MPI:https://mpitutorial.com/tutorials/
介绍
MPI(Message Passing Interface,消息传递接口)为在分布式内存架构下的进程间通信提供了规范和库支持。在程序的角度,MPI 就是一系列函数接口,他们可以实现不同进程(不同内存区域)之间的消息传递
- 适用场景:分布式内存并行模型
MPI 编程模型
- 分布式内存模型
在分布式内存模型中,各个处理节点可以独立运行自己的进程,使用自己的本地内存来存储和处理数据。每个进程的内存是私有的,其他进程无法直接访问它们。如果一个进程需要访问另一个进程的数据,就必须通过显式的消息传递机制将数据从一个进程发送到另一个进程。同一个节点(服务器)内部需要借助高速数据总线等硬件实现,而跨节点的通信通常由网络连接来实现,比如通过高速以太网、IB(InfiniBand)等。
- MPI 的核心概念
- 进程: 在 MPI 中,每个计算任务由一个或多个进程执行。进程是独立的计算实体,有自己的内存空间。MPI 程序通常启动多个进程,这些进程在分布式内存系统中运行。
- 通信: MPI 通过消息传递的方式进行进程间通信。主要有两种通信方式:
- 点对点通信(Point-to-Point Communication): 两个进程之间直接传递消息。例如,进程 A 发送数据给进程 B。
- 集体通信(Collective Communication): 多个进程之间进行数据传递或同步操作。例如,广播(broadcast)、归约(reduce)等操作。
- 通信协议: MPI 提供了多种通信协议,如阻塞通信(Blocking)、非阻塞通信(Non-blocking)、同步通信(Synchronous)等。
API
- 初始化与终止
MPI_Init:初始化 MPI 环境,必须在任何 MPI 调用之前调用。MPI_Init(&argc, &argv);在 MPI_Init 的过程中,所有 MPI 的全局变量或者内部变量都会被创建。一个通讯子(communicator)会根据所有可用的进程被创建出来,然后每个进程会被分配独一无二的秩(rank)MPI_Finalize:结束 MPI 环境,释放 MPI 使用的资源。 `MPI_Finalize();
- 获取进程信息
MPI_Comm_size:获取通信子(communicator)中进程的总数。 `int world_size; MPI_Comm_size(MPI_COMM_WORLD, &world_size);MPI_Comm_rank:获取当前进程在通信子中的编号(从 0 开始)。int world_rank; MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
- 点对点通信
MPI_Send:发送消息到指定的进程。MPI_Recv:接收来自指定进程的消息。
- 集合通信
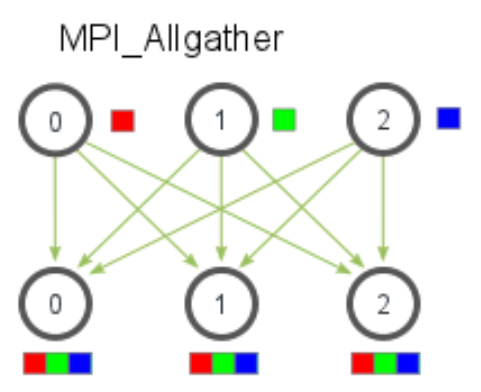
MPI_Bcast:将一条消息从一个进程广播到通信子中的所有进程。MPI_Scatter:将根进程的数据分散(scatter)到所有进程中。每个进程接收根进程提供的数据的一部分。MPI_Reduce:对来自所有进程的数据进行归约操作(如求和、求最小值),并将结果发送到根进程。MPI_Gather:将各进程的数据收集到根进程中。MPI_Allgather:将所有进程的部分数据汇总到所有进程。每个进程在所有进程中接收到所有其他进程的数据。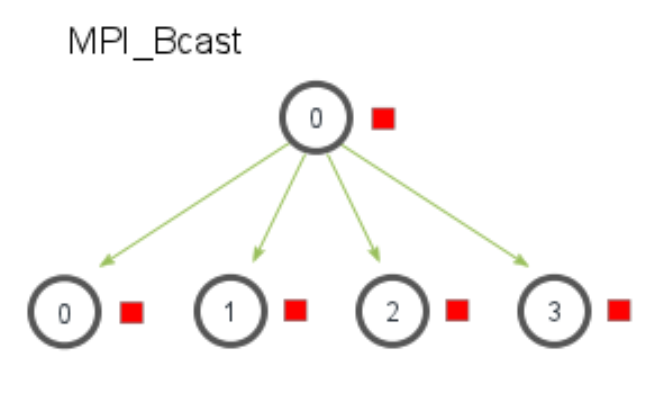
MPI 中的同步与异步通信
- 阻塞通信 vs. 非阻塞通信
- 阻塞通信是指在通信操作完成之前,调用该通信函数的进程会被阻塞(即等待)。这意味着在通信操作完成之前,进程无法继续执行后续的操作。这种通信方法实现较为简单,但是可能会导致进程等待,特别是在进行大量通信操作时影响性能。适用于简单的通信场景。
- 非阻塞通信允许进程在发送或接收数据的同时继续执行其他计算任务。通信操作的完成会在稍后的时间自动进行,可以与计算任务重叠,提高性能,但是编程复杂度较高,需要显式检查通信完成状态。
阻塞通信:
MPI_SendMPI_Recv非阻塞通信:MPI_Isend非阻塞地发送数据。MPI_Irecv非阻塞地接收数据。MPI_Wait用于确保非阻塞操作完成之后再继续执行后续代码。
MPI 中的数据类型与通讯域/通信子/通讯器:
MPI_Datatype:MPI 提供了内置和自定义数据类型,用于定义数据的格式和结构。自定义数据类型允许更复杂的数据组织和传输。MPI_Comm:MPI 中的通信域定义了进程的集合,这些进程可以在同一通信域内进行数据交换。MPI 提供了默认通信域和创建自定义通信域的功能,以支持不同的并行计算模式和需求。
API
MPI(Message Passing Interface)是并行计算中最流行的编程模型之一,以下是需要掌握的核心概念:
1. 进程模型(Process Model)
- 并行方式:基于多进程(而非多线程)的分布式内存模型。
- 进程独立性:每个进程有独立的内存空间,需通过消息传递交换数据。
- 启动方式:使用
mpiexec -n 8./program启动 8 个进程实例。
2. 通信器(Communicator)
- 定义:进程组的抽象,隔离通信范围。
- 预定义通信器:
MPI_COMM_WORLD:包含所有进程。MPI_COMM_SELF:仅包含当前进程。- 自定义通信器:通过
MPI_Comm_split创建子进程组。
3. 进程标识(Rank & Size)
- Rank:进程在通信器中的唯一编号(从 0 开始)。
- Size:通信器中的进程总数。
- 核心 API:
MPI_Comm_rank(comm, &rank); // 获取当前进程rank
MPI_Comm_size(comm, &size); // 获取通信器size
4. 点到点通信(Point-to-Point)
- 阻塞通信:
MPI_Send(buffer, count, datatype, dest, tag, comm);
MPI_Recv(buffer, count, datatype, source, tag, comm, status);
- 非阻塞通信:
MPI_Isend(buffer, count, datatype, dest, tag, comm, &request);
MPI_Irecv(buffer, count, datatype, source, tag, comm, &request);
MPI_Wait(&request, status); // 等待完成
- 关键参数:
tag用于区分不同类型的消息,status包含接收消息的元信息。
5. 集体通信(Collective Communication)
- 广播(Broadcast):从一个进程发送数据到所有进程。
MPI_Bcast(buffer, count, datatype, root, comm);
- 归约(Reduce):将所有进程的数据聚合到一个进程。
MPI_Reduce(sendbuf, recvbuf, count, datatype, op, root, comm);
// op 可以是 MPI_SUM, MPI_MAX, MPI_MIN 等
- 散射(Scatter):将根进程的数据分发给所有进程。
- 收集(Gather):将所有进程的数据收集到根进程。
- 全归约(Allreduce):聚合数据并将结果分发给所有进程。
- 同步(Barrier):所有进程等待直到全部到达。
6. 同步机制
- 阻塞同步:
MPI_Barrier(comm); // 所有进程在此等待
- 非阻塞同步:通过
MPI_Test检查请求是否完成。
7. 数据类型(Datatype)
- 基本类型:
MPI_INT,MPI_FLOAT,MPI_DOUBLE等。 - 自定义类型:通过
MPI_Type_create_struct定义复杂数据结构。 - 示例:发送结构体数组时需先注册自定义类型。
8. 通信模式
- 标准模式:
MPI_Send可能缓冲或直接发送。 - 缓冲模式:
MPI_Bsend使用用户提供的缓冲区。 - 同步模式:
MPI_Ssend仅在接收方开始接收后返回。 - 就绪模式:
MPI_Rsend要求接收方已准备好。
9. 拓扑结构(Topology)
- 定义:为进程组定义逻辑结构(如网格、环)。
- 笛卡尔拓扑:
int dims[2] = {2, 2}; // 2x2网格
int periods[2] = {1, 1}; // 周期性边界
MPI_Cart_create(comm, 2, dims, periods, 0, &newcomm);
- 应用:优化近邻通信(如有限元计算)。
10. 错误处理
- 错误代码:MPI 函数返回错误码(如
MPI_SUCCESS)。 - 错误处理程序:
MPI_Comm_set_errhandler(comm, MPI_ERRORS_RETURN); // 返回错误码而非终止
- 调试工具:使用
mpiexec --mca btl self,tcp禁用某些网络组件辅助调试。
11. 性能优化
- 减少通信:合并小消息,避免频繁同步。
- 非阻塞通信:重叠计算与通信。
- 聚合操作:使用
MPI_Allreduce替代多次发送接收。
关键 API 速查表
| 功能 | 函数 |
| ------- | -------------------------------- |
| 初始化 | MPI_Init(&argc, &argv) |
| 结束 | MPI_Finalize() |
| 点到点发送 | MPI_Send, MPI_Isend |
| 点到点接收 | MPI_Recv, MPI_Irecv |
| 广播 | MPI_Bcast |
| 归约 | MPI_Reduce, MPI_Allreduce |
| 散射 / 收集 | MPI_Scatter, MPI_Gather |
| 同步 | MPI_Barrier |
| 获取进程信息 | MPI_Comm_rank, MPI_Comm_size |
典型应用场景
- 科学计算:流体力学、气候模拟。
- 机器学习:数据并行训练(如分布式 SGD)。
- 数据分析:大规模数据集的并行处理。
Rank Size
在 MPI(Message Passing Interface)编程中,comm、rank 和 size 是三个核心概念,用于实现并行计算中的进程管理和通信:
1. MPI_Comm(通信器,Communicator)
- 定义:一个进程组和上下文的抽象,用于界定通信范围。
- 作用:
- 划分不同的进程组(例如,将 16 个进程分为两个独立的 8 进程组)。
- 隔离通信,避免不同任务间的干扰。
- 示例:
MPI_Comm world = MPI_COMM_WORLD; // 默认包含所有进程的通信器
- 常见预定义通信器:
MPI_COMM_WORLD:包含所有 MPI 进程。MPI_COMM_SELF:仅包含当前进程自身。
2. rank(进程编号)
- 定义:进程在通信器中的唯一整数标识符(从 0 开始)。
- 作用:
- 标识消息的发送者和接收者。
- 决定进程在并行算法中的角色(例如,rank 0 通常作为主进程)。
- 获取方式:
int rank;
MPI_Comm_rank(MPI_COMM_WORLD, &rank); // 获取当前进程在WORLD中的编号
- 示例:
- 若启动 4 个进程,rank 依次为 0、1、2、3。
3. size(进程数量)
- 定义:通信器中的进程总数。
- 作用:
- 确定并行度(例如,将数据分为
size份)。 - 判断进程是否为最后一个(例如,
rank == size-1)。 - 获取方式:
int size;
MPI_Comm_size(MPI_COMM_WORLD, &size); // 获取WORLD中的进程总数
- 示例:
- 若使用
mpiexec -n 8启动 8 个进程,则size = 8。
三者关系示例
假设启动 4 个进程(size = 4),各进程的 rank 如下:
|进程编号(rank)|执行代码示例(伪代码)|
|---|---|
|0|if (rank == 0) { 发送数据给其他进程 }|
|1|if (rank == 1) { 接收数据并处理 }|
|2|// 进程2的特定任务|
|3|result = data[rank] * 10;|
关键 API 总结
| 函数 | 作用 |
| ---------------------- | --------------- |
| MPI_Comm_rank | 获取当前进程的 rank |
| MPI_Comm_size | 获取通信器的 size |
| MPI_Comm_split | 创建新的通信器 |
| MPI_Send/MPI_Recv | 基于 rank 进行点对点通信 |
| MPI_Bcast/MPI_Reduce | 基于通信器进行集体通信 |
常见应用场景
- 主从模式(Master-Slave):
- rank 0 作为主进程分配任务,其他 rank 作为从进程执行计算。
- 数据并行:
- 将数据分为
size份,每个 rank 处理其中一份。
- 任务并行:
- 不同 rank 执行不同类型的任务(例如,rank 0 负责 I/O,其他 rank 负责计算)。
