本文参考:
- NVIDIA CUDA PTX ISA 9.7.14
在了解了基本的 GEMM 优化方法即 block/warp/thread 多级 tile 后,我们就在 warp 这一级转向使用基于 tensor core 使用使用 MMA 指令加速,相应的数据存、取、算都由对应的指令来完成。
参考:(45 封私信 / 85 条消息) 【CUDA编程】关于矩阵乘加操作的四个指令(ldmatrix、mma、stmatrix、movmatrix)详解 - 知乎
Warp Level Matrix Multiply-Accumulate Instructions
PTX provides two ways to perform matrix multiply-and-accumulate computation:
- Using
wmmainstructions:- This warp-level computation is performed collectively by all threads in the warp as follows:
- Load matrices A, B and C from memory into registers using the
wmma.loadoperation. When the operation completes, the destination registers in each thread hold a fragment of the loaded matrix. - Perform the matrix multiply and accumulate operation using the
wmma.mmaoperation on the loaded matrices. When the operation completes, the destination registers in each thread hold a fragment of the result matrix returned by thewmma.mmaoperation. - Store result Matrix D back to memory using the
wmma.storeoperation. Alternately, result matrix D can also be used as argument C for a subsequentwmma.mmaoperation. Thewmma.loadandwmma.storeinstructions implicitly handle the organization of matrix elements when loading the input matrices from memory for thewmma.mmaoperation and when storing the result back to memory.
- Load matrices A, B and C from memory into registers using the
- This warp-level computation is performed collectively by all threads in the warp as follows:
- Using
mmainstruction:- Similar to
wmma,mmaalso requires computation to be performed collectively by all threads in the warp however distribution of matrix elements across different threads in warp needs to be done explicitly before invoking themmaoperation. Themmainstruction supports both dense as well as sparse matrix A. The sparse variant can be used when A is a structured sparse matrix as described in Sparse matrix storage.
- Similar to
mma 对比 wmma 能够解决 bank conflict 等问题。mma 相比 wmma 提供了更细粒度的对存储的控制,所以 wmma 只做了解,本系列关注 mma。
mma
mma要求 warp 中的所有线程协同执行计算(和wmma类似),但在调用mma操作之前,需要显式地在 warp 中的不同线程之间分配矩阵元素。mma指令既支持密集也支持稀疏矩阵 A,稀疏的变体可以在稀疏矩阵 A 是结构化稀疏矩阵时使用,如 Sparse matrix storage。
PTX Mma 指令格式和数据类型
The matrix multiply and accumulate operations support a limited set of shapes for the operand matrices A, B and C. The shapes of all three matrix operands are collectively described by the tuple
MxNxK, where A is anMxKmatrix, B is aKxNmatrix, while C and D areMxNmatrices. 在 PTX warp level mat intruction 9.7.14.1 给出了支持的矩阵形状、9.7.14.2 给出了支持的数据类型。
9.7.14.5 MMA operation 给出了 mma 运算执行的矩阵 fragment 的形状和分布。
Ldmatrix
Collectively load one or more matrices from shared memory for mma instruction
ldmatrix 是 PTX ISA 中用于从共享内存加载矩阵数据的同步指令,主要为 mma 矩阵乘法指令提供数据输入,需由 warp 内所有线程协同执行。
Syntax
ldmatrix.sync.aligned.shape.num{.trans}{.ss}.type r, [p];
ldmatrix.sync.aligned.m8n16.num{.ss}.dst_fmt.src_fmt r, [p];
ldmatrix.sync.aligned.m16n16.num.trans{.ss}.dst_fmt.src_fmt r, [p];
.shape = {.m8n8, .m16n16};
.num = {.x1, .x2, .x4};
.ss = {.shared{::cta}};
.type = {.b16, .b8};
.dst_fmt = { .b8x16 };
.src_fmt = { .b6x16_p32, .b4x16_p64 };Collectively load one or more matrices across all threads in a warp from the location indicated by the address operand p, from .shared state space into destination register r. If no state space is provided, generic addressing is used, such that the address in p points into .shared space. If the generic address doesn’t fall in .shared state space, then the behavior is undefined.
