3. 硬件
An Edge AI Accelerator Design Based on HDC Model for Real-time EEG-based Emotion Recognition System with RISC-V FPGA Platform
摘要:
- 论文提出了一种基于超维计算(HDC)模型的边缘 AI 加速器设计,该设计利用 FPGA 和 RISC-V 平台,针对使用 EEG 信号的实时情感识别系统。
- HDC 模型在功耗效率和计算复杂性方面相较于传统神经网络具有优势,适合资源受限的 IoT 设备和边缘计算。
- 在 17 通道 EEG 数据分析中,所提出的 HDC 模型在情感分析上达到了 79.04% 的愉悦度(valence)准确率和 85.95% 的唤醒度(arousal)准确率。
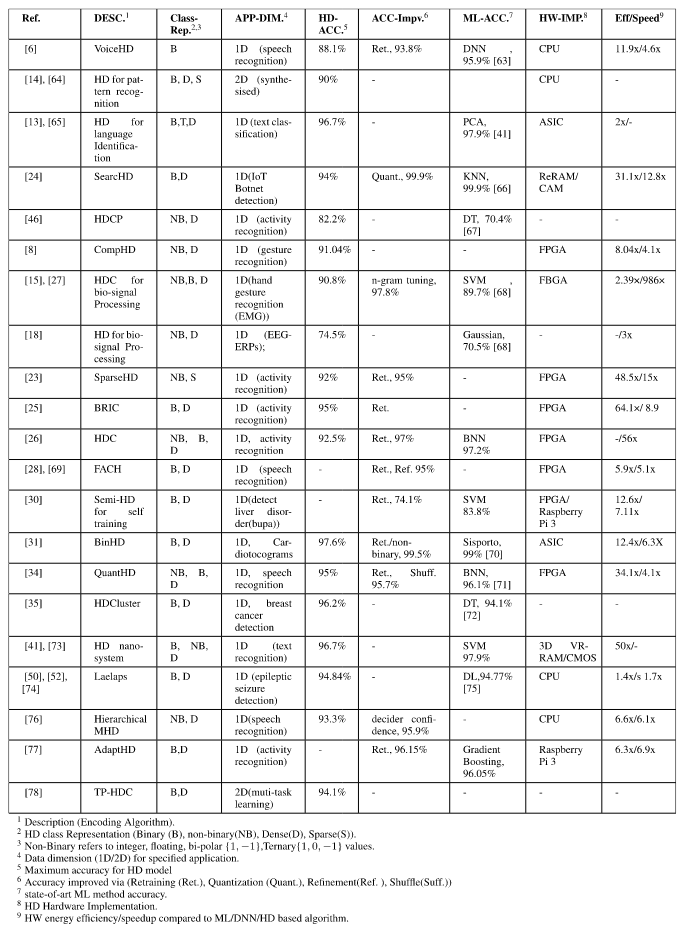
- 硬件设计在 TSMC 16 纳米技术模拟中实现了 500 MHz 的频率和 42.69 nJ/prediction 的能效,比传统 AI 高出 2.1 倍的能效。
2. 系统架构:
- 实时 EEG 情感识别系统包括前端电路、RISC-V 平台、基于 HDC 的边缘 AI 加速器和用于显示的笔记本电脑。
- 使用干电极 EEG 头戴设备测量 17 通道原始 EEG 数据,数据通过蓝牙传输到 RISC-V FPGA 平台进行后续信号处理。
- RISC-V 处理器执行带通滤波和短时傅里叶变换,提取频率域特征。
- 通过基线归一化和量化 EEG 信号频谱图,将数据转换为 200 级表示,以提高数据表示效率并降低计算复杂性。
- 边缘 AI 加速器基于超维计算处理量化的 EEG 频谱图,将其转换为超向量,用于训练或分类情感。
3. HDC 硬件设计:
- HDC AI 加速器包括顶层控制器、数据存储、超向量映射、空间编码器、时间编码器、联想记忆和汉明距离计算。
- 使用硬连线连接网络和 XOR 门实现 CiM 和 CiM-Hz,使用元胞自动机生成 iM 超向量。
- 空间编码器使用位异或门执行绑定操作,时间编码器设计为 7 位移寄存器,联想记忆包含二进制和整数模型。
4. 实验结果:
- 使用公共 EEG 数据集 SEED 和高雄医学大学(KMU)收集的私有 EEG 数据集验证 HDC 模型。
- 在 KMU 数据集上,达到了 79.04% 的愉悦度准确率和 85.95% 的唤醒度准确率。
- 与其他最新工作相比,HDC 模型在唤醒度类别上表现出更高的准确率,而在愉悦度上略有降低。
5. 结论:
- 论文介绍了一种使用 HDC 的边缘 AI 加速器,用于实时基于 EEG 的情感识别,强调速度、效率和能效。
- 在 Kintex 7 FPGA 上实现的 HDC 加速器在 TSMC 16 纳米技术上运行速度为 500 MHz,能效为 42.69 nJ 每次预测。
- 未来的工作将集中在再生、重新训练和其他技术以提高精度和输出维度,通过 AI 和 IoT 驱动的情感识别在医疗保健中实现个性化干预和福祉。
基于 HDC 用 FPGA RISCV 平台,设计的实时表情识别系统
算法集合了 BPF STFT HDC 等方法,完成 EEG 信号检测,有算法测试和硬件设计
N-gram 来源于 NLP
其算法框架来源 A. Menon et al., ”A Highly Energy-Efficient Hyperdimensional Computing Processor for Biosignal Classification,”
XOR
Manuel Schmuck, Luca Benini, and Abbas Rahimi. 2019. Hardware Optimizations of Dense Binary Hyperdimensional Computing: Rematerialization of Hypervectors, Binarized Bundling, and Combinational Associative Memory. J. Em
Rule 90 A. Menon et al., ”A Highly Energy-Efficient Hyperdimensional Computing Processor for Biosignal Classification,”
数据集:
SEEDKMU
LOSOV 验证方法
EcoFlex-HDP: High-Speed and Low-Power and Programmable Hyperdimensional-Computing Platform with CPU Co-processing
结合 Cortex A 9 SoC
HDC 优点:能效高、易于硬件并行
