Integration with Dynamo and Compilation Pipeline
The CUDA backend is integrated with PyTorch’s compilation pipeline, including TorchDynamo and TorchInductor, to support tracing, graph extraction, and device-specific code generation.
Diagram: Dynamo and CUDA Backend Integration (Code Entities)

- Constant folding: Functions like
torch.cuda.is_available()are evaluated at trace time. - Guards: Device-dependent functions generate guards to ensure correctness.
- Context managers: CUDA context managers (e.g., autocast) are handled during tracing.
- Stream management: CUDA streams are tracked and managed in the graph.
torch/_dynamo/variables/torch.py torch/_dynamo/variables/ctx_manager.py
CUDA Graph Support
The CUDA backend supports CUDA Graphs for capturing and replaying GPU operation sequences, reducing CPU overhead.
Diagram: CUDA Graphs API and Memory Management (Code Entities)
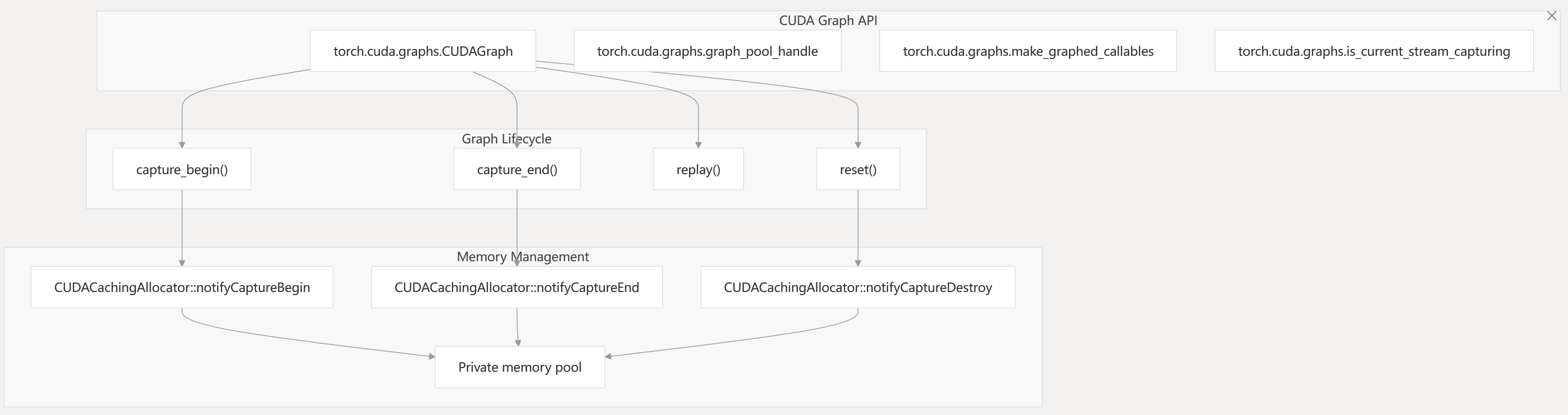
- CUDA Graphs use private memory pools to ensure address stability during capture and replay.
- The API supports wrapping Python callables, stream/event management, and graph reset.
torch/cuda/graphs.py c10/cuda/CUDACachingAllocator.cpp
CUDA Backend
This page documents the CUDA backend in PyTorch, which provides GPU acceleration for NVIDIA GPUs. The CUDA backend includes device management, memory allocation, kernel execution, stream/event handling, and integration with the rest of the PyTorch system.
For other device backends, see [3.2] (MPS Backend) and [3.3] (CPU Backend). For compilation and code generation targeting CUDA, see [2.2] (TorchInductor).