在一个线程束的所有线程中,从地址操作数 p 所指示的位置(即 .shared 状态空间)共同加载一个或多个矩阵到目标寄存器 r 中。如果未指定状态空间,则使用通用寻址,此时 p 中的地址指向 .shared 空间。如果通用地址不在 .shared 状态空间内,那么其行为是未定义的。
下面是指令各段的解析:
- The
.shapequalifier indicates the dimensions of the matrices being loaded. Each matrix element holds 16-bit or 8-bit or 6-bit or 4-bit data. Following table shows the matrix load case for each.shape.
| .shape | Matrix shape | Element size |
|---|---|---|
.m8n8 | 8x8 | 16-bit |
.m16n16 | 16x16 | 8-bit or 6-bit or 4-bit |
.m8n16 | 8x16 | 6-bit or 4-bit |
- The values
.x1,.x2and.x4for.numindicate one, two or four matrices respectively. When.shapeis.m16n16, only.x1and.x2are valid values for.num. - The mandatory
.syncqualifier indicates thatldmatrixcauses the executing thread to wait until all threads in the warp execute the sameldmatrixinstruction before resuming execution. - The mandatory
.alignedqualifier indicates that all threads in the warp must execute the sameldmatrixinstruction. In conditionally executed code, anldmatrixinstruction should only be used if it is known that all threads in the warp evaluate the condition identically, otherwise the behavior is undefined. The behavior ofldmatrixis undefined if all threads do not use the same qualifiers, or if any thread in the warp has exited. - The destination operand
ris a brace-enclosed vector expression consisting of 1, 2, or 4 32-bit registers as per the value of.num. Each component of the vector expression holds a fragment from the corresponding matrix. - Supported addressing modes for
pare described in Addresses as Operands.
矩阵格式和数据类型
- 矩阵形状:支持
.m8n8(8x8,16 位元素)、.m16n16(16x16,8/6/4 位元素)、.m8n16(8x16,6/4 位元素)等形状。- 加载数量:通过
.num指定加载 1(.x1)、2(.x2)或 4(.x4)个矩阵,其中.m16n16形状仅支持 .x1 和 .x2。r是一个 32-bit 的向量寄存器,其数量也由.num决定。
Layout
Consecutive instances of row need not be stored contiguously in memory. The eight addresses required for each matrix are provided by eight threads, depending upon the value of .num as shown in the following table. Each address corresponds to the start of a matrix row. Addresses addr0–addr7 correspond to the rows of the first matrix, addresses addr8–addr15 correspond to the rows of the second matrix, and so on.
行的连续实例无需在内存中连续存储。每个矩阵所需的八个地址由八个线程提供,具体取决于如下表所示的 .num 的值。每个地址对应一个矩阵行的起始位置。地址 addr0–addr7 对应第一个矩阵的行,地址 addr8–addr15 对应第二个矩阵的行,依此类推。
.num | Threads 0–7 | Threads 8–15 | Threads 16–23 | Threads 24–31 |
|---|---|---|---|---|
.x1 | addr0–addr7 | – | – | – |
.x2 | addr0–addr7 | addr8–addr15 | – | – |
.x4 | addr0–addr7 | addr8–addr15 | addr16–addr23 | addr24–addr31 |
For .target
sm_75or below, all threads must contain valid addresses. Otherwise, the behavior is undefined. For.num = .x1and.num = .x2, addresses contained in lower threads can be copied to higher threads to achieve the expected behavior.
When reading 8x8 matrices, a group of four consecutive threads loads 16 bytes. The matrix addresses must be naturally aligned accordingly.
Each thread in a warp loads fragments of a row, with thread 0 receiving the first fragment in its register r, and so on. A group of four threads loads an entire row of the matrix as shown in Figure 104.
