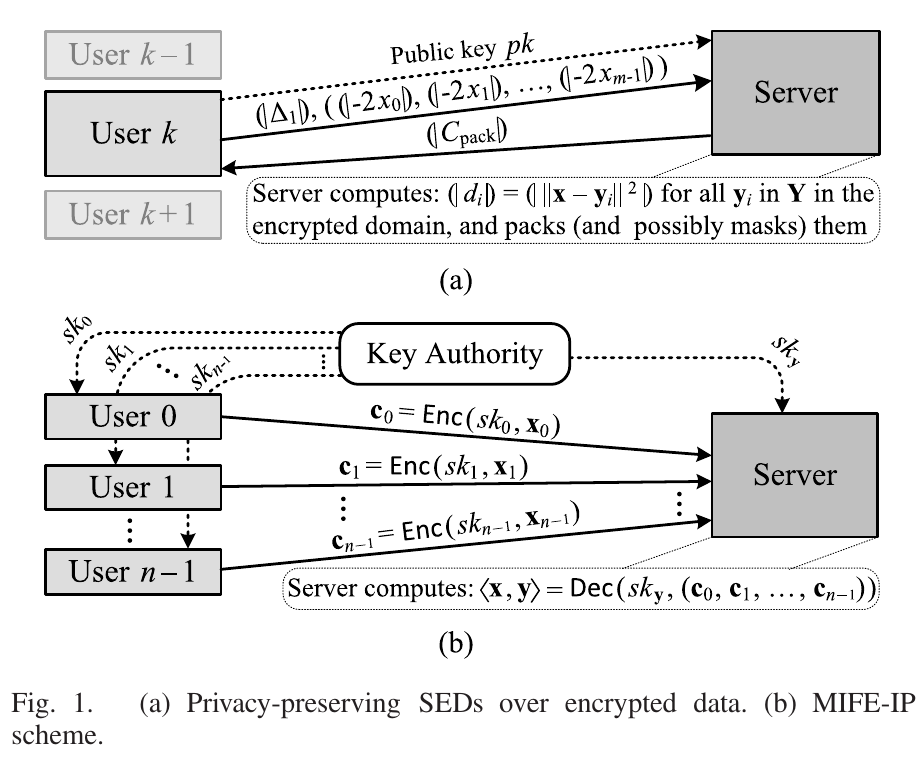
Privacy-Preserving SEDs over Encrypted Data
有m个分量,,l认为是2的幂,本文取2^8,取是列向量。 Y is in the possession of a server and x is a query sent by a user server - calculate encrypted distances |di| between the encrypted query |x| and each vector yi in Y.
Multi-Input FE for Inner Products
C. MIFE-IP Based on Paillier Encryption


III. Algorithms
A Long Integer Modular Arithmetic
bottleneck - long integer modular arithmetic operations, especially modular multiplication(MM) base modular operations on the Montgomery modular arithmetic; use algorithms for modular addition (MA) and modular subtraction (MS), montgomery reduction (MR), radix-2k Montgomery MM, and left-to-right modular exponen-tiation (ME) The implementation of these algorithms are constant time(CT) except left-to-right ME.
B. Squared Euclidean Distances
IV architecture
HW: the computationally heavy long integer modular arithmetic (e.g., MMs and MEs) SW: the computation of auxiliary operations
- inherent parallelisms in the use cases → multicore architecture including multiple parallel and programmable cryptography processor(CP) cores | Each CP core can be programmed