challenge: specialized arithmetic operations
HPU 专用加速单元和 CPU 结合,开发软件栈,验证了 3 个数据集的功能。
Hyper-Dimensional Computing Challenges and Opportunities for AI Applications
Abstract
That includes a fully holographic random representation, high-dimension vectors representing data, and robustness to uncertainty.
maps different representations of inputs into a single class and stores them in the associative memory (AM) throughout the training stage. Later, during the inference stage, the similarity is computed between the query vector, which is encoded using the same encoding model, and the stored classes in the AM.
work well for 1 D app with less power, low latency than DNN
2 D, DNN has higher accuracy at the expense of more computations
Intro
CNNs provide excellent classification accuracy at the cost of large 26 memory storage, memory access, and computing complexity.
But we need to move the processing of ML o edge devices.
- sensitive to response time
- security and privacy
- transferring the data from/to cloud is costly
- ML algorithm is impractical for real-time edge devices.
BG
A HD Properties and Operations
high dimension gives the ability for analogical and hierarchical reasoing. HD can be used to build structures such as sequences, images, lists.
operations - MAP:
Multiplication (binding): bitwire XOR operation. The output is orthogonal (dissimilar to the HV being bound)
Addition (Bundling): add together and threshold (when the set is odd, yields 0 for more than bits are zero; When n is even, one more random vectors is added)
“threshold sum”, “majority sum”, “consensus sum” denoted as
Permutation (Shifting): important when the order is important.
Pipeline
- IM: map inputs into high space
- CIM: two close numbers have a small distance and are considered as semi-orthogonal. The vecotors are required to retain during training and testing stages.
- Encoding: combnes all encoded hyper-vectors in the train and inference stage.
- AM: stores all the trained HV to be used for the iterference. Two similarity measurements are the Hamming and cosine.
