Device-Specific Features and Limitations
Each backend has unique features and limitations based on the underlying hardware architecture and software stack.
CUDA-Specific Features
CUDA-Specific Features

MPS-Specific Features and Limitations
MPS Features and Limitations
 The MPS backend has specific limitations and version-dependent features:
The MPS backend has specific limitations and version-dependent features:
- Limited support for complex number operations
- Some operations only available on macOS 14+
- BFloat16 support requires macOS 14+
- Double precision (float64) is not supported
test/test_mps.py18-22 torch/testing/_internal/common_mps.py13-50 test/test_mps.py195-210 torch/_inductor/codegen/mps.py43-54
Device Backends
This page provides an overview of the device backend system in PyTorch. Device backends are responsible for executing tensor operations, managing device memory, and providing hardware-specific optimizations for supported compute platforms. The main backends are CUDA (NVIDIA GPUs), MPS (Apple Metal/Apple Silicon), CPU, and others such as XPU and MTIA.
Device backends are a core part of the PyTorch execution model. They are the final target for code generated by the compilation system (see page 2), and are also directly accessible via the Python API. For distributed and multi-device training, see page 4.
aten/src/ATen/native/native_functions.yaml1-100 torch/csrc/Module.cpp1-100
torch/csrc/cuda/Module.cpp1-100
Backend Architecture Overview
PyTorch’s device backend system is organized in layers, with high-level APIs dispatching to device-specific implementations via a unified dispatch and registration mechanism.
Backend System Architecture
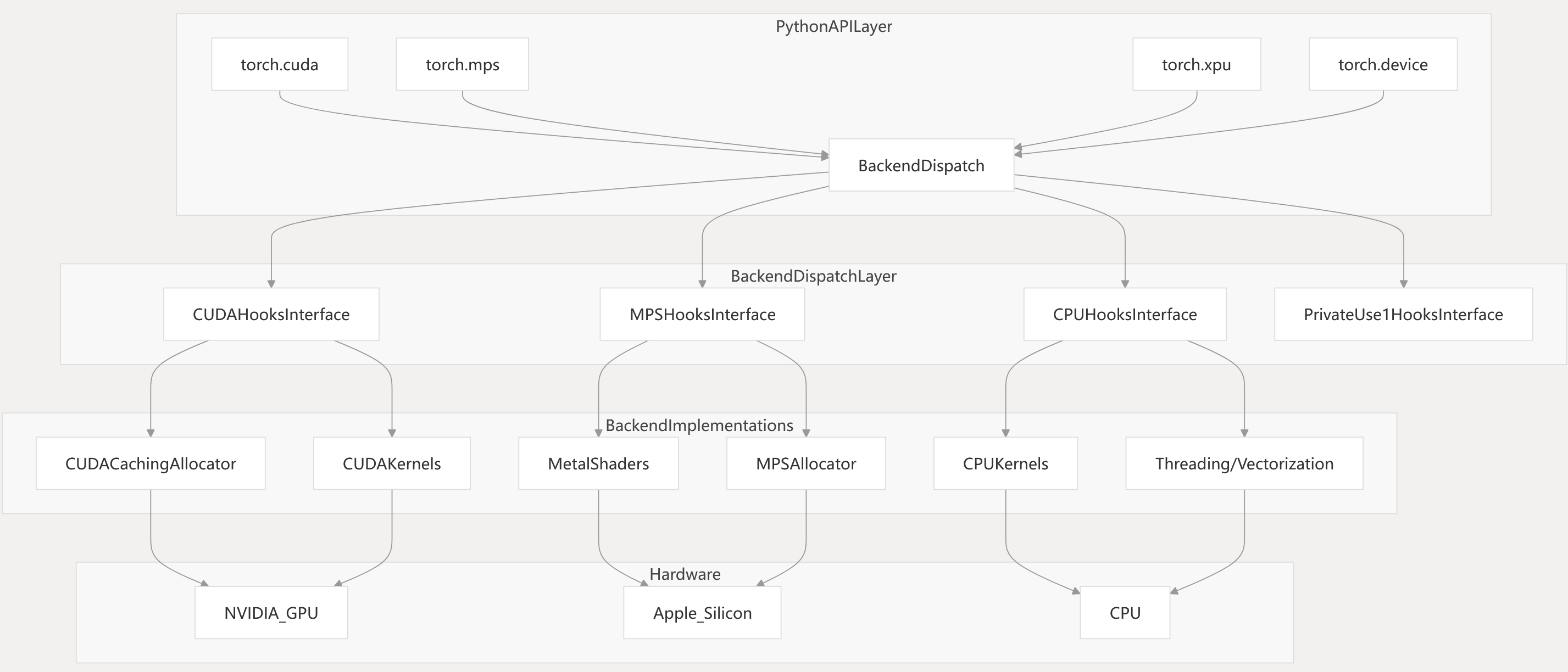
The dispatch system uses device type information to route operations to the correct backend. Each backend provides its own memory allocator, kernel implementations, and device management logic.