- the ciphertexts are large → data communication between the CP cores and the SW becomes a bottleneck
A. High-Level HW/SW Codesign
HW/SW co-design
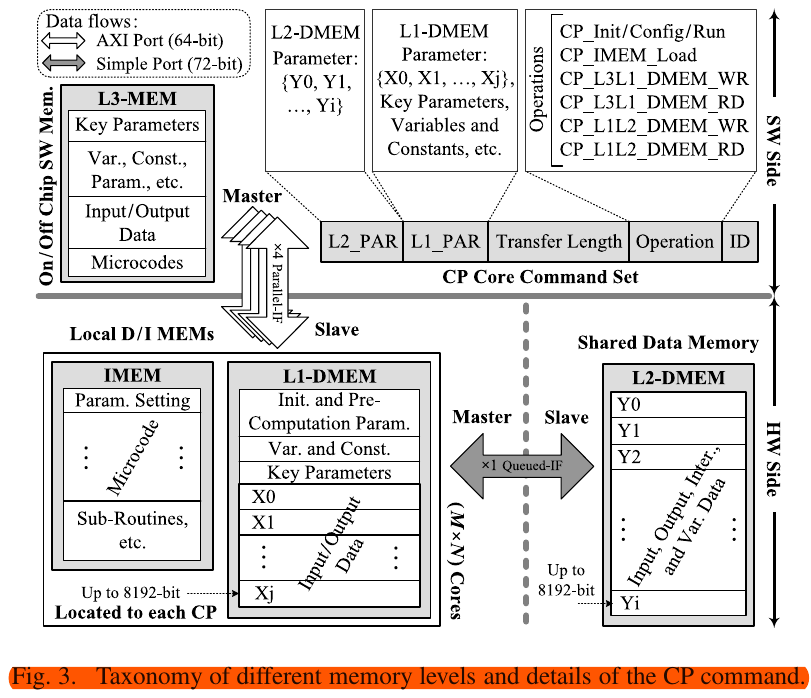
3-level Data Memory: L1 is located in each CP core; L2 is shared for all CP cores; L3 is the SW side
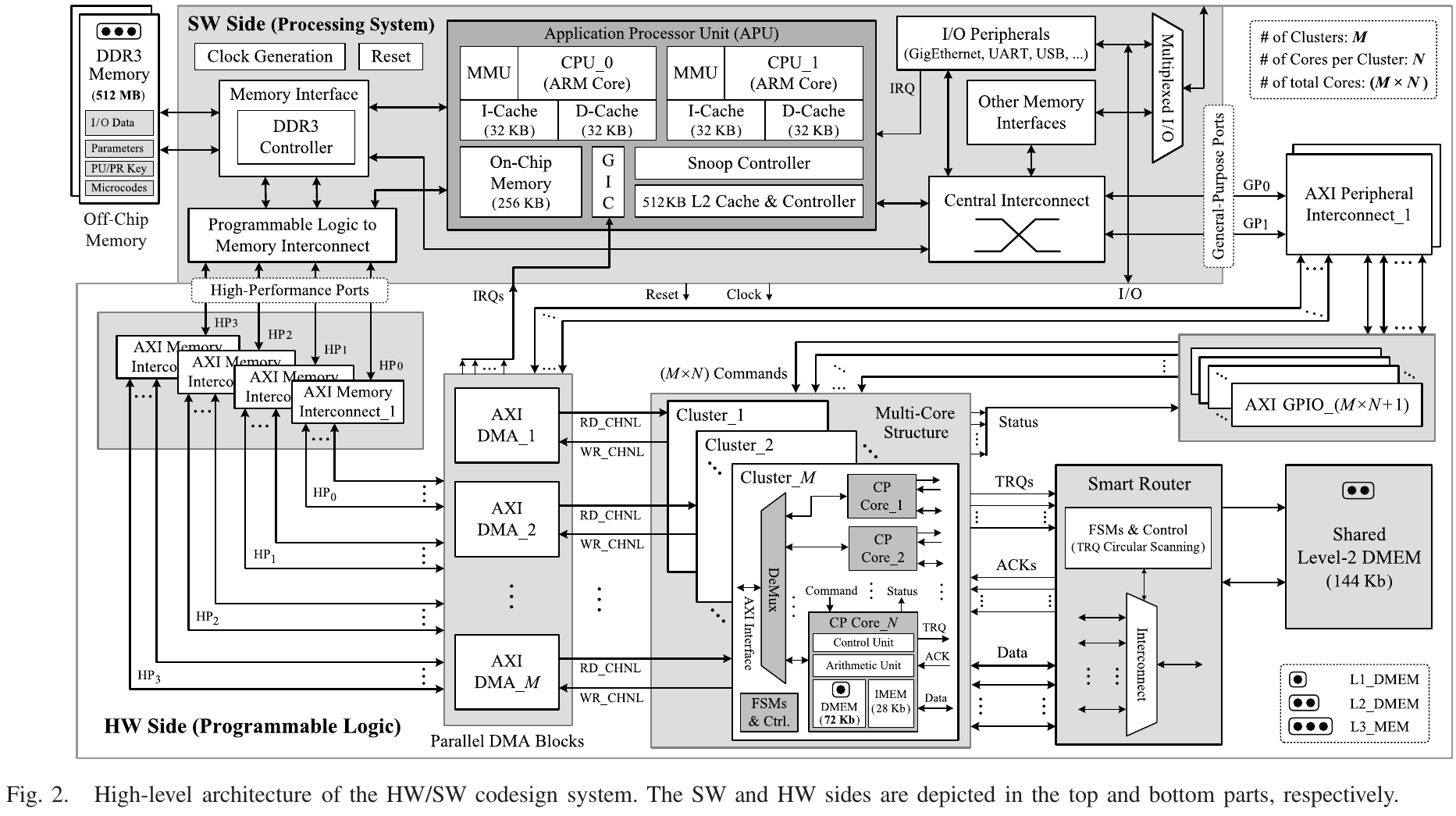
1. SW
controlling all operations in HW and peripherals(DDR3, I/O), computations not supported in HW. communication between SW&HW: 4 HP ports for transfering data; 2 GP ports for commands and status transfer
2. HW
CP cores for perfroming the actual computations and many supporting modules for data communication and storage connected in an AXI-based structure. Multicore architecture is organized into M parallel clusters where each cluster contains N parallel CP cores. Data communication between SW/HW is done via HP/AXI DMA; 4 AXI memory interconnect - M/4 AXI DMA blocks L2-DMEM contains a single-port RAM and a smart router(round-robin arbiter) for controlling the access of the CP cores to the memory
3. Configuration
B. Cryptography Core
Main idea: compact, programmable, and high-performance processor for large integer modular arithmetic optimized for the resources of modern FPGAs Implemented based on a microprogramming architecture instead of FSMs