Encoding
Common Roots
- Multi-set of n-sequence
- Features superposition
Encoding Schemes
Benchmark
1 D
| app | ref | inno |
|---|---|---|
| Random Indexing (RI) | 37-40 | language |
| identifying language | 41 |
sensory input
biomedical (body-sensing)
2 D
VI case Study for HDC and CNN
HDC accuracy vs size/dimension
HDC Vs CNN
- HDC doesn’t include the computationally demanding training step in CNN. It departs from the dimensionality reduction and focuses on dimensionality expansion. challenge - encoding takes too much time.
- HDC outperforms DNN in 1 D data set
accuracy
precision
recall
Future Works
- the sensitivity of the HDC model depends on: dimension, mapping, building.
(1) exploit HDC intrinsic characteristics for more classification/cognitive tasks in different domains like security, image processing, and real-time applications.
(2) focus on developing an efficient encoding algorithm that handles HDC capacity limitation and would improve data representation for 2 D applications.
(3) develop more hardware friendly metrics for similarity measurement that would enhance system accuracy.
(4) design a unified HD processor that addresses diverse data types and can trade-offs accuracy to efficiency based on the application requirements.
(5) investigate the dimension of HD vector that store and manipulate different data representations to reduce the memory footprint and enhance system efficiency.
(6) study various methods for integrating the DL/ML techniques with HDC and analyzing system performance effects.
VoiceHD: Hyperdimensional Computing for Efficient Speech Recognition
HD + NN 框架
分别评估算法和 RTL 效果
benchmark Isolet
PULP-HD: Accelerating Brain-Inspired High-Dimensional Computing on a Parallel Ultra-Low Power Platform
A Robust and Energy-Efficient Classifier Using Brain-Inspired Hyperdimensional Computing
摘要:
- 论文介绍了一种基于大脑启发的高维(超维)计算的分类器,这种计算方式使用高维向量(超向量)代替数字进行计算。
- 超向量具有高维、全息和(伪)随机独立同分布(i.i.d.)分量的特性,能够在容忍硬件变化的同时实现能效计算。
- 通过语言识别实验,展示了该高维分类器的准确性(96.7%)、能效(比传统方法低一半能耗)和对内存单元故障的容忍度(在 8.8 倍故障概率下仍保持 94% 的准确性)。
1. 引言:
- 随着 CMOS 晶体管尺寸的减小,性能和能效的常规提升不再保证,尤其是在原子特征尺寸附近的设备制造中,任何尺寸、掺杂等的变化都会对设备和电路行为产生重大影响。
- 生物和大脑启发的信息处理架构是提高能效的一个有前景的新途径,它们在容忍纳米尺度变化的同时,渐近地接近大脑计算的效率。
2. 超维计算:
- 超维计算基于大脑计算的数学属性,大脑通过神经活动的模式而非数字进行计算。
- 超向量是全息的,并且具有 i.i.d.分量,它们通过向量空间中的点来模拟神经活动模式。
- 论文中的目标应用是识别文本样本的语言,通过将连续字母编码成超向量。
3. 基于内存的高维分类器架构:
- 提出了一种模块化、可扩展的基于内存的架构,用于高维分类器,包括编码和相似性搜索两个主要模块。
- 编码模块将输入文本转换为高维空间中的超向量,然后与一组预训练的超向量进行比较。
- 相似性搜索模块存储一组预计算的语言超向量,并使用余弦相似度作为相似性度量。
4. 实验结果:
- 使用 21 种欧洲语言的数据集进行语言识别实验,与基于 N-gram 直方图的最近邻分类器进行比较。
- 高维分类器在能量效率和对内存错误的鲁棒性方面优于基线方法。
5. 结论:
- 提出的高维分类器是一种鲁棒且能效高的硬件设计,它利用高维空间的数学属性,包括高维、全息和 i.i.d.分量的(伪)随机表示,以及执行过程中缺乏控制流。
总结
HDC 展示得与脑行为一致。它式高维、全息、伪随机的向量。高能效的计算容忍硬件故障。
方法:基于超维分类的硬件。超高准确率,略低于传统机器学习方法,只需一半的能量。此外可以容忍 8.8 倍的存储单元错误,保持高准确率。
总体算法没介绍清除,
HYPERDIMENSIONAL COMPUTING
Hyperdimensional computing [7] is based on the understanding that brains compute with patterns of neural activity that are not readily associated with numbers. In fact, the brain’s ability to calculate with numbers is feeble.
