Overview
This page provides a technical overview of the PyTorch codebase, focusing on its high-level architecture, major systems, and their relationships. The goal is to orient developers and contributors to the main subsystems, their code entry points, and how they interact to enable dynamic graph capture, optimization, and execution across multiple hardware backends.
PyTorch’s architecture is organized around a modular compilation pipeline, device backends, distributed training support, and advanced features such as export, quantization, and shape analysis. The most critical systems are the compilation pipeline (TorchDynamo, FX, TorchInductor), device backends (CUDA, MPS, CPU, XPU, MTIA), and deployment/export infrastructure.
For detailed information on the compilation pipeline, see page [2]. For device backends, see page [3]. For distributed training, see page [4].
High-Level System Architecture
Diagram: PyTorch Core System Overview
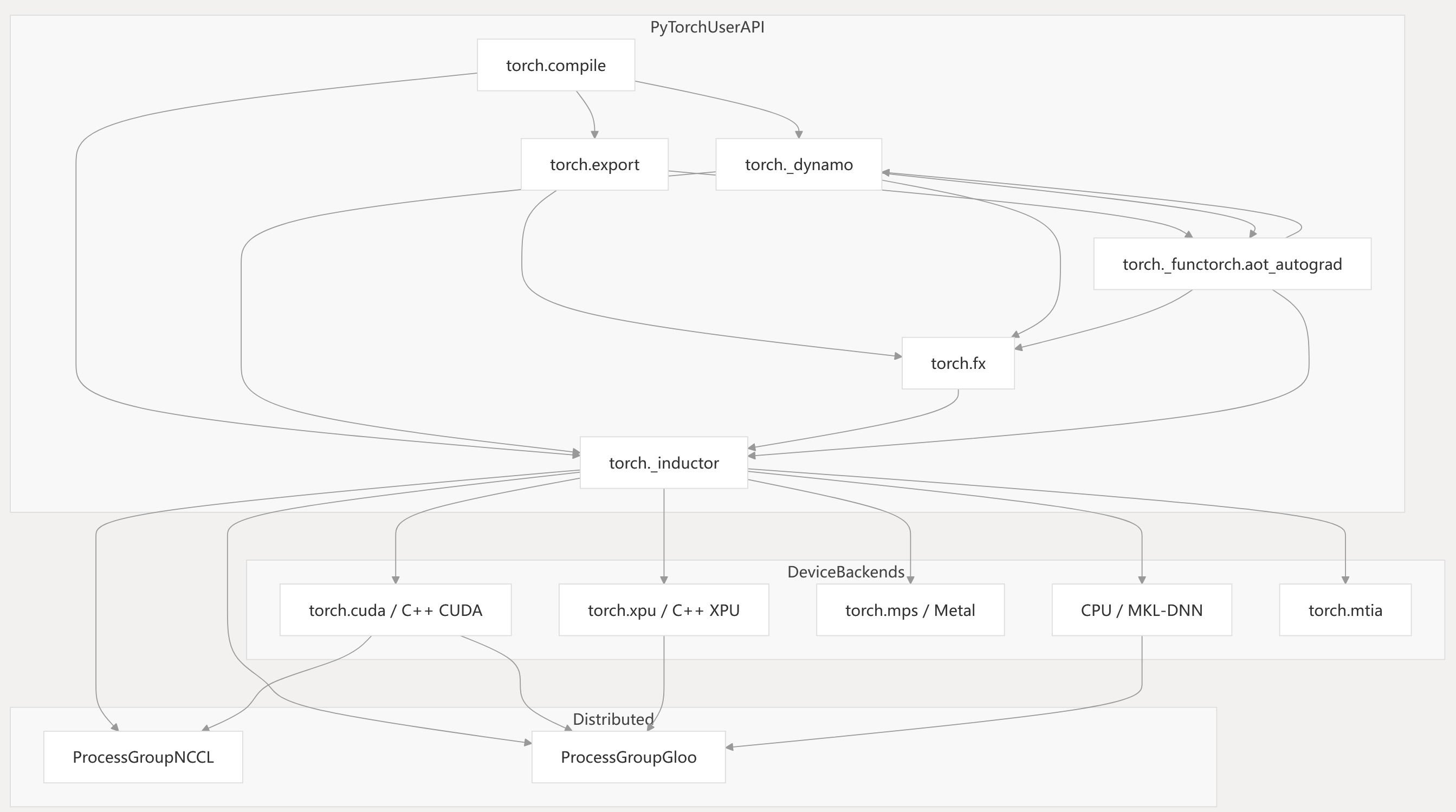 Key points:
Key points:
- User entrypoints are
torch.compileandtorch.export. torch._dynamotraces Python code and produces FX graphs.torch._inductorlowers FX graphs to device-specific kernels.- Device backends execute generated kernels.