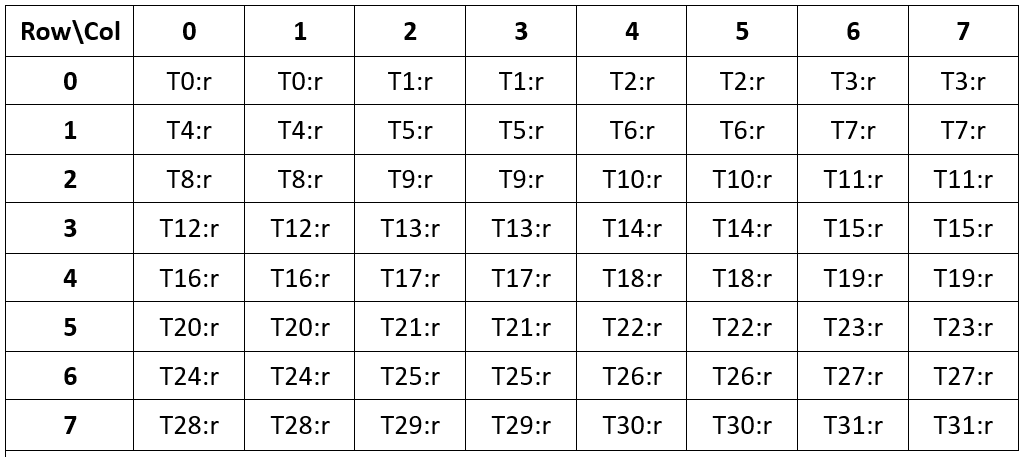
Figure 104 ldmatrix fragment layout for one 8x8 Matrix with 16-bit elements 其他尺寸可见 PTX guide
结合上一节的语法定义:
- 指令定义:
.m8n8支持 16-bit,对于.x1,一共64*2byte - 输入地址:矩阵中连续行不需要在内存中连续,每行有一个首地址,共 8 个地址,通过
0-7线程给出。 - 数据加载:四个连续的线程加载一行 16 byte,矩阵地址对齐。
- 数据输出:分给 32 个线程,每个线程读取两个输入元素到一个 float 寄存器
r中。
注,地址是指令的输入参数,提供给 8/16/32 个线程的,线程对应的这个行的地址是指令定义的,每个线程加载的数据的位置也是该指令定义的。也就是说上面这个例子,给前 8 个线程 8 个行的地址,32 个线程就可以各自去加载各自对应的位置的元素。
When .num = .x2, the elements of the second matrix are loaded in the next destination register in each thread as per the layout in above table. Similarly, when .num = .x4, elements of the third and fourth matrices are loaded in the subsequent destination registers in each thread.
内存存储规则、线程分工
矩阵的连续行无需在内存中连续存储,每个矩阵所需的 8 个行起始地址(对应 8 行)由 8 个线程提供,地址分组与矩阵数量挂钩(通过
.num参数控制)ldmatrix依赖 GPU 的 warp 线程组(通常 32 个线程)协作,核心规则:
- 加载 8x8 矩阵:4 个连续线程为一组,共同加载 16 字节数据;每个线程加载矩阵某一行的“片段”(如线程 0 加载行的第一个片段),4 个线程协作完成一整行加载。
- 加载 16x16 矩阵:需指定 2 个 32 位目标寄存器(
r0/r1),每个寄存器存 4 个 8 位元素;4 个连续线程为一组加载一整行,且每个线程会跨 2 行加载 4 个连续列。- 加载 8x16 矩阵:仅需 1 个 32 位目标寄存器,4 个连续线程为一组加载一整行,每个线程加载 4 个连续列。
- 列优先加载(.trans 限定符):
- 可选
.trans表示矩阵按“列优先”格式加载; - 加载 16x16 矩阵时,.trans 是强制要求(必须按列优先加载)。
- 可选
The ldmatrix instruction is treated as a weak memory operation in the Memory Consistency Model.