A hypervector contains all the information combined and spread across all its bits in a full holistic representation
随机索引 [5,6] 是一种基于高维度和随机性的算法,它为基于主成分的方法(包括潜在语义分析)提供了一种简单且可扩展的替代方案。它是增量式的,在文本数据的一次传递中计算语义载体。
T. F. Wu et al., “Brain-inspired computing exploiting carbon nanotube FETs and resistive RAM: Hyperdimensional computing case study,” ISSCC, 2018.
基于存内计算
Revisiting HyperDimensional Learning for FPGA and Low-Power Architectures
现有的算法太过复杂,无法在资源算力受限的 IoT 设备实时运算。HDC 通过高维向量的表示模拟认知计算。但是面临问题:编码模块复杂,在线推理的分类数增多,模型和计算开销增多。
发掘计算宠用来记忆编码模块、简化但存储访问的计算;压缩 HDC 模型为单超向量
在 arm FPGA 上实现,做了多个任务 activity recognition, face recognition, and speech recognition
基于人脑的 HDC,有诸多优势:轻量、高效、直观
Abstract
challeng:
(i) the encoding module is costly, dominating 80% of the entire training performance,
(ii) the HDC model size and the computation cost grow significantly with the number of classes in online inference.
method:
1 computation reuse to memorize the encoding module and simplify its computation with single memory access.
2 exploiting HDC governing mathematics that compresses the HDC trained model into a single hypervector
I Intro
A Highly Energy-Efficient Hyperdimensional Computing Processor for Biosignal Classification
摘要
- 本文介绍了一种高效的高维计算(HDC)处理器,用于生物信号分类。该处理器通过使用轻量级元胞自动机实时生成超向量,替代了传统的存储内存,显著提高了能量效率。在超过 200 个通道的情感识别数据集上进行了实时分类的后布局模拟,与现有的 HDC 处理器相比,所提出的架构在能量效率上提高了 4.9 倍,每个通道的效率提高了 9.5 倍。在最大吞吐量下,架构实现了 10.7 倍的改进,每个通道 33.5 倍。此外,还设计了一个优化的支持向量机(SVM)处理器作为对比,HDC 在能量效率上比 SVM 高出 9.5 倍。
关键点
- 高维计算(HDC):一种基于大脑启发的计算范式,操作伪随机超向量以执行高准确度的分类任务。
- 元胞自动机:用于实时生成超向量,替代传统的存储内存,减少了存储成本。
- 向量折叠技术:与元胞自动机结合使用,以优化实时分类的能耗和延迟。
- 性能对比:与现有的 HDC 处理器和 SVM 处理器相比,所提出的 HDC 处理器在能量效率上有显著提升。
- 应用场景:特别适用于需要大量通道的生物信号监测设备,如可穿戴设备。
结论
- 本研究提出的 HDC 处理器在保持高分类准确性的同时,实现了极高的能量效率,使其成为高准确度、高能量效率的板上生物信号分类的首选范式。
未来工作
- 探索在不同基准测试中应用这些技术,包括非生理时间序列任务,如关键词识别或异常检测。
- 比较 HDC 与其他传统机器学习算法(如卷积神经网络)在算法性能和硬件效率方面的优势和局限性。
- 研究 HDC 向量压缩技术,以解决随着类别增加而出现的存储问题。
这篇文章展示了 HDC 在生物信号分类领域的潜力,并提出了一种新的高效能处理器架构,为未来的生物信号处理和分类任务提供了新的方向。
总结
应用了已经提出的方法对 HDC 硬件的设计进行优化,包括 CA Vector folding,并且评估了不同参数对性能、功耗的影响。
应用:生物信号分类。
CA 实时生成超向量,替代了传统的存储内存,提高能效。
在超过 200 个通道的情感识别数据集上进行了实时分类的后布局模拟,与现有的 HDC 处理器相比,所提出的架构在能量效率上提高了 4.9 倍,每个通道的效率提高了 9.5 倍。在最大吞吐量下,架构实现了 10.7 倍的改进,每个通道 33.5 倍。此外,还设计了一个优化的支持向量机(SVM)处理器作为对比,HDC 在能量效率上比 SVM 高出 9.5 倍。
HDC 能效比 SVM 高
对于具有十几个通道的应用,HDC 的性能优于支持向量机。对于 HDC ROM 设计,由于内存成本较大,只有在通道数大于 96 的情况下才是如此
SVM 在低通道数时确实表现得更好,因为支持向量与通道数直接相关。然而,HDC 使用 2000 位超向量,而不考虑通道的数量,这使得基线单通道体系结构更加昂贵。
