BLAS Library Selection
PyTorch provides mechanisms to select the preferred BLAS library at runtime, allowing users to choose between different implementations based on their workload characteristics.
BLAS Backend Selection
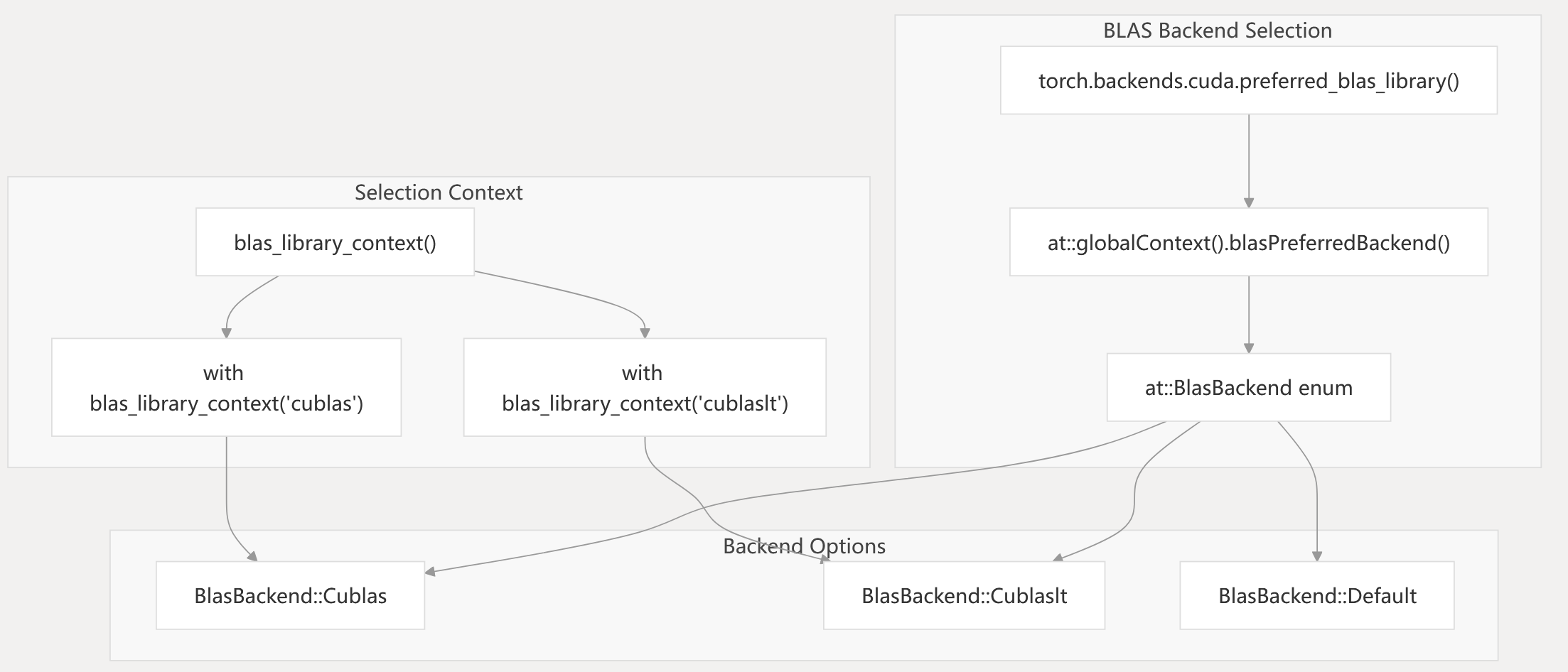
BLAS Backend Selection Process
The BLAS backend selection process allows users to choose between different BLAS libraries at runtime. The preferred_blas_library() function can be used to set the preferred backend, and the blas_library_context() context manager can be used to temporarily change the backend for a specific code block.