- Distributed backends enable multi-device/multi-node training.
torch/_dynamo/eval_frame.py1-100 torch/_inductor/config.py1-100 torch/_inductor/compile_fx.py1-100 torch/_inductor/codecache.py1-100 torch/_dynamo/guards.py1-100 torch/_dynamo/utils.py1-100
Major Systems and Code Entry Points
The following diagram maps major system names to their primary code entities and files.
Diagram: System-to-Code Mapping
| System | Main Code Entry Points / Files |
|---|---|
| TorchDynamo | torch/_dynamo/eval_frame.py, torch/_dynamo/guards.py |
| FX | torch/fx/graph.py, torch/fx/symbolic_shapes.py |
| TorchInductor | torch/_inductor/compile_fx.py, torch/_inductor/ir.py |
| Device Backends | torch/cuda/, torch/xpu/, torch/mps/, aten/src/ATen/ |
| Code Cache | torch/_inductor/codecache.py |
| Export | torch/export/, torch/export/graph_signature.py |
| Distributed | torch/distributed/ |
Sources: torch/_dynamo/eval_frame.py1-100 torch/_dynamo/guards.py1-100 torch/_inductor/compile_fx.py1-100 torch/_inductor/ir.py1-100 torch/_inductor/codecache.py1-100
torch/export/graph_signature.py1-100
Compilation and Execution Pipeline
The core of PyTorch’s system is the compilation pipeline, which transforms user code into optimized device code.
Diagram: Compilation and Execution Pipeline
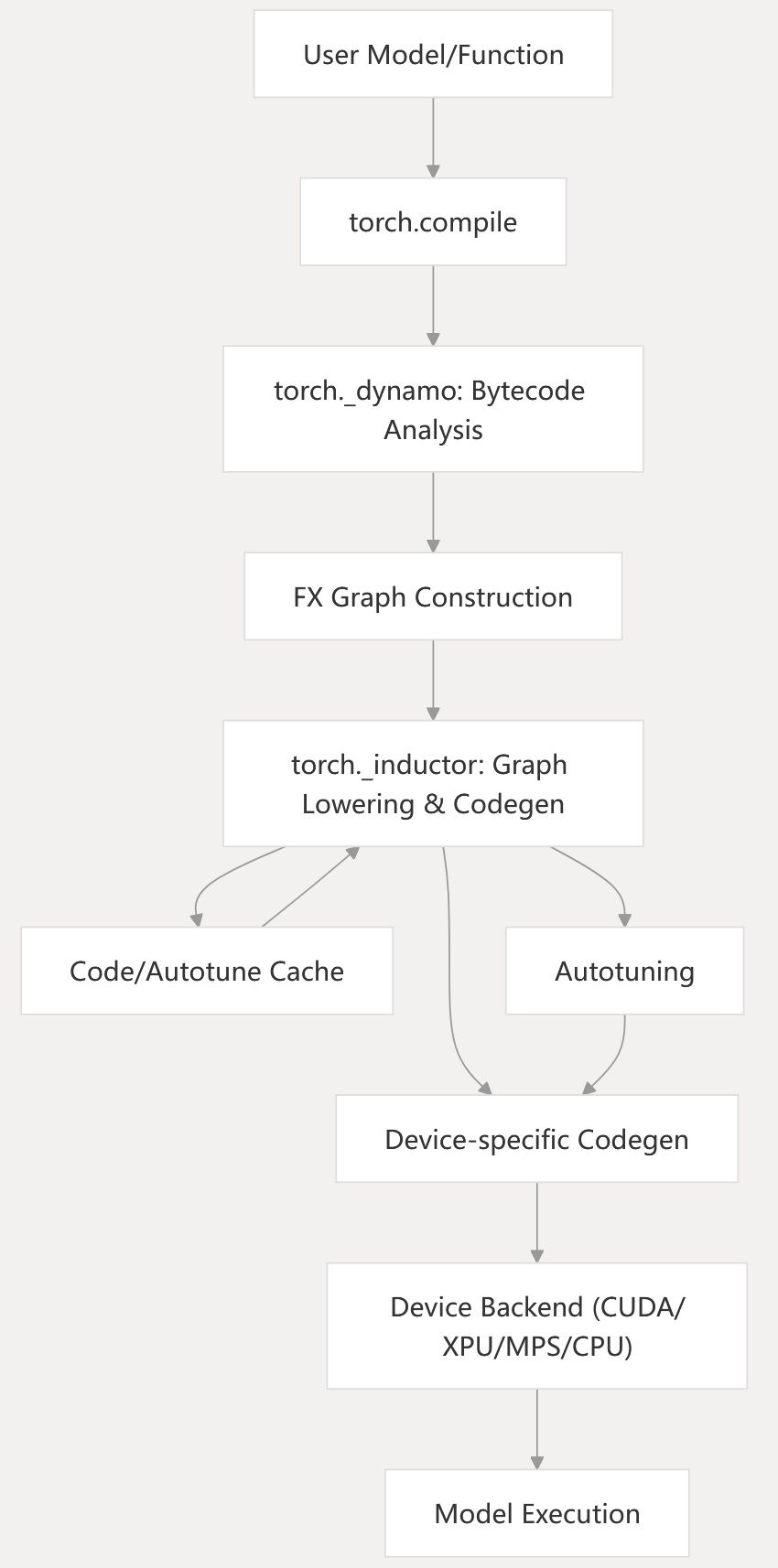
