CUTLASS is a collection of abstractions for implementing high-performance matrix-matrix multiplication (GEMM) and related computations at all levels and scales within CUDA. It incorporates strategies for hierarchical decomposition and data movement. CUTLASS decomposes these “moving parts” into reusable, modular software components and abstractions.
Primitives for different levels of a conceptual parallelization hierarchy can be specialized and tuned via custom tiling sizes, data types, and other algorithmic policy. The resulting flexibility simplifies their use as building blocks within custom kernels and applications.
CUTLASS provides:
Threadblock-level abstractions for matrix multiply-accumulate operations
Warp-level primitives for matrix multiply-accumulate operations
Epilogue components for various activation functions and tensor operations
Utilities for efficiently loading and storing tensors in memory
CUTLASS 3.0 introduced a new core library, CuTe, to describe and manipulate tensors of threads and data. CuTe is a collection of C++ CUDA template abstractions for defining and operating on hierarchically multidimensional layouts of threads and data. CuTe provides Layout and Tensor objects that compactly package the type, shape, memory space, and layout of data, while performing the complicated indexing for the user. This lets programmers focus on the logical descriptions of their algorithms while CuTe does the mechanical bookkeeping for them. With these tools, we can quickly design, implement, and modify all dense linear algebra operations.
CUTE was introduced in CUTLASS 3.0 and represents a significant evolution in NVIDIA’s approach to tensor computing. CUTE introduces:
A unified tensor abstraction that works across different hardware levels
Powerful layout mapping capabilities for tensors
Composable building blocks for tensor algorithms
A more intuitive programming model for complex tensor operations
作为对比:
CUDA is the base programming model and platform for NVIDIA GPUs. It provides the fundamental parallel computing architecture and programming interface.
CUTLASS is a library built on top of CUDA that provides optimized implementations of matrix operations.
CUTE is a higher-level abstraction built on top of CUTLASS that simplifies tensor programming.
注:这节讲述了两点,一个是内积转外积,一个是对输出 C 矩阵分块,现有很多教程会直接把这两点揉到一起,结合 shared memory 讲述。
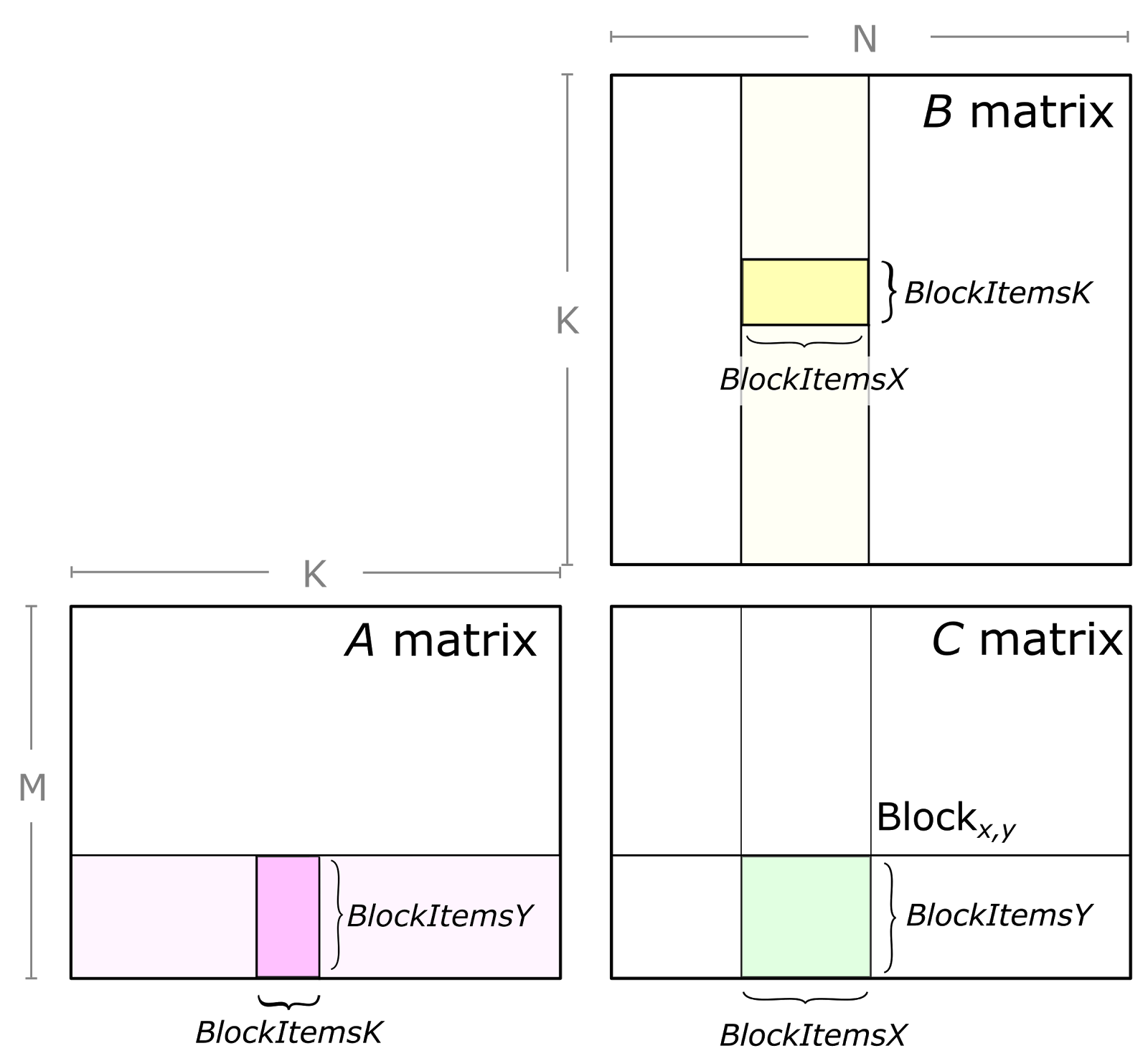
GEMM computes C = alphaA * B +betaC, where A, B, and C are matrices. A is an M-by-K matrix, B is a K-by-N matrix, and C is an M-by-N matrix. For simplicity, let us assume scalars alpha=beta=1 in the following examples. Later, we will show how to implement custom element-wise operations with CUTLASS supporting arbitrary scaling functions.