test/test_matmul_cuda.py65-72 aten/src/ATen/Context.cpp1000-1050
torch/backends/cuda/init.py1-100
Performance Considerations
When working with PyTorch’s linear algebra backends, several factors can significantly impact performance:
-
Data Type Selection:
- FP16/BF16 operations can be significantly faster on modern GPUs with tensor cores
- TF32 mode provides a good balance between precision and performance for FP32 operations
-
Memory Layout:
- Contiguous tensors generally perform better than strided ones
- Column-major layout may be more efficient for certain operations due to BLAS conventions
-
Batch Size Optimization:
- Using batched operations (bmm, baddbmm) is more efficient than loops of individual operations
- Very large batch sizes may require workspace size adjustments
-
Backend Selection:
- cuBLASLt/hipBLASLt generally perform better for operations supported by tensor cores
- Traditional cuBLAS/rocBLAS may be faster for small matrices or unusual shapes
-
Tuning System:
- Enable the tunable operations system for workloads with consistent matrix shapes
- Pre-tune operations during initialization to avoid runtime tuning overhead
test/test_matmul_cuda.py82-143 aten/src/ATen/cuda/CUDABlas.cpp387-437 torch/cuda/tunable.py1-298
Linear Algebra Backends
This page documents the linear algebra backend system in PyTorch, which provides high-performance implementations of matrix and vector operations (such as GEMM, GEMV, and batched GEMM) across supported hardware and BLAS libraries. The system includes backend selection, data type and precision management, and a tunable operations system for automatic performance optimization.