ldmatrix 属于“弱内存操作”,需遵循 PTX 内存一致性模型的相关规则(如可能需额外同步确保数据可见性)。
Example
了解了上面指令的规范后,我们知道要使用指令,需要明确:
- 确定需要使用的指令格式,输入矩阵的尺寸、数据类型、数量等信息
- 每个线程,给出 8/16/32 个行的地址(因为不同行的地址不保证连续,所以需要计算给出)
- 给出需要载入的 32bit 寄存器
代码如
#define LDMATRIX_X4(R0, R1, R2, R3, addr) \
asm volatile("ldmatrix.sync.aligned.x4.m8n8.shared.b16 \
{%0, %1, %2, %3}, [%4];\n" : \
"=r"(R0), "=r"(R1), "=r"(R2), "=r"(R3) : "r"(addr))
uint32_t RA[4];
uint32_t load_smem_a_ptr = // ;
LDMATRIX_X4(RA[0], RA[1], RA[2], RA[3], load_smem_a_ptr);mma
Perform matrix multiply-and-accumulate operation
- 支持的架构与扩展:
- Volta(Sm70):首次引入,仅支持 fp16 输入、fp32 累加,矩阵尺寸固定为 16x16x16。
- Ampere(Sm80):新增 tf32(Tensor float32)、bf16(脑浮点)支持,扩展矩阵尺寸(如 32x8x16)。
- Hopper(Sm90):支持 fp8(8 位浮点)、int4 等低精度类型,进一步提升 AI 推理效率。
Syntax
以 Half precision floating point type 为例, 更多格式见 mma 格式
mma.sync.aligned.m8n8k4.alayout.blayout.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k8.row.col.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k16.row.col.dtype.f16.f16.ctype d, a, b, c;
.alayout = {.row, .col};
.blayout = {.row, .col};
.ctype = {.f16, .f32};
.dtype = {.f16, .f32};
以 mma.sync.aligned.m16n8k16.row.col.f16.f16.f16.f16 d, a, b, c 为例,
- 参数含义:
m16n16k8:矩阵尺寸,即 A(16×8)×B(8×16)。row.col:矩阵 A、B 的布局(行优先 / 列优先)。f16.f16.f16.f16:数据类型,A 和 B 为 fp16,累加结果 C 和输出 D 为 fp16。d, a, b, c:寄存器中的矩阵数据(需按硬件要求对齐)。
A warp executing mma.m16n8k16 floating point types will compute an MMA operation of shape .m16n8k16.
Elements of the matrix are distributed across the threads in a warp so each thread of the warp holds a fragment of the matrix.
-
Multiplicand A:
.f16and.bf16:
| .atype | Fragment | Elements (low to high) |
|---|---|---|
.f16 / .bf16 | A vector expression containing four .f16x2 registers, with each register containing two .f16 / .bf16 elements from the matrix A. | a0, a1, a2, a3, a4, a5, a6, a7 |
Layout
The layout of the fragments held by different threads is shown in Figure 79.