注意事项
- 通信器隔离:在不同通信器中,同一物理进程的 rank 可能不同。
- 集体操作要求:集体通信(如
MPI_Bcast)必须被通信器内的所有进程调用。 - 错误示例:
// 错误:向不存在的rank发送消息
if (rank == 0) {
MPI_Send(data, count, MPI_INT, 10, tag, MPI_COMM_WORLD); // 若size=4,rank 10不存在
}
理解 comm、rank 和 size 是 MPI 编程的基础,它们共同构建了并行计算中的进程拓扑和通信规则。
信息传递标准
MPI(Message Passing Interface)是高性能计算中常用的消息传递标准,下面是几个核心通信 API 的功能和区别:
1. 点对点通信
MPI_Send 和 MPI_Isend
- 功能:从一个进程向另一个进程发送消息
- 区别:
MPI_Send(阻塞发送):
发送进程会被阻塞,直到系统确认消息已被安全传输(可能在接收缓冲区或网络中)。
MPI_Isend(非阻塞发送):
立即返回控制权,允许发送进程继续执行其他任务。需配合 MPI_Wait 或 MPI_Test 确认完成。
MPI_Recv 和 MPI_Irecv
- 功能:从指定进程接收消息
- 区别:
MPI_Recv(阻塞接收):
接收进程会被阻塞,直到接收到匹配的消息。
MPI_Irecv(非阻塞接收):
立即返回控制权,允许接收进程继续执行其他任务。需后续调用 MPI_Wait 或 MPI_Test 获取数据。
2. 广播通信
MPI_Bcast
- 功能:从一个根进程向所有进程(包括自身)发送相同的数据
- 流程:
- 根进程准备数据
- 调用
MPI_Bcast广播数据 - 所有进程(包括根进程)接收到相同数据
- 示例场景:
分发配置参数、初始条件或全局指令。
3. 归约操作
MPI_Reduce 和 MPI_Allreduce
- 功能:将所有进程的数据汇总并执行指定操作(如求和、求最大值等)
- 区别:
MPI_Reduce:
结果只返回给根进程。
例如:所有进程计算部分和,最终由根进程汇总得到总和。
MPI_Allreduce:
结果返回给所有进程。
例如:所有进程需要知道全局最大值。
- 支持的操作:
MPI_SUM, MPI_PROD, MPI_MAX, MPI_MIN, 等。
4. 数据分发与收集
MPI_Scatter 和 MPI_Gather
- 功能:
MPI_Scatter:
根进程将数组分割并分发给所有进程(包括自身)。
例如:根进程有一个包含 100 个元素的数组,8 个进程各自接收 12 或 13 个元素。
MPI_Gather:
所有进程将各自的数据发送给根进程,合并成完整数组。
例如:各进程计算部分结果,根进程收集所有结果。
- 特点:
数据量必须能被进程数整除,否则需使用 MPI_Scatterv 和 MPI_Gatherv。
5. 同步操作
MPI_Barrier
- 功能:
所有进程在此处等待,直到所有进程都到达此点后,才继续执行后续代码。
- 用途:
- 确保数据一致性(如所有进程完成初始化)
- 避免竞态条件(如读写共享资源前)
- 注意:
过度使用会导致性能下降,应谨慎使用。
总结对比表
|API|通信模式|阻塞特性|数据流向|典型应用场景|
|---|---|---|---|---|
|MPI_Send|点对点|阻塞|单发送者 → 单接收者|任务分配、结果返回|
|MPI_Isend|点对点|非阻塞|单发送者 → 单接收者|重叠计算与通信|
|MPI_Bcast|一对多|阻塞|根进程 → 所有进程|分发配置参数、初始条件|
|MPI_Reduce|多对一|阻塞|所有进程 → 根进程|全局求和、最大值计算|
|MPI_Allreduce|多对多|阻塞|所有进程 → 所有进程|同步计算结果、归一化处理|
|MPI_Scatter|一对多|阻塞|根进程 → 所有进程(分割数据)|数据并行计算|
|MPI_Gather|多对一|阻塞|所有进程 → 根进程(合并数据)|结果收集|
|MPI_Barrier|全局|阻塞|无数据传输,仅同步时间点|确保所有进程完成特定阶段|
使用建议
- 阻塞 vs 非阻塞:
- 优先使用阻塞操作(代码简单)
- 性能敏感场景使用非阻塞操作(重叠计算与通信)
- 集体通信优化:
- 集体操作(如
MPI_Allreduce)通常比多次点对点通信更高效 - 数据量较大时,优先选择