For details on how these backends are invoked from the compilation pipeline, see TorchInductor. For device-specific execution details, see Device Backends.
System Architecture
PyTorch’s linear algebra backend system is structured to provide a unified interface for tensor operations, while abstracting over hardware-specific and library-specific optimizations. The system routes high-level operations to the appropriate backend implementation, with support for runtime backend selection and autotuning.
Diagram: High-Level Operation Routing to Backend Code Entities
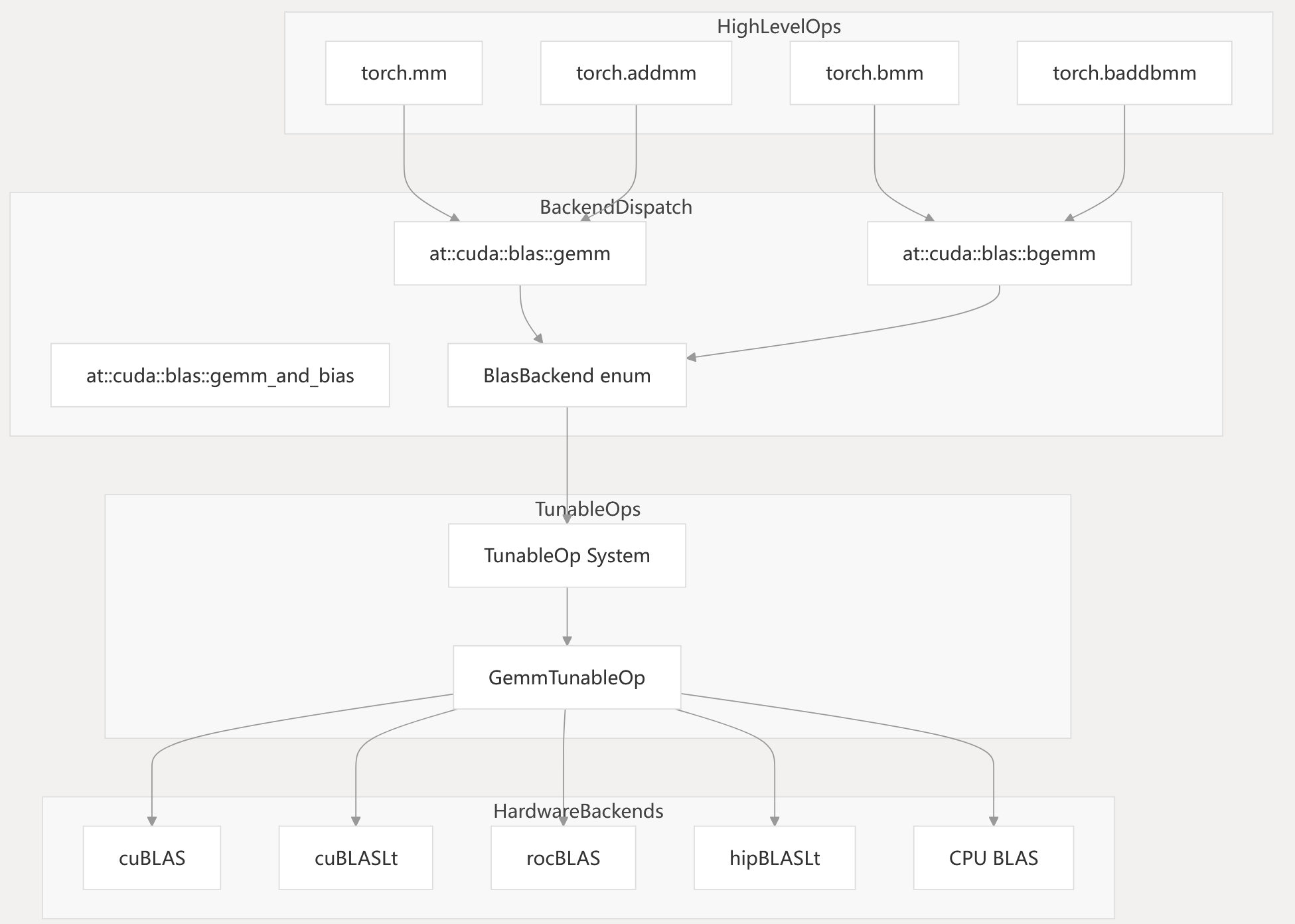
Key Code Entities:
at::cuda::blas::gemm,at::cuda::blas::bgemm,at::cuda::blas::gemm_and_bias: Core dispatch points for matrix operations (
aten/src/ATen/cuda/CUDABlas.h- aten/src/ATen/native/cuda/Blas.cpp).
BlasBackendenum: Represents backend choices (- aten/src/ATen/Context.cpp).
TunableOp System,GemmTunableOp: Tunable operation infrastructure (- aten/src/ATen/cuda/tunable/TunableGemm.h).
aten/src/ATen/native/cuda/Blas.cpp323-448 aten/src/ATen/cuda/CUDABlas.cpp367-563 aten/src/ATen/cuda/CUDABlas.h40-231 aten/src/ATen/cuda/tunable/TunableGemm.h29-239
Backend Implementation Layer
The core linear algebra operations are implemented through a template-based system that supports multiple data types and backend libraries.
Backend Implementation: CUDA and ROCm
The CUDA backend supports both cuBLAS and cuBLASLt libraries, with backend selection logic based on operation parameters, data types, and hardware capabilities. ROCm backends (rocBLAS, hipBLASLt) are supported on AMD GPUs.
Diagram: Backend Selection and Code Entities
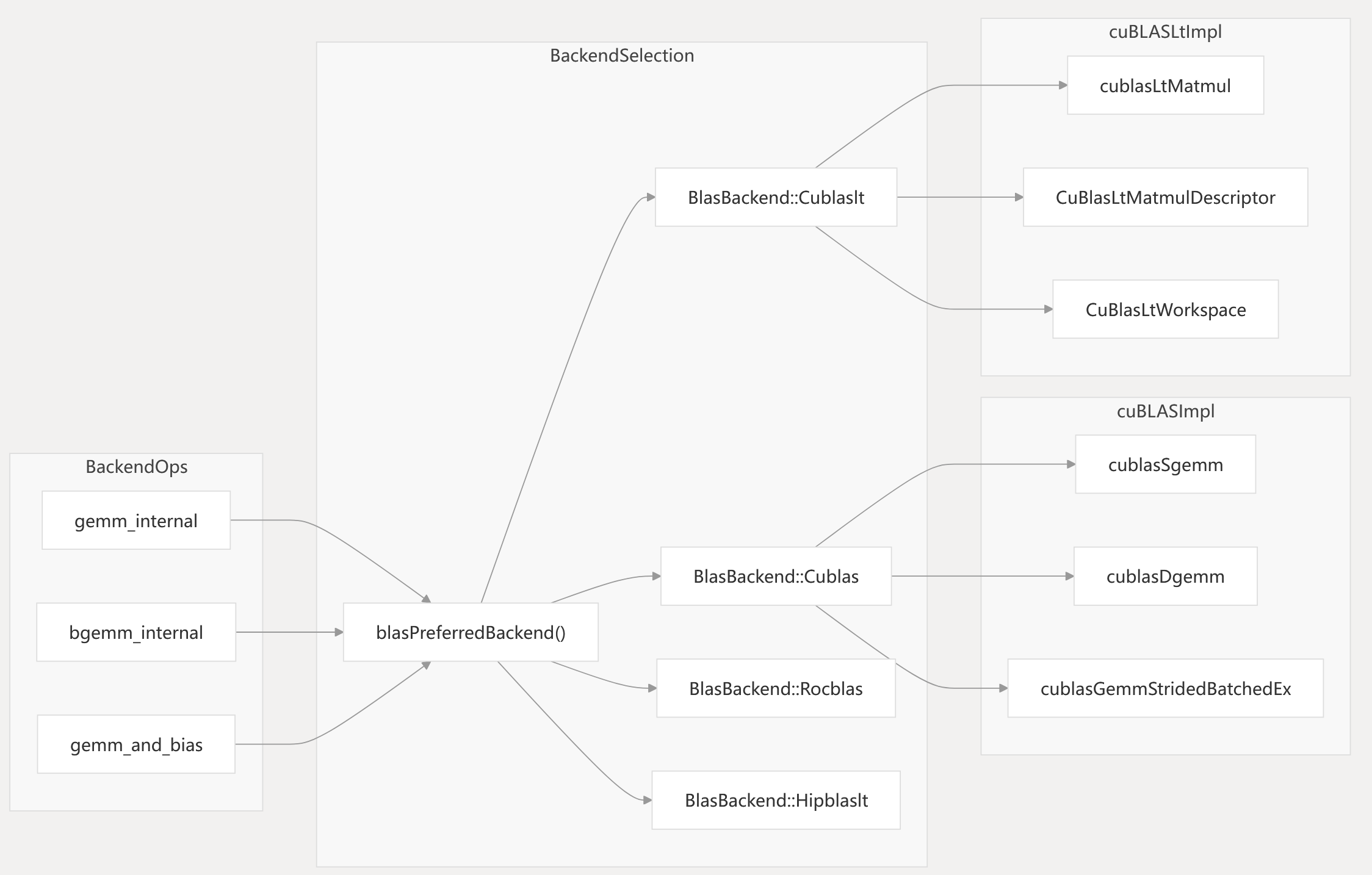
Key Code Entities:
cublasCommonArgs: Matrix preparation and transpose logic (- aten/src/ATen/native/cuda/Blas.cpp142-216).
bgemm_internal_cublaslt(),bgemm_internal_cublas(): Batched GEMM implementations (- aten/src/ATen/cuda/CUDABlas.cpp367-563).
CuBlasLtWorkspace: Workspace management for cuBLASLt (- aten/src/ATen/cuda/CUDABlas.cpp246-253).
aten/src/ATen/cuda/CUDABlas.cpp136-189 aten/src/ATen/cuda/CUDABlas.cpp367-563
aten/src/ATen/native/cuda/Blas.cpp142-216
Data Type and Precision Support
The linear algebra backends support a range of data types and precision modes, including mixed precision and hardware-specific formats.
| Data Type | cuBLAS | cuBLASLt | ROCm BLAS | hipBLASLt | Mixed Precision / Special Modes |
|---|---|---|---|---|---|
float | ✓ | ✓ | ✓ | ✓ | TF32 (Ampere+), FP32 |
double | ✓ | ✓ | ✓ | Limited | - |
at::Half | ✓ | ✓ | ✓ | ✓ | Accumulate in FP32 |
at::BFloat16 | ✓ | ✓ | ✓ | ✓ | Accumulate in FP32 |
c10::complex<float> | ✓ | ✓ | ✓ | Limited | - |
c10::complex<double> | ✓ | ✓ | ✓ | Limited | - |
float8 (experimental) | - | - | - | ✓ | - |
- TF32 is available on NVIDIA Ampere and later GPUs for FP32 inputs.
- Mixed precision: Half/BFloat16 inputs can use FP32 accumulation and output.
aten/src/ATen/cuda/CUDABlas.cpp387-437 aten/src/ATen/native/cuda/Blas.cpp360-402 aten/src/ATen/Context.cpp1000-1050
aten/src/ATen/cuda/tunable/GemmCommon.h106-215
Tunable Operations System
PyTorch provides a tunable operations system for linear algebra, which benchmarks and selects the fastest backend implementation for a given operation signature and input parameters. This system is especially relevant for GEMM and batched GEMM operations on ROCm and CUDA platforms.