for (int i = 0; i < M; ++i) for (int j = 0; j < N; ++j) for (int k = 0; k < K; ++k) C[i][j] += A[i][k] * B[k][j]; // dot product of row in A and col in B
The element of C at position (i, j) is the K-element dot product of the i-th row of A and the j-th column of B. Ideally, performance should be limited by the arithmetic throughput of the processor. Indeed, for large square matrices where M=N=K, the number of math operations in a product of matrices is O(N__3_)_ while the amount of data needed is O(N__2_),_ yielding a compute intensity on the order of N. However, taking advantage of the theoretical compute intensity requires reusing every element O(N) times. Unfortunately, the above “inner product” algorithm depends on holding a large working set in fast on-chip caches, which results in thrashing as M, N, and K grow.
理论计算强度为 N,即一次读写计算 N 次即可发挥硬件算力。
A better formulation permutes the loop nest by structuring the loop over the K dimension as the outermost loop. This form of the computation loads a column of A and a row of B once, computes its outer product, and accumulates the result of this outer product in the matrix C. Afterward, this column of A and row of B are never used again.
内积:向量转标量;外积:向量转矩阵
for (int k = 0; k < K; ++k) // K dimension now outer-most loop for (int i = 0; i < M; ++i) for (int j = 0; j < N; ++j) C[i][j] += A[i][k] * B[k][j];
解决缓存复用问题
原始顺序是内积:固定 A 的第 i 行,C 的第 j 列,遍历 k 完成点积。A 行连续访问,B 是跨列访问。
B 是 “跳跃式访问” ,每次读一个 B[k][j],都要从主存加载一整行到缓存(cache line),但只用了一个元素,造成缓存未命中!M N K 较大时无妨放入完整行列 → 缓存颠簸(thrashing)
转换后内积转外积:从 “点积积累”(A 行 ×B 列的 K 维点积)转变为 “外积累加”(A 的第 k 列 × B 的第 k 行,得到一个 M×N 的外积矩阵,再累加到 C。
B 和 C 的访问是高度局部化和连续的,A 是列访问,但是 A[i][k] 缓存一次复用 j 次,而且之后不需要再使用,
理论上,矩阵乘法的计算强度为 K/2(对 M=N=K 的方阵,总运算量 O (K³),总数据量 O (K²),即每字节数据需执行 K 次运算)。
但实际性能能否达到理论值,取决于 “数据是否能在缓存中被复用 K 次”—— 如果数据每次都要从内存重新读取,计算强度会暴跌到接近 0(每字节仅执行 1 次运算),性能被内存带宽卡死。
One concern with this approach is that it requires all M-by-N elements of C to be live to store the results of each multiply-accumulate instruction, ideally in memory that can be written as fast as the multiply-accumulate instruction can be computed. We can reduce the working set size of C by partitioning it into tiles of size Mtile-by-Ntile that are guaranteed to fit into on-chip memory. Then we apply the “outer product” formulation to each tile. This leads to the following loop nest.
// 外层:遍历C矩阵的“瓷砖块”(按Mtile、Ntile步长拆分)for (int m = 0; m < M; m += Mtile) // iterate over M dimension for (int n = 0; n < N; n += Ntile) // iterate over N dimension // 中层:外积的k维度(与之前一致,遍历点积维度) for (int k = 0; k < K; ++k) // 内层:计算当前瓷砖块的所有元素(Mtile×Ntile) for (int i = 0; i < Mtile; ++i) // compute one tile for (int j = 0; j < Ntile; ++j) { int row = m + i; int col = n + j; C[row][col] += A[row][k] * B[k][col]; }
For each tile of C, tiles of A and B are fetched exactly once, which achieves O(N) compute intensity. The size of each tile of C may be chosen to match the capacity of the L1 cache or registers of the target processor, and the outer loops of the nest may be trivially parallelized. This is a great improvement!
整个计算过程的计算强度(FLOPs/Byte)达到 O (K)(每传输 1 字节 A/B 数据,执行 K 次乘累加运算),完全逼近 GEMM 的理论计算强度(K/2)
Further restructuring offers additional opportunities to exploit both locality and parallelism. Rather than exclusively accumulate vector outer products, we can accumulate the products of matrices by stepping through the K dimension in blocks. We refer to this concept generally as accumulating matrix products.
// 新增:k维度按Ktile分块
for (int k = 0; k < K; k += Ktile)
// 内层k循环:遍历当前k块
for (int k_inner = 0; k_inner < Ktile; ++k_inner)
// 后续C/A/B的瓷砖循环...