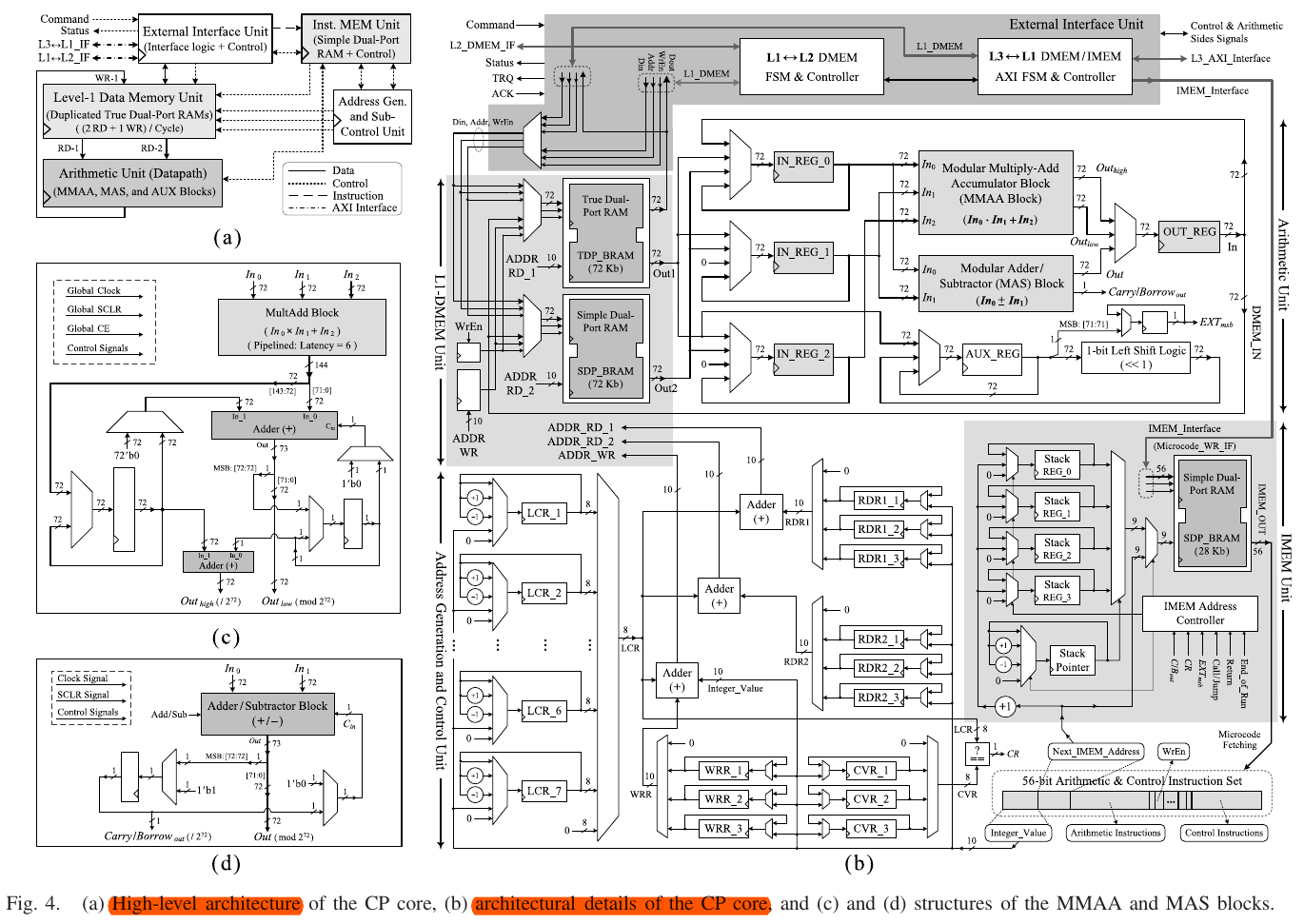
1) External Interface Unit:
2) Arithmetic Unit:
- 3 parts: 1) source registers; 2) arithmetic blocks; and 3) an output register 3 main source reg (loaded from either the L1-DMEM, output of arithmetic unit, 0, present value) → inputs for MMAA & MAS 1 output reg → source reg/L1-DMEM auxiliary part: one bit of a vector for extracting the exponent bit of ME
- MAS/MMAA(72bit)
MAS - add/sub & 1-bit carry/borrow
MMAA -
MA/MS are computed by applying MAS iteratively
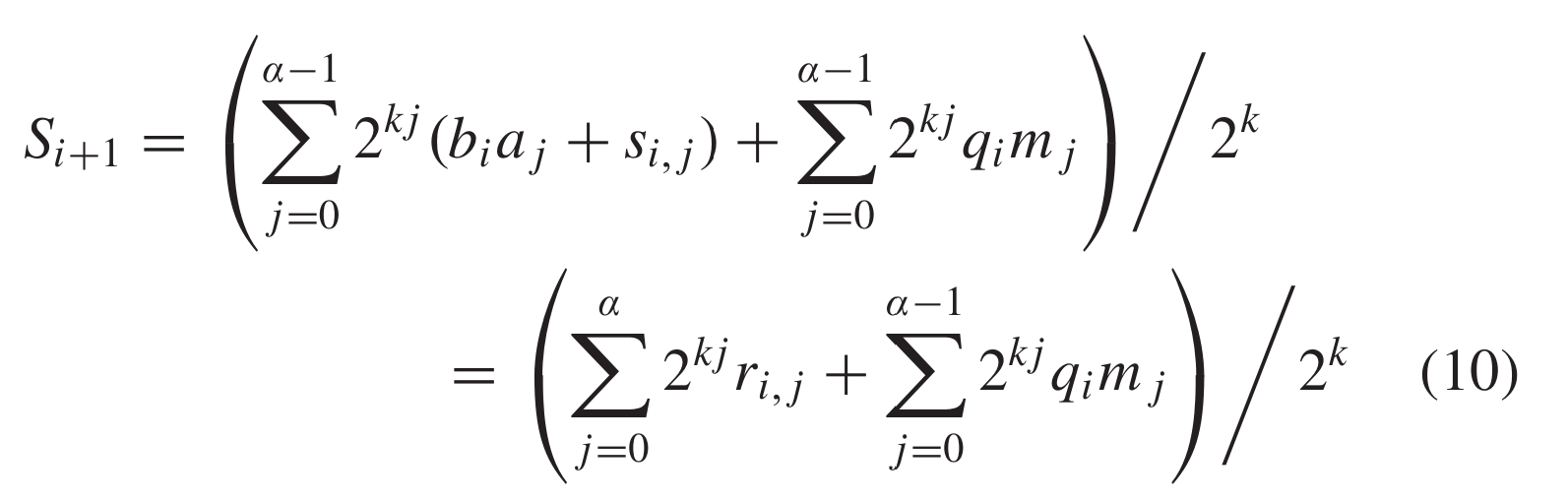
 can be implemented by iterating the MMAA block
can be implemented by iterating the MMAA block
a) MMAA block
- 2 parts: 1) multiply-adder block, 2) complementary part for accumulation and modular operations MultiAdd: 6-level pipelined; 3 72-bit inputs → 1 144-bit output lower 72-bit part of the output is accumulated 73-bit result: 72-bit lower part is Outlow; 1-bit MSB for the next accumulation higher 72-bit for the next accumulation MultiAdd 72-bit higher part is the higher part of the previous MMAA MultiAdd as the primary computing block, is implemented using DSP
b) MAS block
works in 6 modes