Diagram: TunableOp System and Code Entities
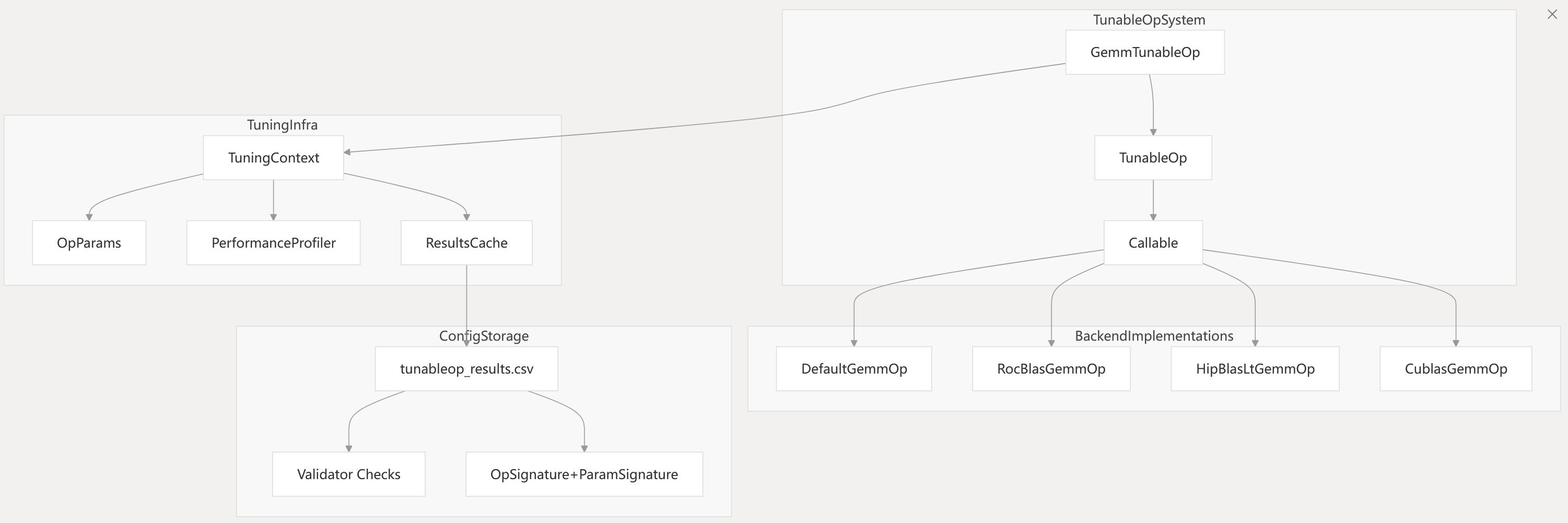
Key Code Entities:
GemmParams<T>: Encapsulates operation parameters (- aten/src/ATen/cuda/tunable/GemmCommon.h283-377).
TuningContext: Manages tuning and caching (- aten/src/ATen/cuda/tunable/TunableGemm.h210-239).
Callable<GemmParams<T>>: Interface for backend implementations (- aten/src/ATen/cuda/tunable/TunableGemm.h29-43).
aten/src/ATen/cuda/tunable/TunableGemm.h206-239 aten/src/ATen/cuda/tunable/GemmCommon.h31-377
Backend Registration and Environment Controls
The tunable operations system supports registration of multiple backend implementations, with selection and tuning controlled by environment variables and runtime APIs.