对 C 分块
上面方法需要存储整个 C 矩阵,因此通过分块进一步提升缓存复用和计算效率。
未分块时:C 的每个元素需要从 DRAM 读取→更新→写回 DRAM,每次访问耗时数十时钟周期;
分块后:当前瓷砖块的所有 C [row][col](Mtile×Ntile 个元素)会被一次性加载到 L1 缓存中,在整个 k 循环(K 轮)中,所有对该瓷砖的更新都在缓存内完成,仅需在 “处理完整个瓷砖” 后写回 DRAM 一次。
A/B 矩阵复用:
A 的一列、B 的一行会在缓存中复用。
同时可支持并行化:
分块后的外层循环(m 和 n 循环,即 “遍历 C 的瓷砖块”)是无依赖的:不同瓷砖块的计算完全独立。瓷砖大大小根据硬件属性来决定。
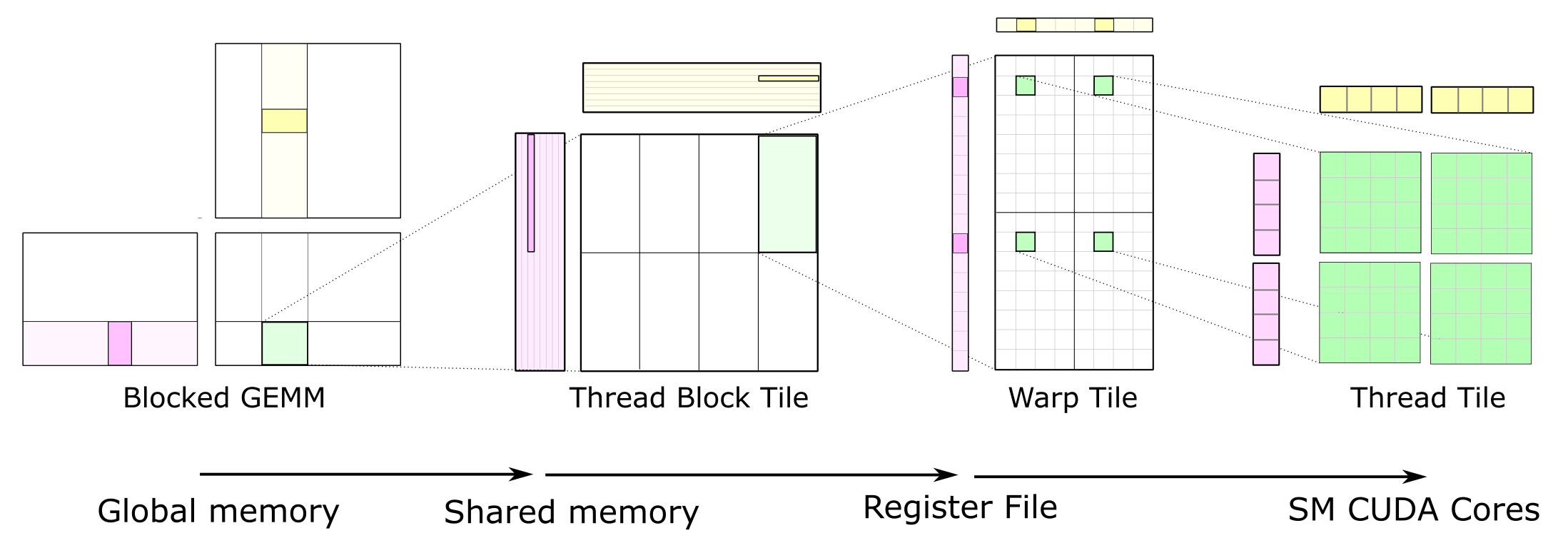
Hierarchical GEMM Structure
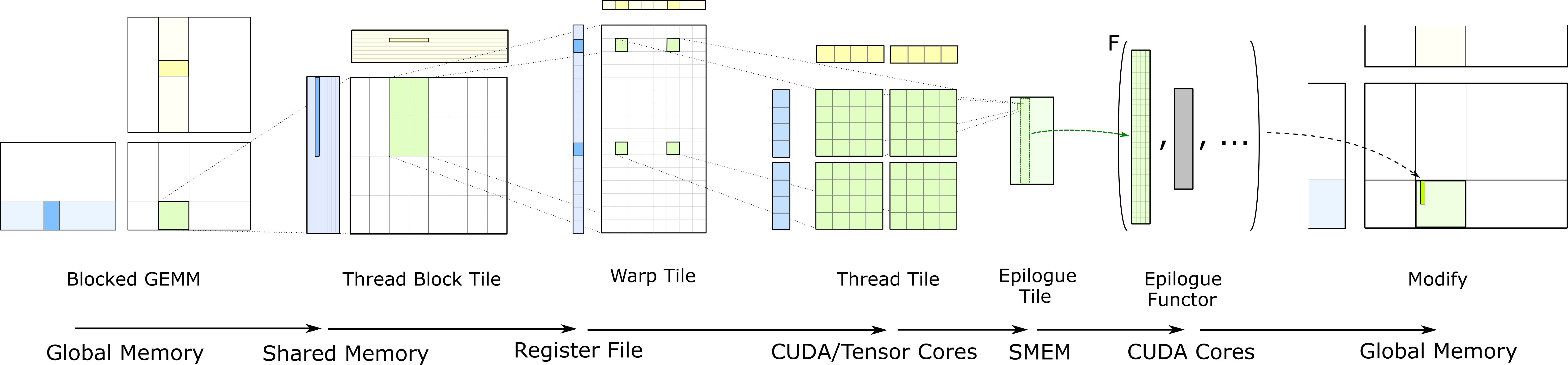
CUTLASS applies the tiling structure to implement GEMM efficiently for GPUs by decomposing the computation into a hierarchy of thread block tiles, warp tiles, and thread tiles and applying the strategy of accumulating matrix products. This hierarchy closely mirrors the NVIDIA CUDA programming model, as Figure 1 shows. Here, you can see data movement from global memory to shared memory (matrix to thread block tile), from shared memory to the register file (thread block tile to warp tile), and from the register file to the CUDA cores for computation (warp tile to thread tile).