然而,这在超矢量大小仍然恒定而不是像支持向量机那样增加的较高通道计数时很有帮助。通过充分利用该范例的简单性和最小计算量,不需要专门的存储块而仅使用标准单元,HDC 获得了比支持向量机 (372.2 nJ/预测) 高 9.5 倍的能效。
【1】原理解释
【2-5】应用
【6-7】有少数据、一元训练、快速更新等优势
p 8-13] 目前的一些 ASIC 应用领域
14-15 HDC 硬件设计。
16-18 CIM
19 20 CA rule 90 方法生成 HV
21 - 24 AMIGOS emotion dataset 和一些算法实现
25 PULP 对比 HDC 与其他算法的硬件开销
之前的工作表明,HDC 的维度最好为 1000-2048
26 - CA rule 90 与 vector folding 结合
Implementation
- mapping into the HD space generated in the HV generator using CA rule 90.
- spatial encoder accumulate the mapped vectors across all channels. one channel one time fuser bundles these modality HVs temporal encoder, as an n-gram AM stores prototype HVs for each data class
Vector Folding
HV datapath can be folded to a fraction of the hypervector dimension
This method is applicable until the number of folds is above this point,
算法框架来源 [5]
A Programmable Hyper-Dimensional Processor Architecture for Human-Centric IoT
摘要
- 本文介绍了一种用于人类中心物联网 (IoT) 的可编程高维计算 (HDC) 处理器架构。
- HDC 是一种基于随机高维向量的操作范式,以其在序列预测任务中的竞争力、较小的模型尺寸和较短的训练时间而受到关注。
- 该处理器架构旨在实现超低能耗的监督分类,其简单构造遵循基本的 HD 操作,并且具有高度并行、浅数据路径 (<10 逻辑层),类似于内存计算。
- 该架构还支持可扩展性:可以通过并行连接多个处理器来增加有效的 HD 维度。通过对 HDC 和三种传统机器学习 (ML) 算法在传统架构 (如 CPU 和嵌入式 GPU) 上的比较,
- 进行了广泛的评估,并在 28 nm HK/MG 工艺中综合了一个 2048 维 ASIC 设计,针对 9 个不同复杂度的监督分类任务进行了基准测试。模拟的芯片在整个基准测试中的能耗效率低于 1.5μJ/pred,大多数应用的能耗低于 700 nJ/pred。
关键点
- 高维计算 (HDC):一种基于随机高维向量的计算范式,适用于人类中心的 IoT 应用。
- 处理器架构:提出了一种完整的、可编程的架构,用于使用 HD 计算进行超低能耗的监督分类。
- 性能评估:与 CPU 和嵌入式 GPU 上的 HDC 和传统 ML 算法的性能进行了比较。
- ASIC 设计:在 28 nm HK/MG 工艺中综合了一个 2048 维的 ASIC 设计,并在多个监督分类任务上进行了基准测试。
- 该研究提出的 HDC 处理器在保持高分类准确度的同时,实现了极高的能量效率,使其成为适用于高准确度、高能量效率的生物信号分类任务的理想选择。
总结
可编程的 HDC 处理器
对 HDC 的操作进行总结,MAP
基准:用了多个例子,建立了和传统算法的对比,在 CPU / GPU 上
- 结构 分析数据流: 两种核心模式:n-gram feature superposition 主要成分:IM/Encode/ AM 根据数据流,设计了基本单元,然后构成层次
II HDC
HV 的正交性
A. The Binary HDC Subset
MAP
- Multiplication/Binding:
- Addition/Superposition: , vector sum of operands and thresholding each element at the mean (0 for bipolar code)
- Permutation: a unary operation such that the permuted vector (denoted by ρ(x)). use circular shift
B. Example: Language Recognition
- Baseline: n-Gram Character Model
- HDC Setup and Algorithm: characters from the Latin alphabet are assigned to uniformly generated hyper-vectors of dimension D = 10, 000. performance:
- HDC has an accuracy of 96.7 % against a baseline of 97.1 %
- However, it is an online algorithm requiring a single iteration though the dataset.