torch._dynamotraces Python bytecode and builds FX graphs.torch._inductorlowers FX graphs, schedules, fuses, and generates device code.- Device backends execute the generated code.
- Caching and autotuning are used for repeated executions.
torch/_dynamo/eval_frame.py1-100 torch/_dynamo/guards.py1-100 torch/_inductor/compile_fx.py1-100 torch/_inductor/codecache.py1-100
System Responsibilities and Relationships
| Subsystem | Responsibilities | Key Files / Classes / Functions |
|---|---|---|
| torch._dynamo | Python bytecode tracing, guard management, FX graph extraction | eval_frame.py, guards.py, symbolic_convert.py |
| torch.fx | Graph IR, graph transformations, pattern matching | graph.py, symbolic_shapes.py |
| torch._inductor | FX graph lowering, IR, scheduling, codegen, kernel caching, autotuning | compile_fx.py, ir.py, scheduler.py, codecache.py |
| Device Backends | Device management, memory allocation, kernel execution | torch/cuda/, torch/xpu/, torch/mps/ |
| torch.export | Model export, symbolic shape tracing, deployment workflows | export/, graph_signature.py |
| Distributed | Multi-device/multi-node training, collective communication | ProcessGroupNCCL, ProcessGroupGloo |
torch/_dynamo/eval_frame.py1-100 torch/_dynamo/guards.py1-100 torch/_inductor/compile_fx.py1-100 torch/_inductor/ir.py1-100 torch/_inductor/scheduler.py1-100 torch/_inductor/codecache.py1-100
Guard and Cache Systems
The guard system and cache layers are critical for correctness and performance.