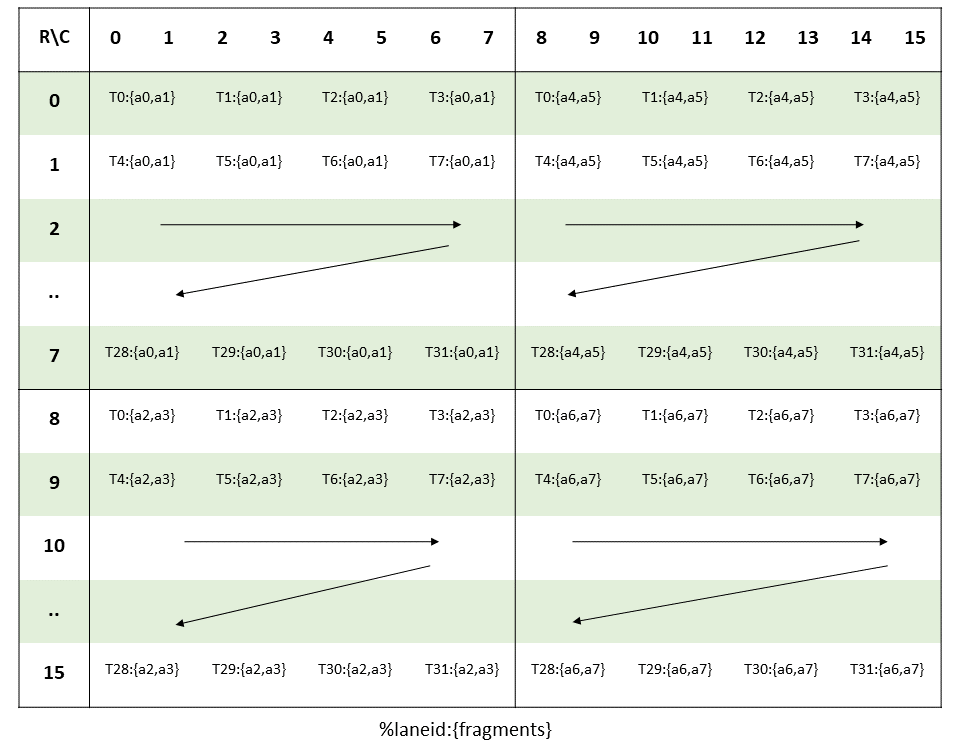
Figure 79 MMA .m16n8k16 fragment layout for matrix A with
.f16/.bf16type. 其他格式和数据类型见 ptx guide。
The row and column of a matrix fragment can be computed as:
groupID = %laneid >> 2
threadID_in_group = %laneid % 4
row = groupID for ai where 0 <= i < 2 || 4 <= i < 6
groupID + 8 Otherwise
col = (threadID_in_group * 2) + (i & 0x1) for ai where i < 4
(threadID_in_group * 2) + (i & 0x1) + 8 for ai where i >= 4MMA 指令的核心是定义了 warp(线程束)执行 mma.m16n8k8 指令时,矩阵 A(.f16/.bf16 类型)的元素如何在 32 个线程间分配,:
- 指令定义:
.m8n8支持 16-bit,对于.x1,一共64*2byte - 输入:A 有
16*8*2byte,每个线程包含两个.f16 x2寄存器,即两个 32 位寄存器,各包含两个.f16的 A 中的元素,共 4 个元素,这里定义为a0, a1, a2, a3。 - 映射规则:这些寄存器和原有的矩阵对应方式是通过线程在 warp 中的
%laneid(线程在束内的 ID,0~31),计算当前线程持有元素在矩阵 A 中的具体行列,- 先将 32 个线程按“4 个为一组”划分:
- 组 ID
groupID = %laneid >> 2(右移 2 位=除以 4,结果 07,共 8 组); - 组内线程 ID3,每组 4 个线程)。threadID_in_group = %laneid % 4(取余 4,结果 0 - 计算“行(row)”:
- 线程持有的
a0、a1对应矩阵 A 的groupID行(07 行); - 线程持有的15 行); (刚好覆盖矩阵 A 的 16 行)。a2、a3对应矩阵 A 的groupID + 8行(8 - 计算“列(col)”:
- 对
a0~a3中的每个元素ai(i=0~3),列号col = threadID_in_group * 2 + (i & 0x1); - 解释:每组 4 个线程,每个线程负责 2 列(*2),(i&0x1)区分同一线程内ai的两个元素(0 或 1,对应 2 列中的左/右); (刚好覆盖矩阵 A 的 8 列)。
- 先将 32 个线程按“4 个为一组”划分:
- 组 ID
同样的,MMA 指令的四个操作数都需要按照上面定义的映射规则对应。简言之:32 个线程通过“分组 +ID 映射”,刚好把矩阵拆分成 32 个元素片段,每个线程负责其中一块,协同完成 mma.m16n8k8 的乘加运算。
Example
uint32_t RC[2] = {0, 0};
uint32_t RA[4];