- 20× smaller than the baseline
III BENCHMARK APPLICATIONS
openHD 组有相关实验,说明了 retraining 的作用
- very well for sequence prediction problems especially when the generating process is Markov of finite order with a known upper bound suitable for sensor-based IoT applications ML techniques require more memory or operations.
- For an arbitrary prediction problem: a hybrid system of HDC and ML/deep-learning algorithm is perhaps superior to either approach separately
application:
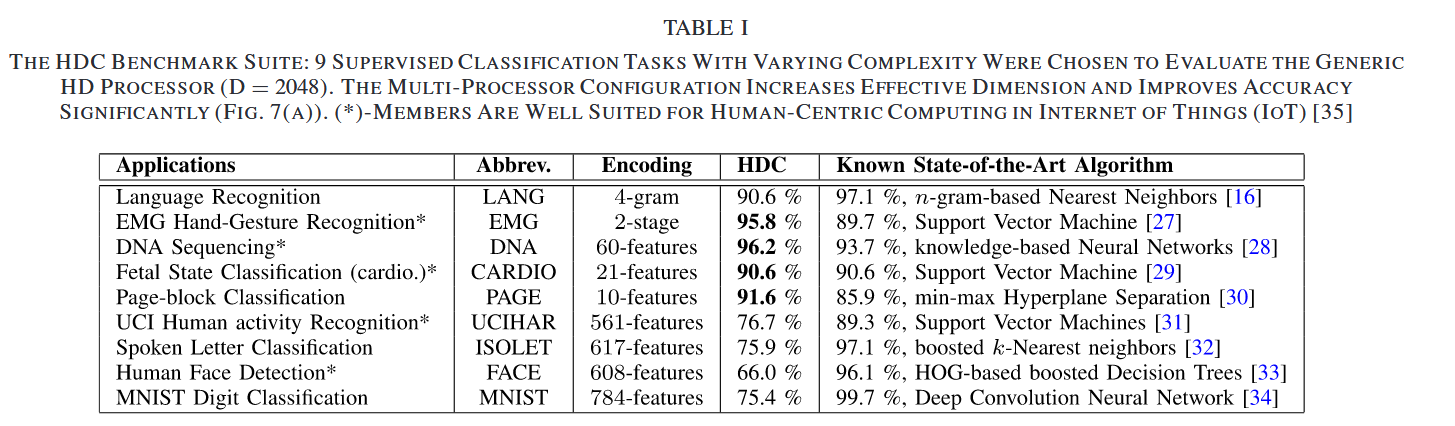 It is also balanced overall: MNIST, FACE and ISOLET represent the fact that known HDC algorithms alone applied on raw features cannot compare to ML for even simple speech and vision problems.
It is also balanced overall: MNIST, FACE and ISOLET represent the fact that known HDC algorithms alone applied on raw features cannot compare to ML for even simple speech and vision problems.
IV. PROFILING ON CONVENTIONAL ARCHITECTURES
CPU
GPU
ASIC
V. GENERIC ARCHITECTURE
A. Structure of HD Programs
- Value Representation: usually pre-determinated
- Stages in HD Algorithms: the application-specific encoding stage is an expression of hyper-vectors Xt , t ∈ NT ??
- The ‘Generic’ Model: ???