Figure 1. The complete GEMM hierarchy transfers data from slower memory to faster memory where it is reused in many math operations.
注意原文图中的格子数量不完全等于维度信息。
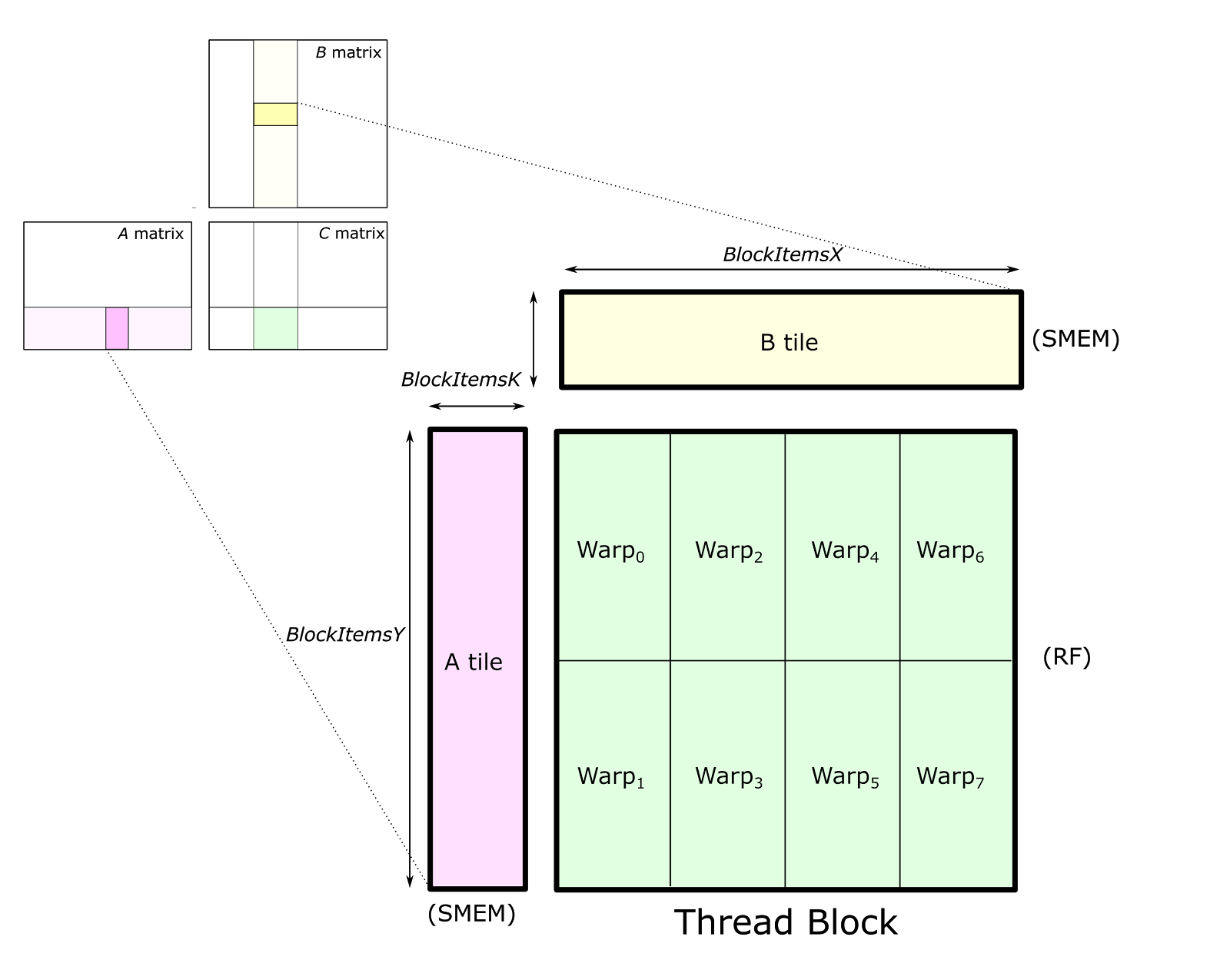
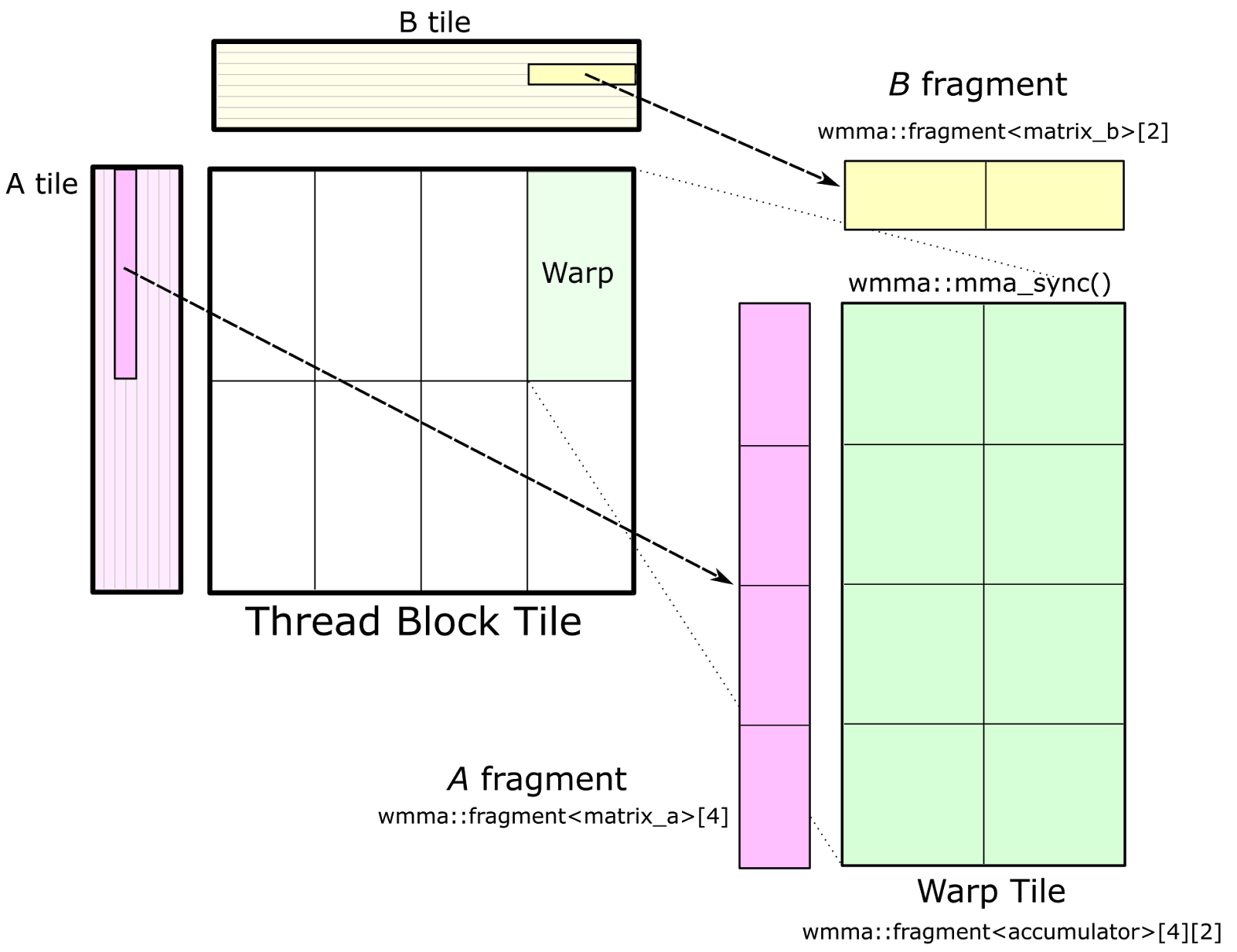
Each thread block computes its part of the output GEMM by iteratively loading blocks of matrix data from the input matrices and computing an accumulated matrix product (C += A * B). Figure 2 shows the computation performed by a single thread block and highlights the blocks of data used in one iteration of its main loop.
Figure 2. A GEMM problem decomposed into the computation performed by a single thread block. The submatrix of C shown in green is computed by the matrix product of a tile of A and a submatrix of B. This is performed by looping over the K dimension, partitioned into tiles, and accumulating the results of matrix products of each tile.
The CUDA thread block tile structure is further partitioned into warps (groups of threads that execute together in SIMT fashion).
“Warps provide a helpful organization for the GEMM computation and are an explicit part of the WMMA API, as we shall discuss shortly.”
这里分层后可以有不同的执行方式,现在不建议使用 WMMA。
Figure 3 shows a detailed view of the structure of one block-level matrix product. Tiles of A and B are loaded from global memory and stored into shared memory accessible by all warps. The thread block’s output tile is spatially partitioned across warps as Figure 3 shows. We refer to storage for this output tile as accumulators because it stores the result of accumulated matrix products. Each accumulator is updated once per math operation, so it needs to reside in the fastest memory in the SM: the register file.
Figure 3. The thread block structure partitions the tile of C across several warps, with each warp storing a non-overlapping 2D tile. Each warp stores its accumulator elements in registers. Tiles of A and B are stored in shared memory accessible to all of the warps in the thread block.
The parameters Block__Items{X,Y,K} are compile-time constants that the programmer specifies to tune the GEMM computation for the target processor and the aspect ratio of the specific GEMM configuration (e.g. M, N, K, data type, etc.). In the figure, we illustrate an eight-warp, 256-thread thread block which is typical for the large SGEMM (FP32 GEMM) tile size implemented in CUTLASS.