uint32_t RB[2];
#define HMMA16816(RD0, RD1, RA0, RA1, RA2, RA3, RB0, RB1, RC0, RC1) \
asm volatile("mma.sync.aligned.m16n8k16.row.col.f16.f16.f16.f16 \
{%0, %1}, {%2, %3, %4, %5}, {%6, %7}, {%8, %9};\n" : \
"=r"(RD0), "=r"(RD1) : "r"(RA0), "r"(RA1), "r"(RA2), "r"(RA3), \
"r"(RB0), "r"(RB1), "r"(RC0), "r"(RC1))
HMMA16816(RC[0], RC[1], RA[0], RA[1], RA[2], RA[3], RB[0], RB[1], RC[0], RC[1]);Stmatrix
参考 PTX guide
bank conflict
了解了基本的 MMA 指令的用法后,其实我发现最大的问题在于需要手动处理指令每个线程的输入数据,计算索引,处理数据排布等等,这个过程是复杂容易出错的。
MMA 使用
根据 NVIDIA 官方的最新技术路线图和开发者文档,MMA(Matrix Multiply-Accumulate)和 WMMA(Warp Matrix Multiply-Accumulate) 的地位和使用方式已经发生了显著变化,以下是详细分析:
1. MMA 与 WMMA 的现状
(1) MMA(Tensor Core 指令)
- 核心地位:
MMA 是 NVIDIA Tensor Core 的底层指令,仍然是当前及未来 GPU 架构(如 Hopper、Ada)的核心计算单元。
- Hopper 架构(H 100)引入了 FP 8 和 BF 16 支持,进一步扩展了 MMA 的适用范围。
- Ada 架构(RTX 40 系列)增强了对 DLSS 3 和光线追踪 的支持,MMA 在 AI ch 推理和图形计算中仍然关键。
- 推荐使用方式:
- 通过 CUTLASS 3. x 或 cuTENSOR:NVIDIA 推荐使用更高层的库(如 CUTLASS 3. x)来封装 MMA 操作,而非直接调用底层指令。
- FP 8 支持:Hopper 的 MMA 指令支持 FP 8,能显著提升大模型训练和推理的吞吐量(如 LLM 和扩散模型)。
(2) WMMA(Warp-Level Matrix Multiply-Accumulate)
- 历史背景:
- Volta/Turing 架构(如 V 100、T 4)中,WMMA 是 Warp 级的矩阵乘法指令,用于加速小规模矩阵运算(如 GEMV)。
- 局限性:WMMA 的 tile 大小固定(如 16 x 16 x 16),灵活性较低,且不支持最新的 FP 8 数据类型。
- 当前状态:
- NVIDIA 已逐步弃用 WMMA,推荐开发者使用 CUTLASS 2. x/3. x 或 Triton 来替代。
- 新架构(如 Hopper)不再支持 WMMA,仅保留对旧架构的兼容性。
2. 是否可以继续使用 MMA 和 WMMA?