Diagram: Guard Management and Caching
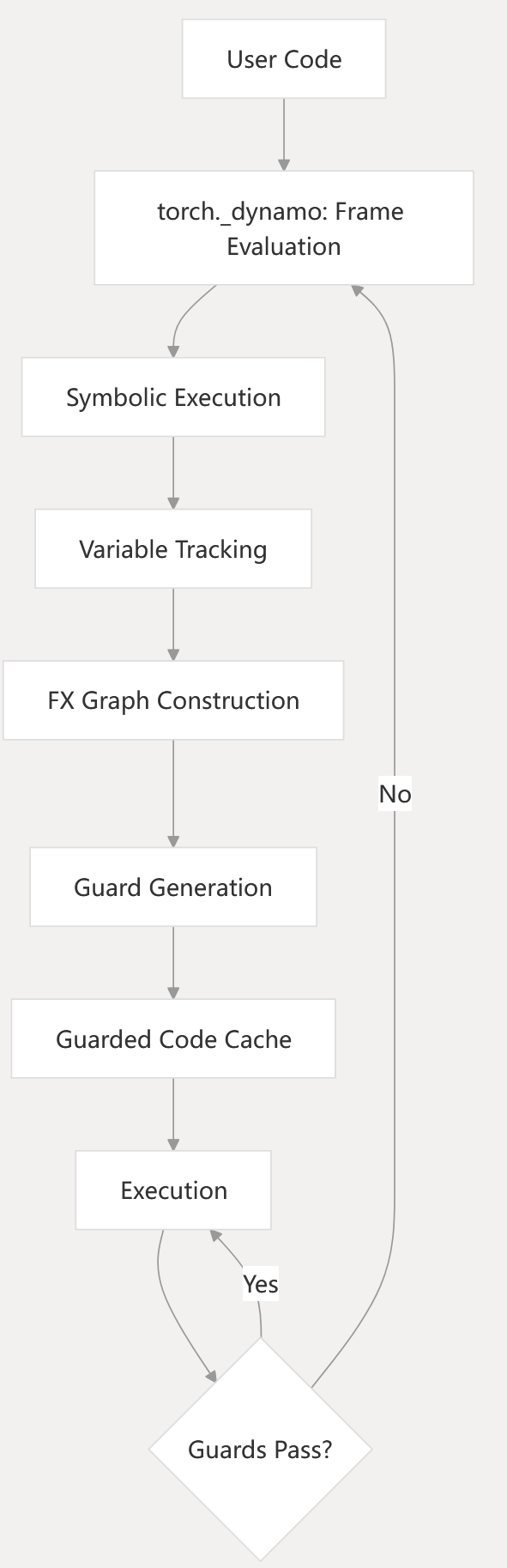
- Guards are created during tracing to track dependencies.
- Guarded code cache ensures compiled code is only reused when valid.
- If guards fail, recompilation is triggered.
torch/_dynamo/guards.py1-100 torch/_dynamo/eval_frame.py1-100 torch/_inductor/codecache.py1-100
Device Backends and Distributed Support
PyTorch supports multiple device backends and distributed training.
Diagram: Device Backend and Memory Management

- Device backends provide APIs for device selection, memory management, and kernel execution.
- Distributed communication is handled via NCCL and Gloo.
torch/_inductor/codegen/mps.py1-100 torch/_inductor/codegen/triton.py1-100 torch/_inductor/codegen/cpp_wrapper_cpu.py1-100
torch/_inductor/config.py1-100
Configuration System
Both TorchDynamo and TorchInductor have extensive configuration options:
- Runtime Behavior: Controls guard settings, specialization options
- Debugging Options: Enables logging and development features
- Performance Tuning: Adjusts optimization parameters
- Feature Toggles: Enables/disables experimental features
torch/_dynamo/config.py101-200
torch/_inductor/config.py101-300
Integration with PyTorch Ecosystem
The compilation system integrates with other PyTorch components:
- torch.export: Enables model serialization for deployment
- Distributed Training: Supports optimized distributed operations
- Quantization: Works with PyTorch’s quantization system
- Autograd: Preserves automatic differentiation capabilities
torch/_dynamo/output_graph.py1-100
Variable Tracking System
TorchDynamo uses a sophisticated variable tracking system to follow values through Python code:
![]()
Sources: torch/_dynamo/variables/builder.py1-100 torch/_dynamo/variables/functions.py1-100 torch/_dynamo/variables/builtin.py1-100torch/_dynamo/variables/user_defined.py1-100
Conclusion
PyTorch’s compilation system provides a powerful way to optimize PyTorch code for better performance. By capturing Python operations, transforming them into optimized code, and managing execution with a sophisticated guard system, it enables efficient execution across different hardware targets while maintaining the flexibility and ease of use of PyTorch.