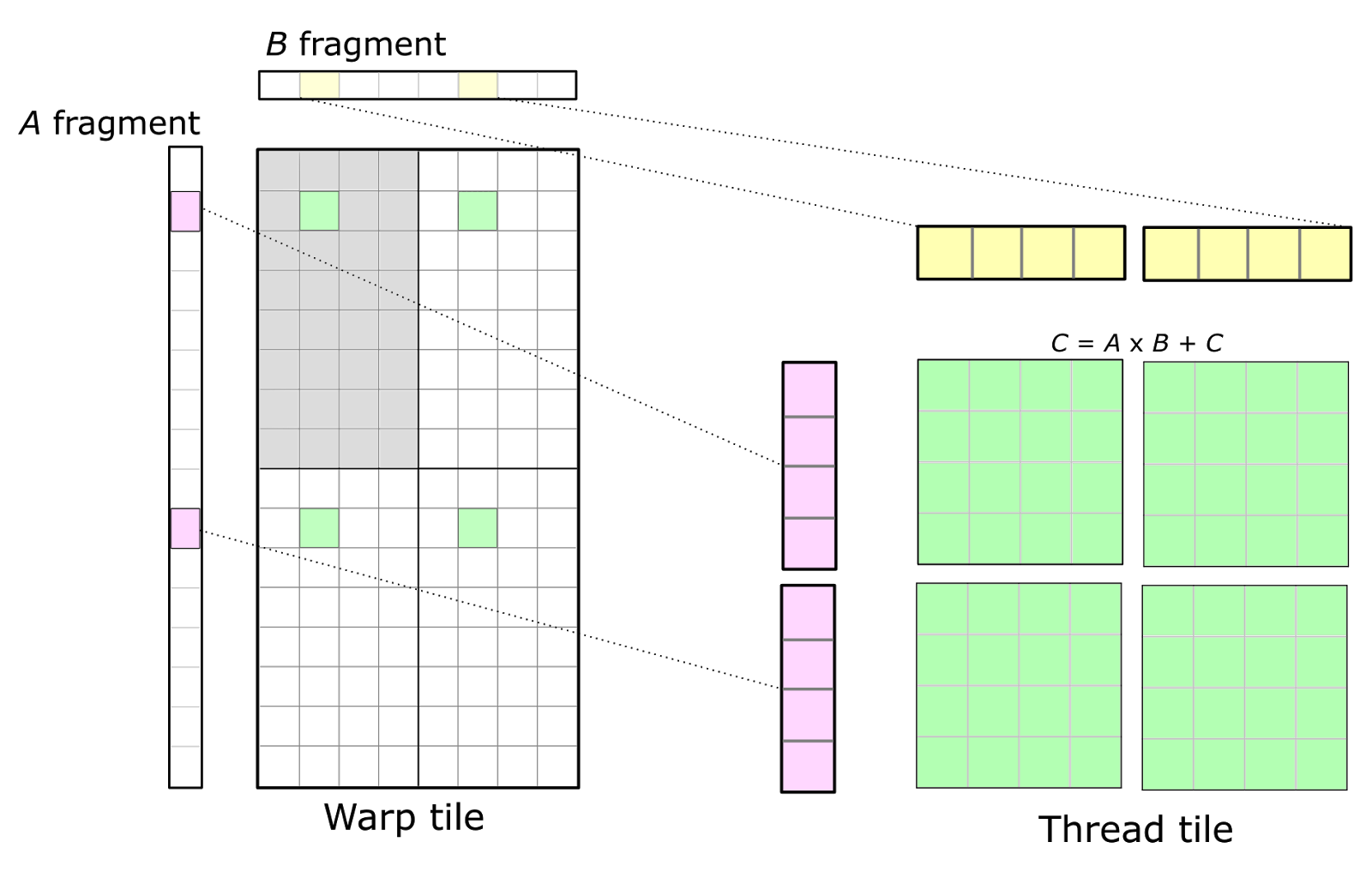
Warp Tile
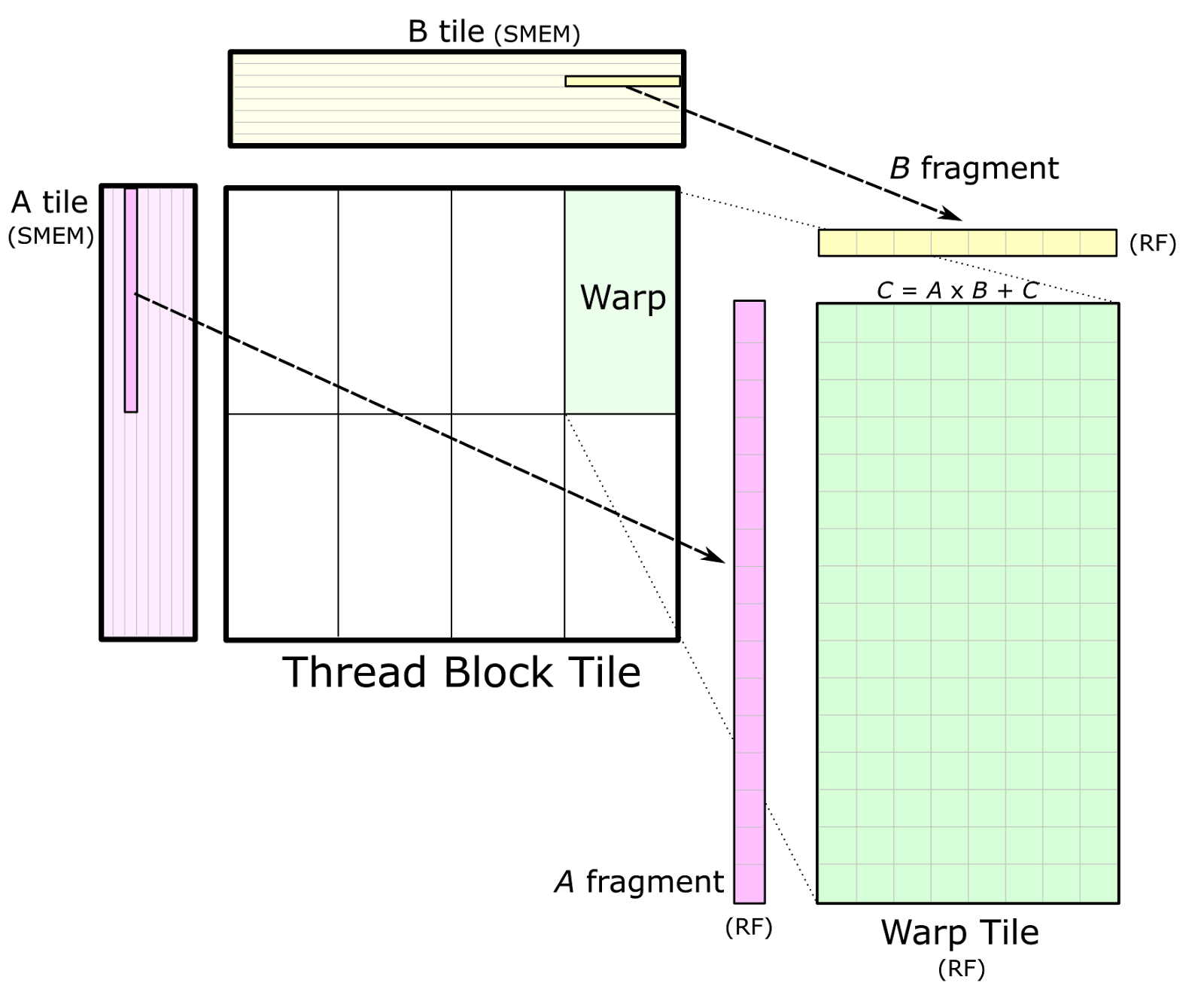
Once data is stored in shared memory, each warp computes a sequence of accumulated matrix products by iterating over the K dimension of the thread block tile, loading submatrices (or fragments) from shared memory, and computing an accumulated outer product. Figure 4 shows a detailed view. The sizes of the fragments are typically very small in the K dimension to maximize the compute intensity relative to the amount of data loaded from shared memory, thereby avoiding shared memory bandwidth as a bottleneck.
线程块瓷砖(Thread Block Tile)在 K 维度上的进一步拆分—— 每个 Warp 负责处理 Thread Block Tile 中的一个 “小瓷砖”,这个小瓷砖就是 Warp Tile;其数据需从共享内存加载到 Warp 内线程的寄存器,再通过外积累加完成计算。
为避免共享内存带宽瓶颈,Warp 不会一次性加载 Thread Block Tile 中 K 维度的所有数据(如 64 个元素),而是拆分为更小的 “片段(fragment)”(如 K 维度仅 8 个元素),即 Warp Tile 的 K 维度大小远小于 Thread Block Tile 的 K 维度;
共享内存中的 Warp Tile 片段 → 加载到 Warp 内线程的寄存器 → 线程执行外积计算 → 结果累加到 C 的 Warp Tile 中。
Figure 4. An individual warp computes an accumulated matrix product by iteratively loading fragments of A and B from the corresponding shared memory (SMEM) tiles into registers (RF) and computing an outer product.
Figure 4 also depicts data sharing from shared memory among several warps. Warps in the same row of the thread block load the same fragments of A, and warps in the same column load the same fragments of B.
行方向 Warp 共享 A 片段;列方向 Warp 共享 B 片段。
We note that the warp-centric organization of the GEMM structure is effective in implementing an efficient GEMM kernel but does not rely on implicit warp-synchronous execution for synchronization. CUTLASS GEMM kernels are well-synchronized with calls to __syncthreads() as appropriate.