(1) MMA 可以继续使用,但需升级方式
-
推荐做法:
- 使用 CUTLASS 3. x + CuTe:通过
cutlass::gemm::threadblock::Mma和cuTe::Shape抽象分块逻辑,自动适配不同架构(如 Hopper 的 FP 8)。 - FP 8 支持:在 Hopper 上利用 MMA 的 FP 8 指令,显著提升大模型训练效率(如 Mamba-MoE 架构)。
- cuTENSOR:对于张量计算(如卷积、矩阵分解),使用 cuTENSOR 库可自动优化 MMA 调度。
- 使用 CUTLASS 3. x + CuTe:通过
-
示例代码(CUTLASS 3. x):
using MMA = cutlass::gemm::threadblock::Mma< cutlass::gemm::GemmShape<128, 128, 32>, // Tile shape cutlass::gemm::GemmShape<32, 32, 8>, // Warp shape cutlass::gemm::GemmShape<16, 16, 4>, // Instruction shape (MMA micro-tile) float, float, float, // Data types cutlass::arch::OpClassTensorOp, // Use Tensor Core cutlass::arch::Sm90 // Target Hopper architecture >;
(2) WMMA 不推荐继续使用
- 原因:
- 性能瓶颈:WMMA 的 tile 大小固定(如 8 x 8 x 4),无法适配现代大模型的计算需求(如 128 x 128 x 32 的 tile)。
- 缺乏新特性支持:不支持 FP 8、混合精度等新数据类型。
- 兼容性问题:Hopper 架构已移除对 WMMA 的支持。
- 替代方案:
- Triton:通过 Python 编写内核,自动调度 MMA 指令(如 Triton 的矩阵乘法)。
- CUTLASS 3. x:通过模板化配置生成高效的 MMA 内核。
3. 更高效的方法:NVIDIA 的推荐方向
(1) 使用 CUTLASS 3. X + CuTe
-
优势:
- 多级分块抽象:通过
cuTe::Shape和cuTe::Stride定义灵活的 tile 布局,适配不同硬件(如 Hopper 的 16 x 16 x 4 微块)。 - 自动优化:CUTLASS 3. x 能根据硬件特性(如寄存器数、共享内存大小)自动调整 tile 大小。
- 支持 FP 8/BF 16:Hopper 的 FP 8 MMA 指令可显著降低内存带宽需求(如 LLM 推理中每个 token 的计算量减少 50%)。
- 多级分块抽象:通过
-
示例(FP 8 支持):
using ElementA = cutlass::float8_t; using ElementB = cutlass::float8_t; using ElementC = float; using MMA = cutlass::gemm::threadblock::Mma< cutlass::gemm::GemmShape<128, 128, 32>, cutlass::gemm::GemmShape<32, 32, 8>, cutlass::gemm::GemmShape<16, 16, 4>, ElementA, ElementB, ElementC, cutlass::arch::OpClassTensorOp, cutlass::arch::Sm90 >;
(2) 使用 Triton
-
优势:
- Python 编写,C++ 性能:通过高级语言定义计算逻辑,Triton 自动编译为高效的 CUDA 代码。
- 动态 tile 分块:支持运行时调整 tile 大小,适应不同输入维度。
- 集成 FP 8 支持:Triton 2.0 已支持 Hopper 的 FP 8 MMA 指令。
-
示例(Triton 矩阵乘法):
import triton import triton.language as tl @triton.jit def matmul_kernel(A, B, C, M, N, K, BLOCK_SIZE: tl.constexpr): pid = tl.program_id(0) num_pid_m = tl.cdiv(M, BLOCK_SIZE) num_pid_n = tl.cdiv(N, BLOCK_SIZE) pid_m = pid // num_pid_n pid_n = pid % num_pid_n rm = pid_m * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE) rn = pid_n * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE) rk = tl.arange(0, BLOCK_SIZE) # Load A and B tiles a = tl.load(A + rm[:, None] * K + rk[None, :]) b = tl.load(B + rk[:, None] * N + rn[None, :]) # Compute C tile c = tl.dot(a, b) # Store C tile tl.store(C + rm[:, None] * N + rn[None, :], c)
(3) 使用 cuTENSOR
-
适用场景:
- 张量分解(如 Tucker 分解)、卷积、张量核函数。
- cuTENSOR 会自动选择最优的 MMA 配置(如 tile 大小、数据布局)。
-
示例:
#include <cute/tensor.hpp> #include <cute/algorithm/gemm.hpp> using namespace cute; using LayoutA = Layout<Shape<_128, _128>, Stride<_128, _1>>; using LayoutB = Layout<Shape<_128, _128>, Stride<_1, _128>>; Tensor A = make_tensor<LayoutA>(...); Tensor B = make_tensor<LayoutB>(...); Tensor C = gemm(A, B); // 自动调用 MMA 指令
4. 总结:是否继续使用 MMA/WMMA?