System Architecture
The CUDA backend is structured in several layers, each corresponding to specific code entities and files. The following diagram maps system components to code-level entities:
Diagram: CUDA Backend Layered Architecture and Code Entities
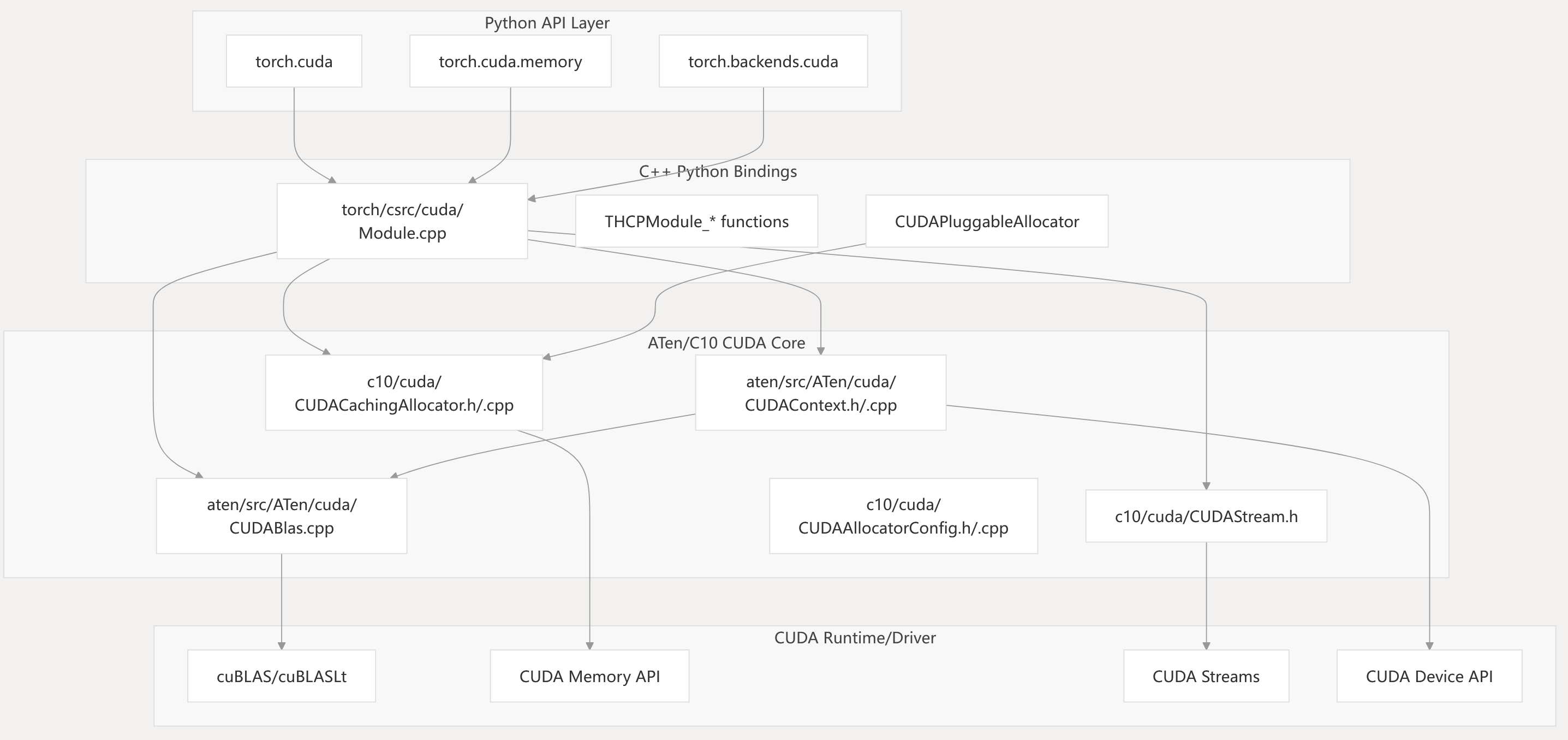
This diagram shows the mapping from high-level Python modules to C++ bindings and then to the ATen/C10 CUDA core, which interfaces with the CUDA runtime and driver APIs.
torch/cuda/init.py torch/cuda/memory.py torch/backends/cuda/init.py torch/csrc/cuda/Module.cpp aten/src/ATen/cuda/CUDAContext.h c10/cuda/CUDACachingAllocator.h c10/cuda/CUDAStream.h c10/cuda/CUDAAllocatorConfig.h
Memory Management System
The CUDA backend uses a caching allocator to efficiently manage device memory and reduce the overhead of frequent cudaMalloc and cudaFree calls.