Diagram: Backend Registration and Environment Controls
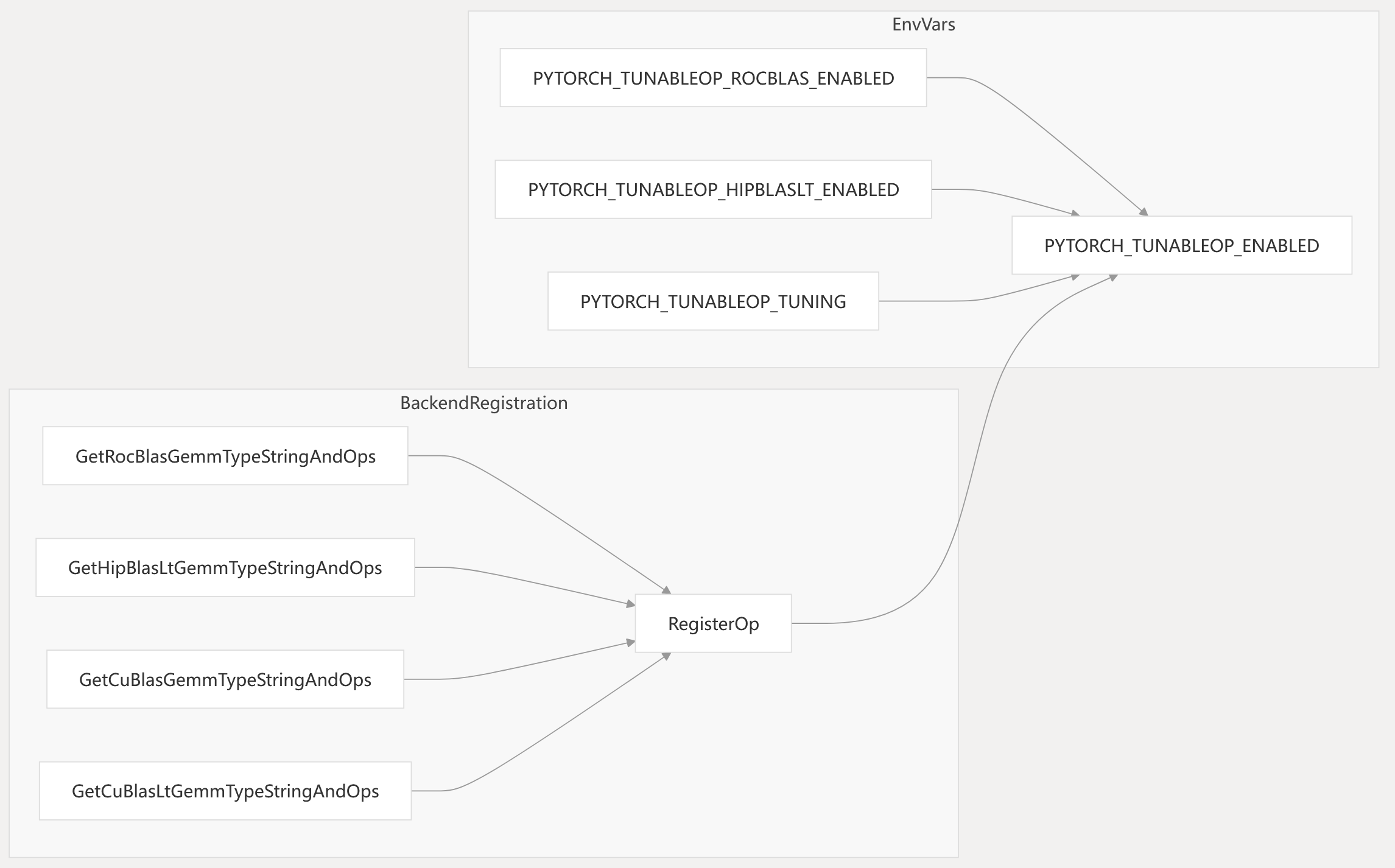
- Each backend provides a unique name and callable implementation.
- Environment variables control which backends are enabled and whether tuning is active.
aten/src/ATen/cuda/tunable/TunableGemm.h210-230 torch/cuda/tunable.py1-196
aten/src/ATen/cuda/tunable/GemmCommon.h31-375
Backend Selection Logic
Backend selection is performed dynamically based on hardware capabilities, operation parameters, and user or environment configuration.