3. Data Memory Unit
L1-DMEM is the local memory for each CP and used for storing data for algorithm L1-DMEM - duplicated RAM: one true dual-port/ one simple dual-port → two reads and one write in one cycle
4. Address Generation and Control Unit
generating read and write addresses of L1-DMEM and making control decisions for loop iterations constructed based on five categories of control registers: RDR1_x, RDR2_x, WRR_x, CVR_x, LCR_y
5. Instruction Memory Unit
IMEM stores microcodes(sequences of instructions)
C. Implementation of the Use Cases in the HW/SW Codesign
-
Paillier Enc&dec enc is computed in HW using MMs&MEs; SW controls data transfers and commands dec consists of 2 phase: 1. precomputations(u, ME in HW, division/ modular inversion)
-
SED
-
MIFE-IP
D. Security Model
assumption: Paillier are secure and focus on information leakage from the implementation; no physical access or malware, only timing side-channel attacks
V result and analysis
HPCA
介绍了一些关于存储结构
除法
参考High-Speed ASIC Implementation of Paillier Cryptosystem with Homomorphism 使用恢复余数法
【HDL系列】除法器(1)——恢复余数法 - 知乎 (zhihu.com)
A Programmable SoC-Based Accelerator forPrivacy-Enhancing Technologies and Functional Encryption