Diagram: CUDACachingAllocator Structure and Code Entities
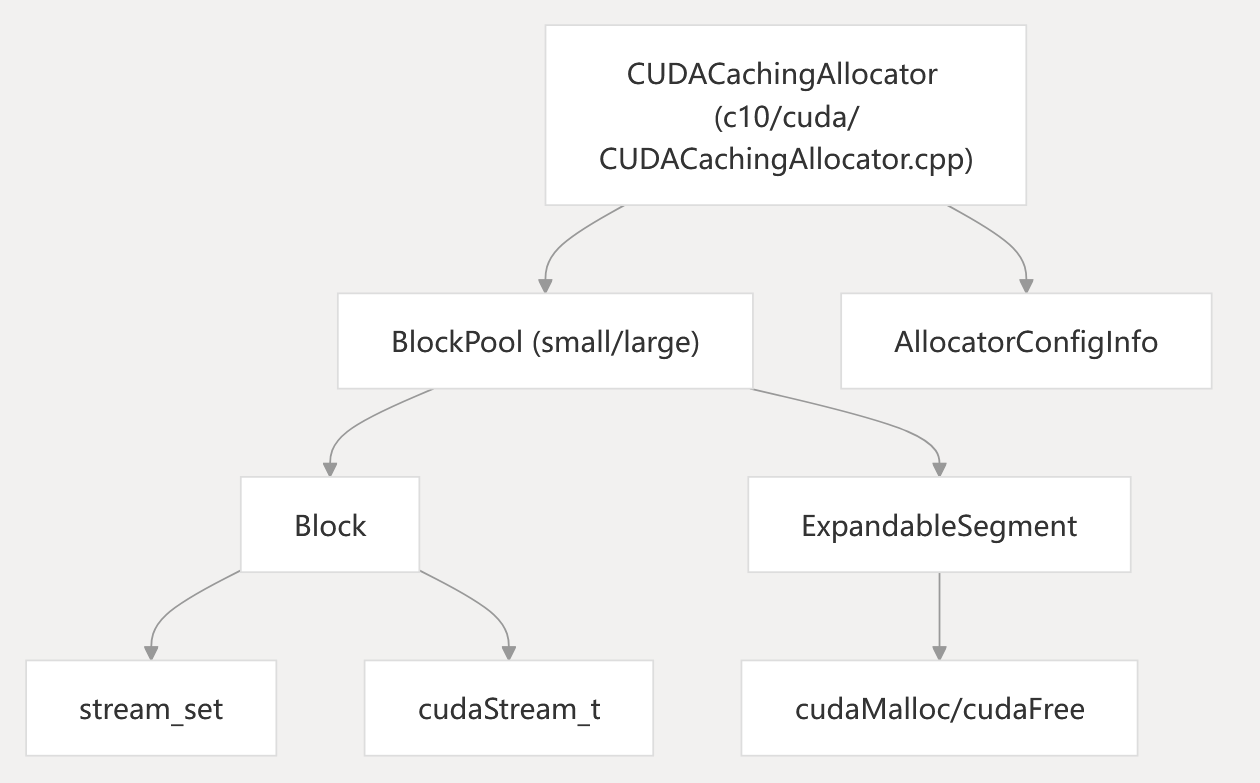
Key Concepts:
- Block: Represents a memory allocation unit, tracks size, stream, and usage.
- BlockPool: Pools for small (<1MB) and large (>=1MB) allocations.