Diagram: Backend Selection Decision Flow
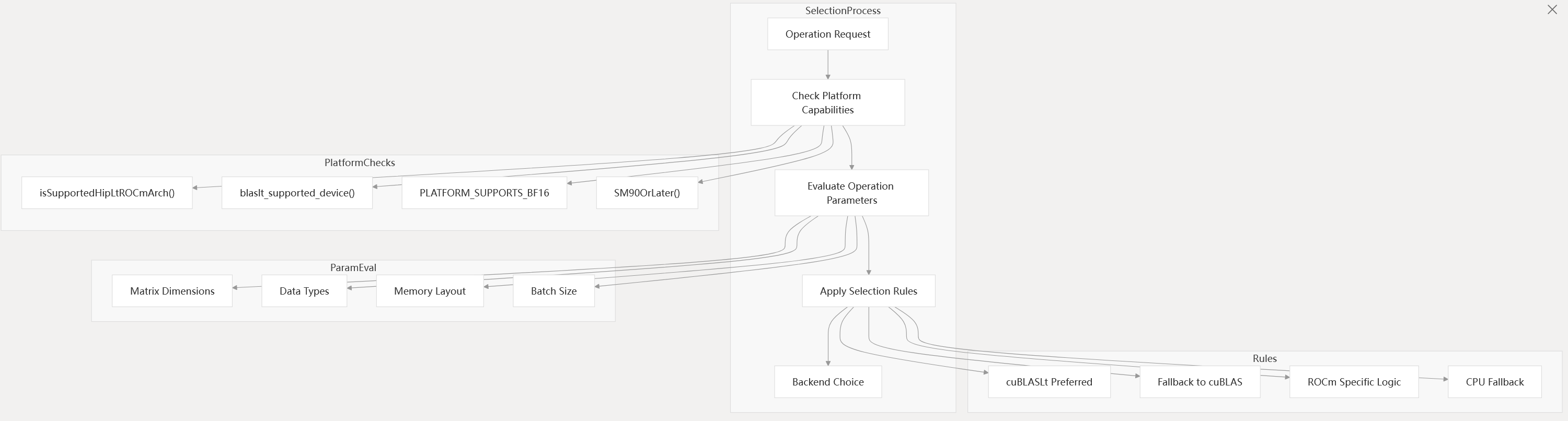
- The selection logic is implemented in
blasPreferredBackend()and related helpers. - Platform checks and parameter evaluation determine the optimal backend for each operation.
aten/src/ATen/native/cuda/Blas.cpp341-402 test/test_linalg.py55-70
torch/testing/_internal/common_cuda.py28-112
ROCm Backend Support
PyTorch supports AMD ROCm platforms with both rocBLAS and hipBLASLt libraries, including architecture-specific optimizations and mixed precision support.
rocblas_gemm_strided_batched_ex(): Used for advanced batched GEMM (- aten/src/ATen/cuda/CUDABlas.cpp650-660).
- Architecture detection and selection logic for supported GCN architectures (
- aten/src/ATen/cuda/CUDABlas.cpp19-65).
- Mixed precision and TF32-like modes for MI300 and newer.
- Integration with Composable Kernel (CK) for BFloat16 (
- aten/src/ATen/native/hip/ck_bgemm.h).
aten/src/ATen/cuda/CUDABlas.cpp19-65 aten/src/ATen/cuda/CUDABlas.cpp193-227 aten/src/ATen/cuda/CUDABlas.cpp647-660
Mixed Precision and Data Type Handling
The linear algebra backends support mixed precision computation, allowing lower-precision inputs (Half, BFloat16) to be accumulated in higher precision, and enabling special hardware modes such as TF32.