The CUDA Programming Model is defined in terms of thread blocks and individual threads. Consequently, the warp structure is mapped onto operations performed by individual threads. Threads cannot access each other’s registers, so we must choose an organization that enables values held in registers to be reused for multiple math instructions executed by the same thread. This leads to a 2D tiled structure within a thread as the detailed view in Figure 5 shows. Each thread issues a sequence of independent math instructions to the CUDA cores and computes an accumulated outer product.
Figure 5. An individual thread (right) participates in a warp-level matrix product (left) by computing an outer product of a fragment of A and a fragment of B held in registers. The warp’s accumulators in green are partitioned among the threads within the warp and typically arranged as a set of 2D tiles.
In Figure 5, the upper left quadrant of the warp is shaded in grey. The 32 cells correspond to the 32 threads within a warp. This arrangement leads to multiple threads within the same row or the same column fetching the same elements of the A and B fragments, respectively. To maximize compute intensity, this basic structure can be replicated to form the full warp-level accumulator tile, yielding an 8-by-8 overall thread tile computed from an outer product of 8-by-1 and 1-by-8 fragments. This is illustrated by the four accumulator tiles shown in green.
The basic triple loop nest computing matrix multiply may be blocked and tiled to match concurrency in hardware, memory locality, and parallel programming models. In CUTLASS, GEMM is mapped to NVIDIA GPUs with the structure illustrated by the following loop nest.