aten/src/ATen/native/native_functions.yaml1-100 torch/csrc/Module.cpp1-100 torch/csrc/cuda/Module.cpp1-100
Backend Dispatch Mechanism
PyTorch dispatches tensor operations to device-specific backends using a combination of dispatch keys, registration, and runtime device selection. The core mechanism is defined by the operator dispatch system and the native_functions.yaml file, which specifies which backends implement each operator.
Dispatch Flow from Operator to Backend
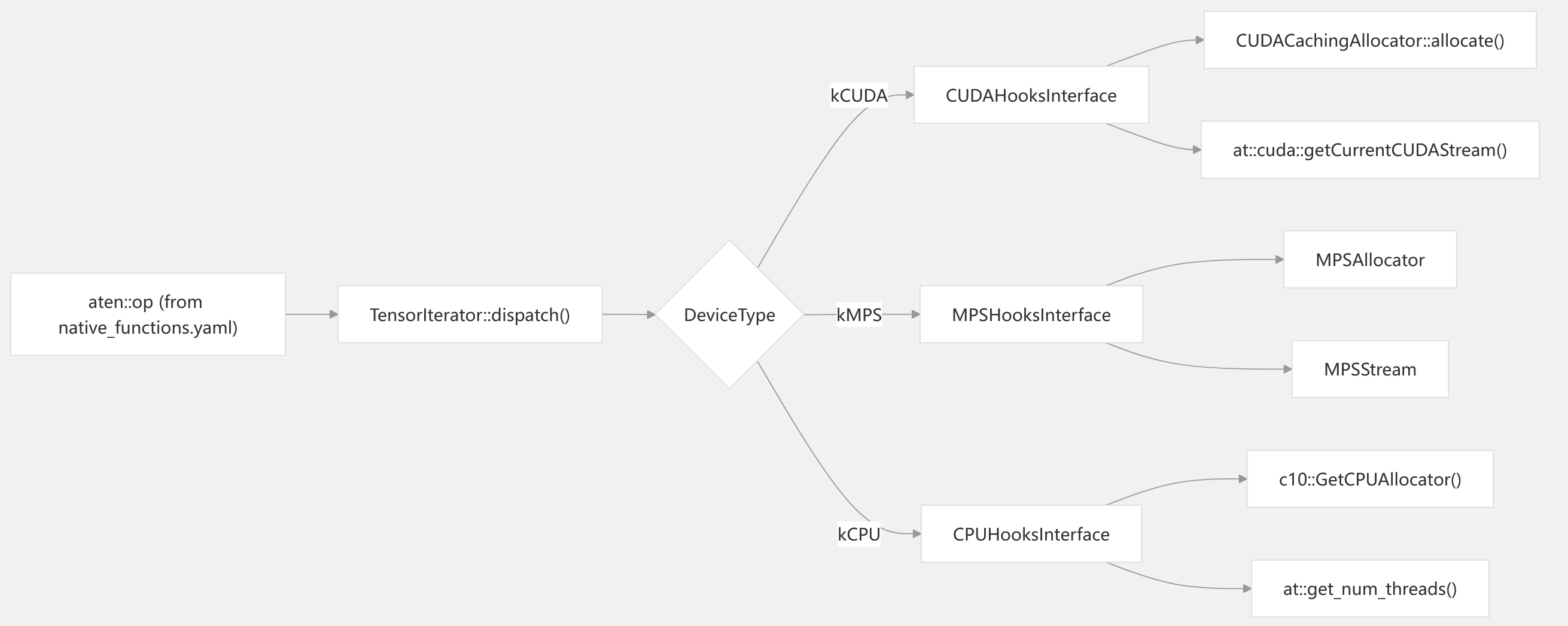
The dispatch system uses compile-time registration of backend hooks, and runtime selection based on the device type of the input tensors. The native_functions.yaml file specifies which operators are implemented for which backends, using dispatch keys such as “CPU”, “CUDA”, “MPS”, etc.
aten/src/ATen/native/native_functions.yaml1-100 aten/src/ATen/native/native_functions.yaml340-415 torch/csrc/cuda/Module.cpp60-110 torch/_dynamo/trace_rules.py150-240
CUDA Backend
The CUDA backend provides support for NVIDIA GPUs, including device management, memory allocation, stream/event handling, and kernel execution.