- ExpandableSegment: Uses CUDA virtual memory APIs to allow large segments to grow, reducing fragmentation.
- stream_set: Tracks which CUDA streams have used a block, ensuring safe reuse.
- AllocatorConfigInfo: Stores allocator configuration and metadata.
Memory Allocation Flow:

The allocator attempts to reuse blocks from the pool. If none are available, it allocates new memory from the device. Out-of-memory handling includes freeing non-split blocks and, if necessary, raising an error.
c10/cuda/CUDACachingAllocator.cpp c10/cuda/CUDACachingAllocator.h
c10/cuda/CUDAAllocatorConfig.h
BLAS Integration
The CUDA backend integrates with cuBLAS and cuBLASLt for high-performance linear algebra operations.
Diagram: BLAS Operation Flow and Code Entities
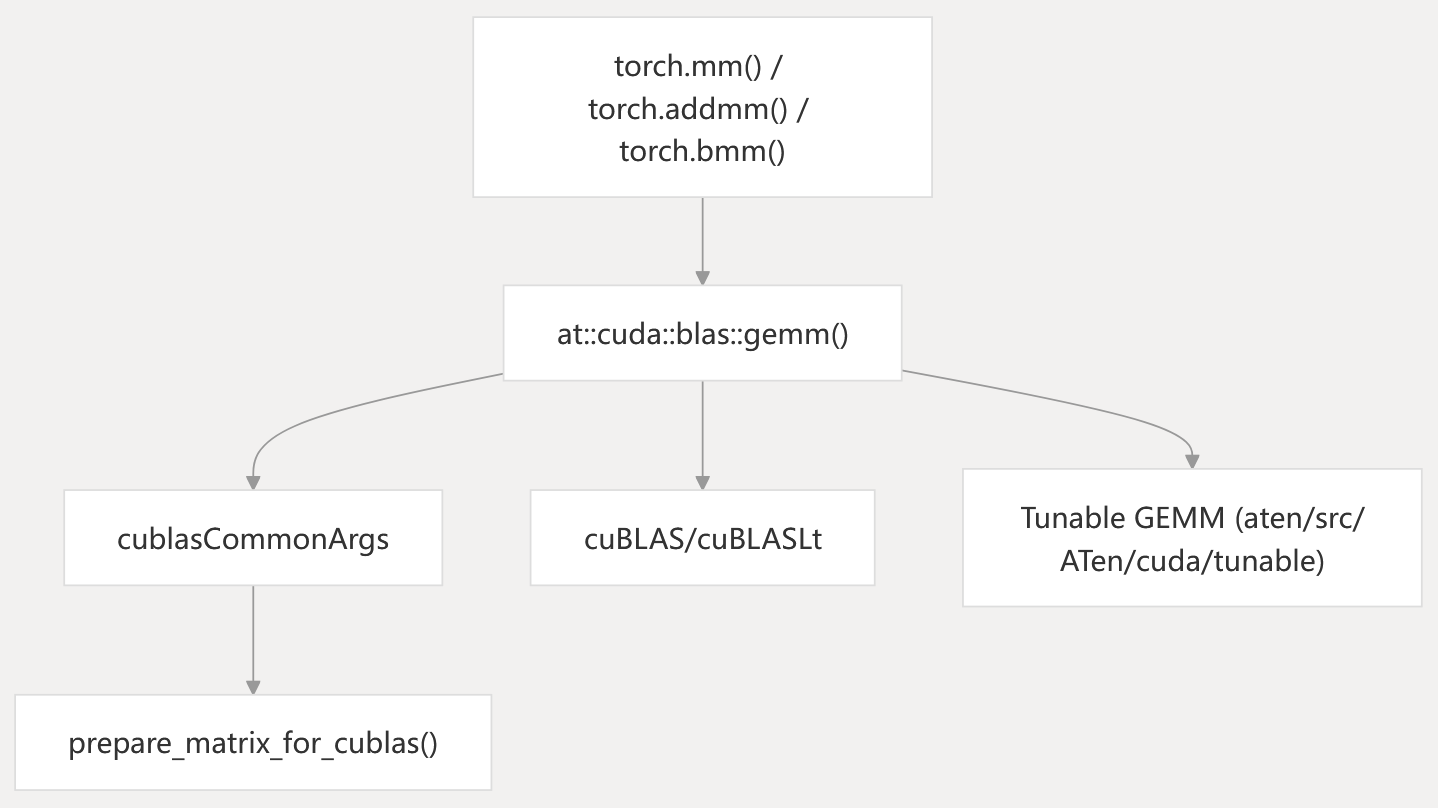
- High-level PyTorch functions (
torch.mm,torch.addmm,torch.bmm) call into ATen’s CUDA BLAS wrappers. cublasCommonArgsandprepare_matrix_for_cublas()handle tensor layout and parameter setup for cuBLAS/cuBLASLt.- Backend selection and tuning are handled in the tunable GEMM infrastructure.