B. Common Algorithmic Kernels
- n-gram Sequence Encoding all occurring n-sequences in the input are encoded and superimposed
- Feature Superposition All the feature veactors are binded and bundled
1) 值表示(Value Representation)
- HDC 程序处理的输入数据需要被量化成离散状态,并以有限频率采样。这意味着输入数据被转换成一系列符号(例如,来自特征空间的符号),这些符号可以被序列化处理。
- 输入数据被建模为一个有限长度的时间序列符号(例如,),其中每个 属于一个预定义的符号集 。
2) HDC 算法的阶段(Stages in HD Algorithms)
- 分配随机超向量(Item Assignment):为符号集 中的每个符号分配一个随机超向量(item),形成共同的项目集 ( X )。
- 输入序列的超向量化(Input Sequence Hyper-vectorization): 中,每个 中的项,对应一个随机 HV,得到 。将符号序列 替换为对应的超向量序列 ,其中每个 。
- 应用特定编码(Application-Specific Encoding):根据应用特定的算法,将输入的超向量序列 ( I ) 转换成单个类别向量。这个过程涉及到超向量的组合,使用 MAP(乘法/绑定、加法/叠加、排列)操作。
A single-stage algorithm is defined as any HD algorithm where superposition is used only once.
,其中,
是输入的超向量序列, 是没有经过排列的输入超向量,而 是经过排列的输入超向量。这里的 ( \oplus ) 表示 XOR 操作,用于结合(绑定)超向量,而 表示将超向量 循环位移 次。
- 在单阶段算法中,所有的项向量 将通过叠加操作(通常是 XOR 或加法操作)组合起来,生成最终的超向量表示。 这个公式的关键点在于,它展示了如何通过结合未排列和排列的输入超向量来生成一个单一的项向量,这个项向量能够捕捉输入数据的特定特征。在单阶段算法中,这种操作只执行一次,因此称为“单阶段”。这种方法的简洁性和效率使其适合于实时处理和资源受限的环境,如物联网(IoT)设备。
3) ‘通用’模型(The ‘Generic’ Model)
- 项向量生成(Term Vector Generation):在监督分类任务中,主要复杂性在于生成 个项向量 。每个项 依赖于特定的输入值,并且可以通过应用特定的 MAP 操作来生成。
- 序列生成的依赖性(Dependency in Sequential Generation):由于输入流是时间序列,所有 ( K ) 个项向量可以顺序生成。这意味着,一旦确定了输入依赖性的基本模式,就可以通过固定的延迟来生成后续项。
总结
这一部分强调了 HDC 程序的基本结构,包括如何将输入数据转换为超向量,以及如何通过 MAP 操作来处理这些超向量。这种结构使得 HDC 程序能够以一种高效且可扩展的方式来处理复杂的数据集,特别是在监督学习任务中。通过理解 HDC 程序的结构,可以更好地设计和优化 HDC 硬件架构,以实现更高的能效和性能。
C. Major Components
- Item Memory (IM) stores a repertoire of random hyper-vectors (items). A sufficiently large collection of such vectors can be re-used for many applications.
- Encoder combines the input hyper-vectors sequence according to an application-specific algorithm to form single vector per class.
- Associative Memory (AM) stores the trained class hyper-vectors. During testing, the class hyper-vector closest to the encoded test hyper-vector is returned as the final prediction.
features:
- Uni-directional Dataflow: For all applications, hyper-vectors always flow from IM to Encoder to AM during both training and testing. There are no iterations
- Single programmable component: Only the Encoder needs to be programmed for an application.