CUDA Backend Code Entities
torch/cuda/memory.py1-100 torch/csrc/cuda/Module.cpp1-100
c10/cuda/CUDACachingAllocator.cpp1-100
CUDA Memory Management
The CUDA backend uses CUDACachingAllocator to manage device memory. This allocator implements a block pool system to reduce the overhead of frequent cudaMalloc/cudaFree calls and supports stream-ordered allocation, memory statistics, and graph capture.
CUDA Memory Allocator Structure
c10/cuda/CUDACachingAllocator.cpp68-105
CUDA Device and Stream Management
The CUDA backend exposes device and stream management via both Python and C++ APIs.
| Functionality | Python API | C++ Implementation |
|---|---|---|
| Set device | torch.cuda.set_device() | THCPModule_setDevice_wrap |
| Get current device | torch.cuda.current_device() | THCPModule_getDevice_wrap |
| Stream management | torch.cuda.Stream | CUDAStream |
| Event management | torch.cuda.Event | CUDAEvent |
| Memory stats | torch.cuda.memory_allocated() | CUDACachingAllocator::currentMemoryAllocated |
torch/csrc/cuda/Module.cpp61-110 torch/cuda/memory.py1-100 test/test_cuda.py128-200
CUDA API Integration
The CUDA backend exposes device management and memory operations through both C++ and Python interfaces:
| Component | Python Interface | C++ Implementation |
|---|---|---|
| Device Management | torch.cuda.set_device() | THCPModule_setDevice_wrap |
| Memory Stats | torch.cuda.memory_allocated() | CUDACachingAllocator::currentMemoryAllocated |
| Stream Control | torch.cuda.Stream | CUDAStream |
| Event Synchronization | torch.cuda.Event | CUDAEvent |
The CUDA backend also provides utilities for error checking, device properties querying, and memory management:

CUDA Python API Structure
torch/csrc/cuda/Module.cpp61-110 torch/cuda/init.py150-250 test/test_cuda.py128-200
MPS Backend TODO
CPU Backend
The CPU backend provides execution for x86, ARM, and other general-purpose processors. It uses threading, vectorization, and integration with BLAS/LAPACK libraries for performance.
CPU Backend Code Entities
aten/src/ATen/native/native_functions.yaml1-100
CPU Optimization Strategies
| Optimization | Implementation | Configuration |
|---|---|---|
| Threading | OpenMP, TBB | at::get_num_threads() |
| Vectorization | AVX, NEON | Compile-time detection |
| BLAS Integration | MKL, OpenBLAS | at::BlasBackend |
| Memory Layout | Channels Last | torch.memory_format |
The CPU backend selects optimal implementations based on hardware features and input sizes.
aten/src/ATen/native/native_functions.yaml340-370
torch/_dynamo/variables/torch.py140-165
Linear Algebra Backend Integration
PyTorch integrates with multiple BLAS and LAPACK libraries for optimized linear algebra operations. The backend selection is deviceand configuration-dependent.
Linear Algebra Backend Selection
The backend is selected at runtime based on device type and available libraries. Users can configure the backend via torch.backends.blas.
aten/src/ATen/native/native_functions.yaml340-370
Backend Testing Infrastructure
PyTorch includes a comprehensive testing infrastructure to validate backend correctness and performance.
Backend Test Organization
Tests are parameterized to run across all supported backends. The MPS backend uses test modifiers to handle platform-specific limitations.
MPS Test Structure
test/test_cuda.py128-200 test/test_mps.py39-65 torch/testing/_internal/common_mps.py13-50
test/inductor/test_mps_basic.py35-50
Backend Memory Management
Each backend implements specialized memory management strategies optimized for their target hardware characteristics.
| Backend | Allocator | Key Features |
|---|---|---|
| CUDA | CUDACachingAllocator | Stream-ordered allocation, memory pools, graph capture support |
| MPS | MPSAllocator | Metal buffer management, unified memory integration |
| CPU | DefaultCPUAllocator | System malloc with alignment, pinned memory support |
The memory management system ensures efficient allocation patterns while providing debugging and profiling capabilities for performance optimization.
c10/cuda/CUDACachingAllocator.cpp126-250 torch/cuda/memory.py200-400