Precision and Performance Controls

- Precision controls allow configuration of TF32, FP16, and BF16 modes.
- Backend selection can be controlled at runtime.
aten/src/ATen/cuda/CUDABlas.cpp aten/src/ATen/Context.cpp torch/backends/cuda/init.py
Device and Stream Management
The CUDA backend provides APIs for device selection, querying, and stream/event management.
Diagram: Device and Stream Management Code Entities
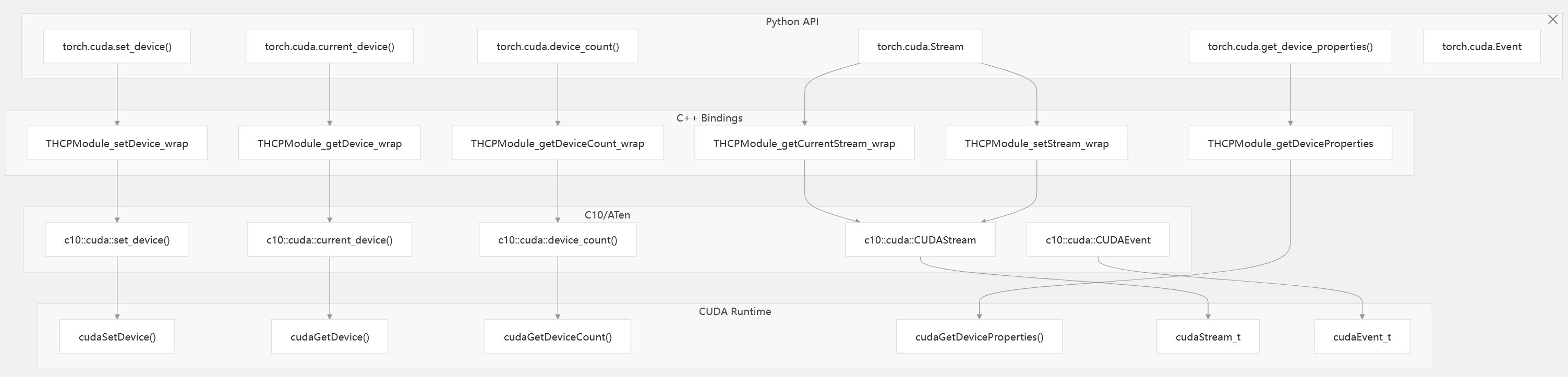
- Device management functions are exposed in Python and implemented in C++ bindings, which call into C10/ATen and the CUDA runtime.
- Stream and event management is handled by
torch.cuda.Stream,torch.cuda.Event, and their C++ counterparts.
torch/csrc/cuda/Module.cpp c10/cuda/CUDAStream.h torch/cuda/init.py
Performance Optimization: Tunable Operations
The CUDA backend includes a tunable operations system that benchmarks and selects the best-performing algorithm for each operation configuration.