Conclusion
The generic abstraction (Section V-A.3) shows that one can develop a simple architecture that can be programmed easily
cosine similarity/ re-training/ hierarchical HDC algorithms
associative mem
提升性能的其他方法
在机器学习中,特征降维(feature reduction)或特征选择(feature selection)是减少数据集中特征数量的过程,目的是提高模型的性能,减少计算复杂度,以及降低过拟合的风险。以下是一些常用的特征降维和特征选择方法,以及相关的文章和资源:
1. 特征选择方法(Feature Selection)
过滤方法(Filter Methods):
- 这些方法根据统计测试评估每个特征与目标变量之间的关系,选择最有信息量的特征。
- 例子:卡方检验、互信息、方差阈值法等。
- 文章:“Feature Selection for Machine Learning: A Guide to Feature Selection” 介绍了多种特征选择方法。
包装方法(Wrapper Methods):
- 这些方法将特征选择过程视为搜索问题,评估不同特征子集的模型性能。
- 例子:递归特征消除(RFE)、前向选择、后向消除等。
- 文章:“A Comparative Study of Feature Selection Techniques for Machine Learning” 比较了不同的特征选择技术。
嵌入方法(Embedded Methods):
- 这些方法在模型训练过程中进行特征选择。
- 例子:LASSO 回归、决策树、随机森林等。
- 文章:“The Elements of Statistical Learning” 深入讨论了 LASSO 和岭回归等方法。
2. 特征降维方法(Feature Reduction)
主成分分析(PCA):
- PCA 通过线性变换将数据转换到新的特征空间,新特征是原始特征的线性组合,保留了数据中最重要的方差。
- 文章:“PCA vs Autoencoders for Dimensionality Reduction” 比较了 PCA 和自编码器。
线性判别分析(LDA):
- LDA 旨在找到一个特征空间,使得不同类别的数据尽可能分开。
- 文章:“Linear Discriminant Analysis (LDA)” 解释了 LDA 的原理和应用。
t- 分布随机邻域嵌入(t-SNE):
- t-SNE 是一种非线性降维技术,用于将高维数据集转换为低维(通常是二维或三维)的可视化表示。
- 文章:“t-SNE: A Brief Introduction” 提供了 t-SNE 的简要介绍。
自编码器(Autoencoders):
- 自编码器是一种神经网络,通过训练网络学习输入数据的压缩表示。
- 文章:“Dimensionality Reduction Using Autoencoders” 讨论了如何使用自编码器进行降维。
这些方法在不同的场景和数据类型中有不同的应用和效果。选择合适的方法需要考虑数据的特性、模型的需求以及计算资源等因素。
Cellular Automata Can Reduce Memory Requirements of Collective-State Computing
通过 CA 90 在每次访问时产生随机数据。
an elementary cellular automaton with rule 90 (CA 90) enables the space–time tradeoff for collectivestate computing models that use random dense binary representations, i.e., memory requirements can be traded off with computation running CA 90
Cellular automata (CA) are simple discrete computations capable of producing complex random behavior
B. CA-Based Expansion
In the elementary CA, the new state of a cell at the next step depends on its current state and the states of its immediate neighbors.
CA 90 利用 XOR 操作
VoiceHD: Hyperdimensional Computing for Efficient Speech Recognition
Efficient Biosignal Processing Using Hyperdimensional Computing: Network Templates for Combined Learning and Classification of ExG Signals
DNA sequencing: determining the order of nucleotides present in a DNA molecule(A G C T) existing techniques - k-Nearest Neighbor (KNN) and Support Vector Machine (SVM). They show poor accuracy with long sequences and computationally slow and expensive to run on ligh weight devices.
M. Imani et al., “Exploring hyperdimensional associative memory,” in High Performance Computer Architecture (HPCA) 用到了 CIM 方法
HDNA: Energy-Efficient DNA Sequencing Using Hyperdimensional Computing
HDNA
encoder and associative memory (AM)
two encoding schemes:
- N-gram: add all n-gram HVs together; cannot store the order of all n-grams in the final sequence.
- record-based using mul&add: assign a unique ID HV to each base position.
其实就是 n-gram 和特征
F 5-HD: Fast Flexible FPGA-based Framework for Refreshing Hyperdimensional Computing
robust/ less data for training
2.2 Related Wtudies
[17]
[13]
[21]
Some leverage advances of emerging technologies.
3 Framework
- Model specification
- Design Analyzer: determine the number of resources, number of PUs/PEs.
- Model Generator: Verilog implementation/ BRAM.
- Scheduler: Binarized representation reduces the accuracy. This framework supports binary/ power-of-two, fixed-point.
Training Modes
support model initialization, retraining, online retraining.
In te online hybrid retraining mode, the system executes both inference and retraining.
SparseHD: Algorithm-Hardware Co-Optimization for Efficient High-Dimensional Computing
FPGA implementation of sparse HD computation that supports both the dimension-wise and class-wise sparse models.