Diagram: Data Type and Precision Routing
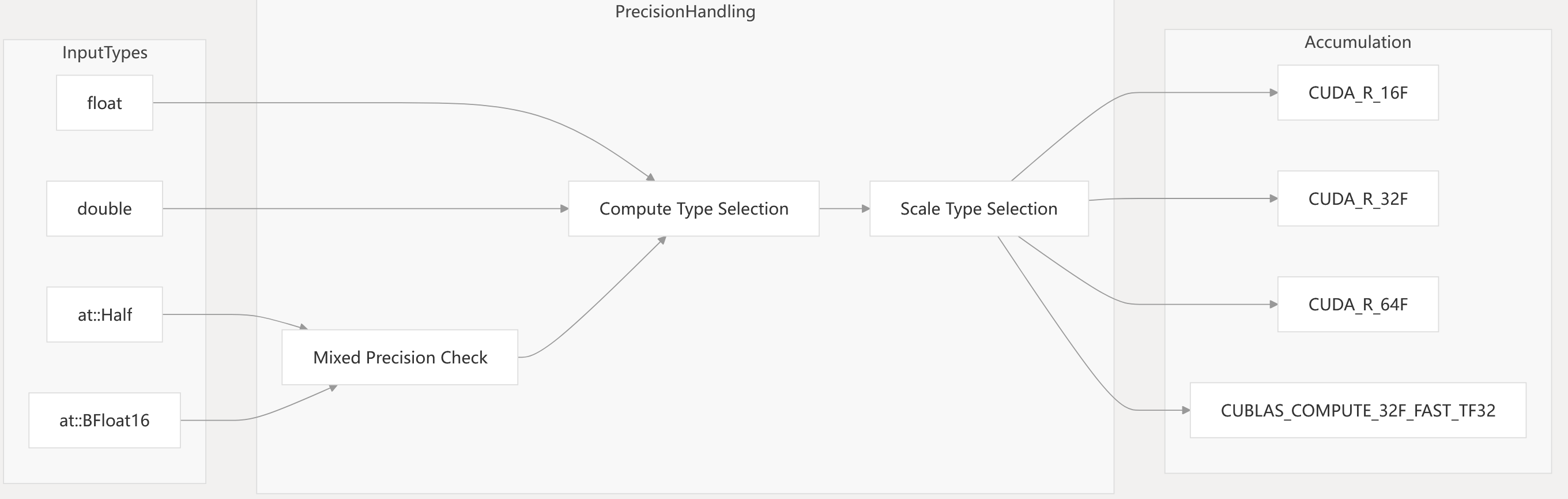
- Precision control flags:
allowFP16AccumulationCuBLAS(),allowBF16ReductionCuBLAS(),allowTF32CuBLAS(),setFloat32MatmulPrecision(). - TF32 is available for FP32 inputs on Ampere+ GPUs.
aten/src/ATen/cuda/CUDABlas.cpp387-437 aten/src/ATen/Context.cpp1000-1050
test/test_matmul_cuda.py82-143
Performance Optimization Features
Workspace and Memory Layout Management
CublasLtWorkspace: Manages temporary workspace for cuBLASLt (- aten/src/ATen/cuda/CUDABlas.cpp246-253).
getCUDABlasLtWorkspaceSize(): Workspace size is configurable via environment variables.- Memory layout optimization: Automatic detection of optimal layouts, stride analysis, and transpose logic.
Diagram: Memory Layout and Transpose Handling
![]()
Sources: aten/src/ATen/native/cuda/Blas.cpp142-216
aten/src/ATen/cuda/CUDABlas.cpp246-253
Fused Activation Epilogues
Modern BLAS libraries support fused activation functions in GEMM operations:
- Supported activations: None, ReLU, GELU (see
GEMMAndBiasActivationEpilogue). - Eliminates the need for separate activation kernel launches.
aten/src/ATen/cuda/CUDABlas.cpp235-266 aten/src/ATen/native/cuda/Blas.cpp136-189
aten/src/ATen/native/cuda/Blas.cpp246-258
Configuration and Environment Controls
The linear algebra backend system provides extensive configuration options through environment variables and runtime APIs.
Environment Variable Controls
| Variable | Default | Description |
|---|---|---|
PYTORCH_TUNABLEOP_ENABLED | 0 | Enable tunable operations |
PYTORCH_TUNABLEOP_TUNING | 1 | Enable performance tuning |
PYTORCH_TUNABLEOP_FILENAME | tunableop_results.csv | Tuning results file |
CUBLASLT_WORKSPACE_SIZE | 1024 (KB) | cuBLASLt workspace size |
DISABLE_ADDMM_CUDA_LT | 0 | Disable cuBLASLt for addmm |
PYTORCH_TUNABLEOP_ROCBLAS_ENABLED | 1 | Enable ROCm BLAS tuning |
PYTORCH_TUNABLEOP_HIPBLASLT_ENABLED | 1 | Enable hipBLASLt tuning |
Runtime Configuration APIs
Python Interface:
import torch.cuda.tunable as tunable
tunable.enable(True)
tunable.set_max_tuning_duration(30)
tunable.set_filename("custom_results.csv")
C++ Interface:
auto tuning_ctx = at::cuda::tunable::getTuningContext();
tuning_ctx->EnableTunableOp(true);
tuning_ctx->SetMaxTuningDuration(30.0);
torch/cuda/tunable.py177-298 aten/src/ATen/cuda/tunable/README.md135-150 aten/src/ATen/cuda/CUDABlas.cpp188-223