Diagram: Tunable Operations System and Code Entities
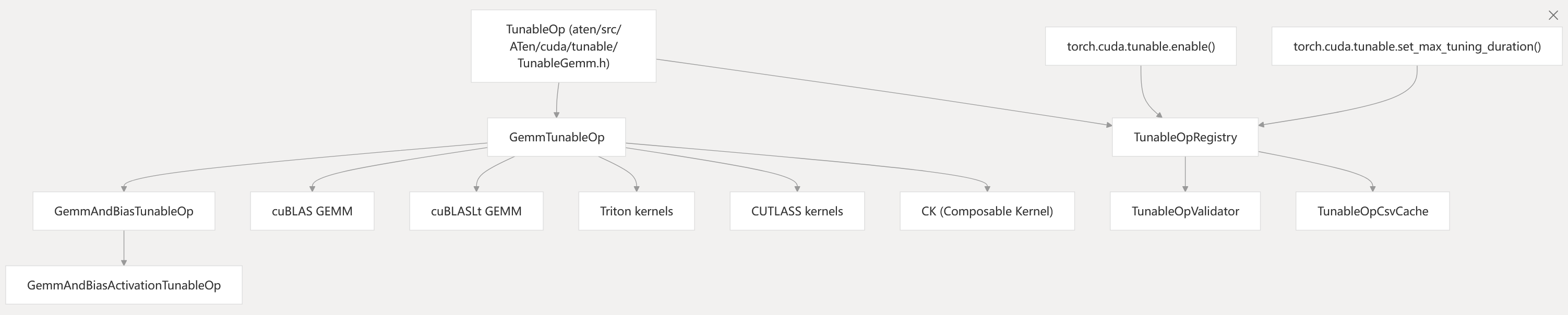
- The system benchmarks candidate algorithms (cuBLAS, cuBLASLt, Triton, CUTLASS, CK) and caches the best choice.
- Tuning can be controlled via Python APIs.
aten/src/ATen/cuda/tunable/TunableGemm.h aten/src/ATen/cuda/tunable/GemmCommon.h torch/cuda/tunable.py
Python Interface and Memory Management API
The Python interface exposes high-level CUDA functionality, including device management, memory statistics, and performance tuning.
Table: Key Python Modules and Functions
| Module | Purpose | Key Functions/Classes |
|---|---|---|
torch.cuda | Main CUDA interface | is_available(), device_count(), set_device(), Stream, Event |
torch.cuda.memory | Memory management | memory_allocated(), empty_cache(), memory_stats(), memory_snapshot() |
torch.backends.cuda | Backend configuration | preferred_blas_library(), matmul.allow_tf32 |
torch.cuda.tunable | Performance tuning | enable(), set_max_tuning_duration() |
torch.cuda.graphs | CUDA Graph support | CUDAGraph, make_graphed_callables() |
Diagram: Memory Management API and Code Entities

- The memory API provides statistics, cache management, and visualization tools for CUDA memory usage.
torch/cuda/init.py torch/cuda/memory.py torch/cuda/_memory_viz.py
Configuration and Environment
The CUDA backend supports extensive configuration through environment variables and runtime settings:
Key Configuration Options
PYTORCH_CUDA_ALLOC_CONF: Memory allocator configurationCUDA_LAUNCH_BLOCKING: Synchronous execution for debuggingPYTORCH_NVML_BASED_CUDA_CHECK: Alternative CUDA availability checkTORCH_BLAS_PREFER_CUBLASLT: Prefer cuBLASLt over cuBLAS
Runtime Controls
- Device memory fraction limits
- Workspace size configuration for cuBLAS operations
- Deterministic algorithm enforcement
- TF32 precision controls
c10/cuda/CUDAAllocatorConfig.cpp1-50 torch/cuda/init.py160-200 aten/src/ATen/Context.cpp200-250