MPI_Allreduce而非MPI_Reduce + MPI_Bcast
- 避免死锁:
- 确保
MPI_Send和MPI_Recv成对出现 - 使用非阻塞操作时,必须调用
MPI_Wait或MPI_Test
- 同步点控制:
- 尽量减少
MPI_Barrier的使用,避免全局等待
API 使用
以下是 MPI 核心通信函数的参数详细说明,按功能分类整理:
一、点对点通信函数
1. MPI_Send
int MPI_Send(
const void *buf, // 发送缓冲区地址
int count, // 发送的数据项数量
MPI_Datatype datatype,// 数据类型(如 MPI_INT, MPI_DOUBLE)
int dest, // 目标进程的rank
int tag, // 消息标签(用于匹配发送和接收)
MPI_Comm comm // 通信域
);
2. MPI_Isend
int MPI_Isend(
const void *buf, // 发送缓冲区地址
int count, // 发送的数据项数量
MPI_Datatype datatype,// 数据类型
int dest, // 目标进程rank
int tag, // 消息标签
MPI_Comm comm, // 通信域
MPI_Request *request // 用于跟踪通信状态的请求句柄
);
- 非阻塞特性:返回时通信可能未完成,需用
MPI_Wait或MPI_Test确认。
3. MPI_Recv
int MPI_Recv(
void *buf, // 接收缓冲区地址
int count, // 最大接收的数据项数量
MPI_Datatype datatype,// 数据类型
int source, // 源进程rank(MPI_ANY_SOURCE 表示任意源)
int tag, // 消息标签(MPI_ANY_TAG 表示任意标签)
MPI_Comm comm, // 通信域
MPI_Status *status // 接收状态信息(包含实际接收的数据量等)
);
4. MPI_Irecv
int MPI_Irecv(
void *buf, // 接收缓冲区地址
int count, // 最大接收数量
MPI_Datatype datatype,// 数据类型
int source, // 源进程rank
int tag, // 消息标签
MPI_Comm comm, // 通信域
MPI_Request *request // 用于跟踪通信状态的请求句柄
);
二、广播函数
MPI_Bcast
int MPI_Bcast(
void *buf, // 根进程:发送缓冲区;其他进程:接收缓冲区
int count, // 数据项数量
MPI_Datatype datatype,// 数据类型
int root, // 根进程rank
MPI_Comm comm // 通信域
);
- 工作机制:
根进程的数据被复制到所有进程(包括根进程自身)的接收缓冲区。
三、归约函数
1. MPI_Reduce
int MPI_Reduce(
const void *sendbuf, // 发送缓冲区地址
void *recvbuf, // 接收缓冲区地址(仅根进程有效)
int count, // 数据项数量
MPI_Datatype datatype,// 数据类型
MPI_Op op, // 归约操作(如 MPI_SUM, MPI_MAX)
int root, // 根进程rank
MPI_Comm comm // 通信域
);
- 常用归约操作:
MPI_SUM, MPI_PROD, MPI_MAX, MPI_MIN, MPI_MAXLOC, MPI_MINLOC 等。
2. MPI_Allreduce
int MPI_Allreduce(
const void *sendbuf, // 发送缓冲区地址
void *recvbuf, // 接收缓冲区地址(所有进程都接收结果)
int count, // 数据项数量
MPI_Datatype datatype,// 数据类型
MPI_Op op, // 归约操作
MPI_Comm comm // 通信域
);
- 与
MPI_Reduce的区别:
结果会广播到所有进程,相当于 MPI_Reduce + MPI_Bcast 的组合。
四、数据分发与收集函数
1. MPI_Scatter
int MPI_Scatter(
const void *sendbuf, // 根进程的发送缓冲区