| 技术 | 是否推荐 | 原因 | 替代方案 |
|---|---|---|---|
| MMA(Tensor Core) | ✅ 推荐 | 现代 GPU 架构的核心指令,支持 FP 8/BF 16。 | 通过 CUTLASS 3. x、Triton 或 cuTENSOR 使用。 |
| WMMA(Warp-Level) | ❌ 不推荐 | 固定 tile 大小,性能落后于 MMA,Hopper 不再支持。 | 使用 CUTLASS 3. x 或 Triton 替代。 |
5. 最佳实践建议
-
选择目标架构:
- 如果使用 Hopper(H 100),优先使用 FP 8 MMA 和 CUTLASS 3. x。
- 如果使用 Ampere(A 100),可继续使用 FP 16 MMA,但避免 WMMA。
-
避免手动调用底层指令:
- 通过 CUTLASS 3. x 或 Triton 抽象分块逻辑,自动适配硬件特性(如寄存器数、共享内存大小)。
-
关注 NVIDIA 官方文档:
通过上述方法,您可以充分利用 NVIDIA 最新的硬件特性(如 FP 8 和 Hopper MMA),同时避免因使用过时技术(如 WMMA)导致的性能瓶颈。
WMMA 和 MMA 对比
在 CUDA 中,WMMA(Warp Matrix Multiply-Accumulate)和 MMA(Matrix Multiply-Accumulate)是两种不同的接口/指令,均用于利用 GPU 的 Tensor Core 进行高效的矩阵计算。它们的主要区别在于抽象层级、灵活性和适用场景。以下是详细对比:
1. WMMA(Warp Matrix Multiply-Accumulate API)
WMMA 封装了 Tensor Core 的底层操作(如数据加载、矩阵乘法、结果存储),简化了开发者对 Tensor Core 的使用。它通过 warp-level 的 fragment 操作,提供更简洁的编程接口。
- 数据加载:
load_matrix_sync(从全局内存或共享内存加载数据到 fragment)。 - 矩阵乘法:
mma_sync(执行D = A * B + C操作)。 - 结果存储:
store_matrix_sync(将结果写回全局内存或共享内存)。 - Fragment 抽象:通过
wmma::fragment定义矩阵分块(如16x16x16)。
2. MMA(Matrix Multiply-Accumulate PTX 指令)
MMA 是 底层 PTX 指令,直接调用 GPU 的 Tensor Core 硬件资源,提供更细粒度的控制。开发者需要手动管理数据加载、矩阵分块和寄存器分配。
- 数据加载:
__ldmatrix_sync(从全局内存或共享内存加载数据到寄存器)。 - 矩阵乘法:
__mma_sync(执行D = A * B + C操作)。 - 结果存储:
__stmatrix_sync(将结果写回内存)。 - 线程级控制:每个线程需明确负责的数据和计算任务。
__half2 a[8][8], b[8][8], c[8][8];
__ldmatrix_sync(a, global_memory_ptr_a, …); // 手动加载数据
__ldmatrix_sync(b, global_memory_ptr_b, …);
__mma_sync(c, a, b, c, 8, 8, 8); // 执行矩阵乘法
__stmatrix_sync(global_memory_ptr_c, c, …); // 存储结果5. Hopper 架构的 WGMMA
在 Hopper 架构(NVIDIA H100)中,NVIDIA 引入了 Warpgroup Matrix Multiply-Accumulate (WGMMA),进一步扩展了 MMA 的能力:
- 异步计算:支持异步执行,减少指令流水线阻塞。
- 直接读取共享内存:无需先加载到寄存器,可直接从共享内存(SMEM)进行计算。
- 性能提升:通过 Warpgroup 并行化,接近 Tensor Core 的理论算力上限。