int sendcount, // 每个进程接收的数据项数量
MPI_Datatype sendtype,// 发送数据类型
void *recvbuf, // 接收缓冲区
int recvcount, // 接收的数据项数量(通常等于sendcount)
MPI_Datatype recvtype,// 接收数据类型
int root, // 根进程rank
MPI_Comm comm // 通信域
);
- 数据流向:
根进程的 sendbuf 被分割为 sendcount 大小的块,分发给各进程。
2. MPI_Gather
int MPI_Gather(
const void *sendbuf, // 发送缓冲区
int sendcount, // 发送的数据项数量
MPI_Datatype sendtype,// 发送数据类型
void *recvbuf, // 根进程的接收缓冲区
int recvcount, // 每个进程接收的数据项数量
MPI_Datatype recvtype,// 接收数据类型
int root, // 根进程rank
MPI_Comm comm // 通信域
);
- 数据流向:
所有进程的 sendbuf 被收集到根进程的 recvbuf 中。
五、同步函数
MPI_Barrier
int MPI_Barrier(
MPI_Comm comm // 通信域
);
- 功能:
所有进程在此处阻塞,直到通信域内的所有进程都调用此函数,然后继续执行。
六、关键参数详解
1. MPI_Datatype
- 预定义类型:
MPI_CHAR, MPI_INT, MPI_FLOAT, MPI_DOUBLE, MPI_LONG_LONG 等。
- 自定义类型:
通过 MPI_Type_create_struct 或 MPI_Type_contiguous 等函数创建。
2. MPI_Comm
- 通信域:
最常用的是 MPI_COMM_WORLD(包含所有进程),也可通过 MPI_Comm_split 创建子通信域。
3. MPI_Request
- 非阻塞通信句柄:
用于跟踪非阻塞操作的状态,配合以下函数使用:
MPI_Wait(MPI_Request *request, MPI_Status *status)
阻塞直到通信完成。
MPI_Test(MPI_Request *request, int *flag, MPI_Status *status)
非阻塞检查通信是否完成。
4. MPI_Status
- 接收状态信息:
包含实际接收的数据量、源进程 rank、消息标签等。
status.MPI_SOURCE:实际发送者的 rankstatus.MPI_TAG:实际消息标签MPI_Get_count(&status, datatype, &count):获取实际接收的数据项数量
七、示例代码片段
1. 点对点通信
// 进程0发送,进程1接收
if (rank == 0) {
int data = 42;
MPI_Send(&data, 1, MPI_INT, 1, 0, MPI_COMM_WORLD);
} else if (rank == 1) {
int received;
MPI_Recv(&received, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
}
2. 广播与归约
// 广播示例
int data = (rank == 0) ? 100 : 0;
MPI_Bcast(&data, 1, MPI_INT, 0, MPI_COMM_WORLD);
// 归约示例
int local_sum = rank;
int global_sum;
MPI_Reduce(&local_sum, &global_sum, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);
八、注意事项
- 缓冲区大小匹配:
MPI_Send的count必须与MPI_Recv的count兼容- 集体操作中所有进程的
count和datatype必须一致
- 非阻塞通信管理:
- 非阻塞操作返回后,发送缓冲区在完成前不能修改
- 必须调用
MPI_Wait或MPI_Test释放系统资源
- 消息匹配:
MPI_Send和MPI_Recv的tag和source/dest必须匹配- 使用
MPI_ANY_SOURCE或MPI_ANY_TAG需谨慎处理状态信息