For brevity, address and index calculations are omitted here but are explained in the CUTLASS source code.
for (int cta_n = 0; cta_n < GemmN; cta_n += CtaTileN) { // for each threadblock_y } threadblock-level concurrency for (int cta_m = 0; cta_m < GemmM; cta_m += CtaTileM) { // for each threadblock_x } for (int cta_k = 0; cta_k < GemmK; cta_k += CtaTileK) { // "GEMM mainloop" - no unrolling // - one iteration of this loop is one "stage" // for (int warp_n = 0; warp_n < CtaTileN; warp_n += WarpTileN) { // for each warp_y } warp-level parallelism for (int warp_m = 0; warp_m < CtaTileM; warp_m += WarpTileM) { // for each warp_x } // for (int warp_k = 0; warp_k < CtaTileK; warp_k += WarpTileK) { // fully unroll across CtaTileK // - one iteration of this loop is one "k Group" // for (int mma_k = 0; mma_k < WarpTileK; mma_k += MmaK) { // for each mma instruction } instruction-level parallelism for (int mma_n = 0; mma_n < WarpTileN; mma_n += MmaN) { // for each mma instruction } for (int mma_m = 0; mma_m < WarpTileM; mma_m += MmaM) { // for each mma instruction } // mma_instruction(d, a, b, c); // TensorCore matrix computation } // for mma_m } // for mma_n } // for mma_k } // for warp_k } // for warp_m } // for warp_n } // for cta_k } // for cta_m} // for cta_n
All loops except the outermost “main” loop have constant iteration counts and can be fully unrolled by the compiler.
The figure below illustrates the flow of data within this structure. This is the hierarchical GEMM computation embodied by CUTLASS. Each stage depicts a nested level of tiling which corresponds to a layer of concurrency within the CUDA execution model and to a level within the memory hierarchy, becoming increasingly finer moving left to right.
Threadblock-level GEMM
Each threadblock computes its portion of the output GEMM by iteratively loading tiles of input matrices and computing an accumulated matrix product.
At the threadblock level, data are loaded from global memory. The blocking strategy in general is key to achieving efficiency. However, the programmer must balance multiple conflicting goals. A larger threadblock means fewer fetches from global memory, thereby ensuring that DRAM bandwidth does not become a bottleneck. However, large threadblock tiles may not match the dimensions of the problem well. If either the GEMM M or N dimension is small, some threads within the threadblock may not perform meaningful work, as the threadblock may be partially outside the bounds of the problem. If both M and N are small while K is large, this scheme may launch relatively few threadblocks and fail to make full use of all multiprocessors within the GPU. Strategies to optimize performance for this case, as described in the section Parallelized Reductions, partition the GEMM K dimension across multiple threadblocks or multiple warps. These threadblocks or warps compute matrix products in parallel; the products are then reduced to compute the result.
需要权衡 block 的大小,后文也有一种并行规约的方法
In CUTLASS, the dimensions of the threadblock tile are specified as ThreadblockShape::{kM, kN, kK} and may be tuned to specialize the GEMM computation for the target processor and dimensions of the GEMM problem.
Warp-level GEMM
The warp-level GEMM maps to the warp-level parallelism within the CUDA execution model. Multiple warps within a threadblock fetch data from shared memory into registers and perform computations. Warp-level GEMMs may be implemented either by TensorCores issuing mma.sync or wmma instructions, or by thread-level matrix computations issued to CUDA cores. For maximum performance, access to shared memory should be bank conflict free. To maximize data reuse within the warp, a large warp-level GEMM tile should be chosen.
多个 warp 会先从共享内存(shared memory,CUDA 中线程块内共享的高速缓存) 读取数据,加载到各自线程的寄存器(register,线程私有的最快存储) ,再执行矩阵乘法运算,这是 CUDA 中高效计算的典型数据流向。可以用 Tensor Core 也可以用 CUDA core 计算。
为让 warp 级 GEMM 达到最高性能,需关注:1. bank conflict;2. 大 warp tile,增加数据使用,即一次加载完成更多计算,增加算数密度。
Thread-level GEMM
At the lowest level of blocking, each thread is responsible for processing a certain number of elements. Threads cannot access each other’s registers, so we choose an organization that enables reuse of values held in registers for multiple math instructions. This results in a 2D tiled structure within a thread, in which each thread issues a sequence of independent math instructions to the CUDA cores and computes an accumulated outer product.
SGEMM, IGEMM, HGEMM, and DGEMM are computed by SIMT math instructions issued by thread-level matrix multiply procedures.
The above code focuses only on the matrix multiply computation C = AB whose result is held in the registers of each thread within the threadblock. The mapping of logical elements in the output tile to each thread is chosen to maximize performance of the matrix multiply computation but does not result in efficient, coalesced loads and stores to global memory.
上面的代码聚焦矩阵乘法计算阶段的特点与局限
核心任务:聚焦于矩阵乘法运算 C = AB,且计算结果仅暂存在线程块(threadblock)内每个线程的寄存器中(寄存器是 GPU 中速度最快的存储单元,适合暂存即时计算数据)。
The epilogue is a separate phase in which threads exchange data through shared memory then cooperatively access global memory using efficient striped access patterns. It is also the phase in which linear scaling and other elementwise operations may be conveniently computed using the matrix product results as inputs.
支持元素级扩展操作:可利用矩阵乘法的结果(即寄存器中暂存的 C)作为输入,便捷执行“线性缩放(如 C = alpha*C + beta,GEMM 常见需求)”“元素级运算(如逐元素加减乘除)”等操作,无需额外启动新的计算核函数。
CUTLASS defines several typical epilogue operations such as linear scaling and clamping, but other device-side function call operators may be used to perform custom operations.
同时这一阶段还有一定的灵活性:CUTLASS 已内置多种典型的 Epilogue 操作(如线性缩放、数值裁剪(clamping)),同时支持用户通过“设备端函数调用算子(device-side function call operators)”自定义操作,满足个性化需求。
Optimizations
The hierarchical structure described above yields an efficient mapping to the CUDA execution model and CUDA/TensorCores in NVIDIA GPUs. The following sections describe strategies for obtaining peak performance for all corners of the design space, maximizing parallelism and exploiting data locality wherever possible.
Pipelining
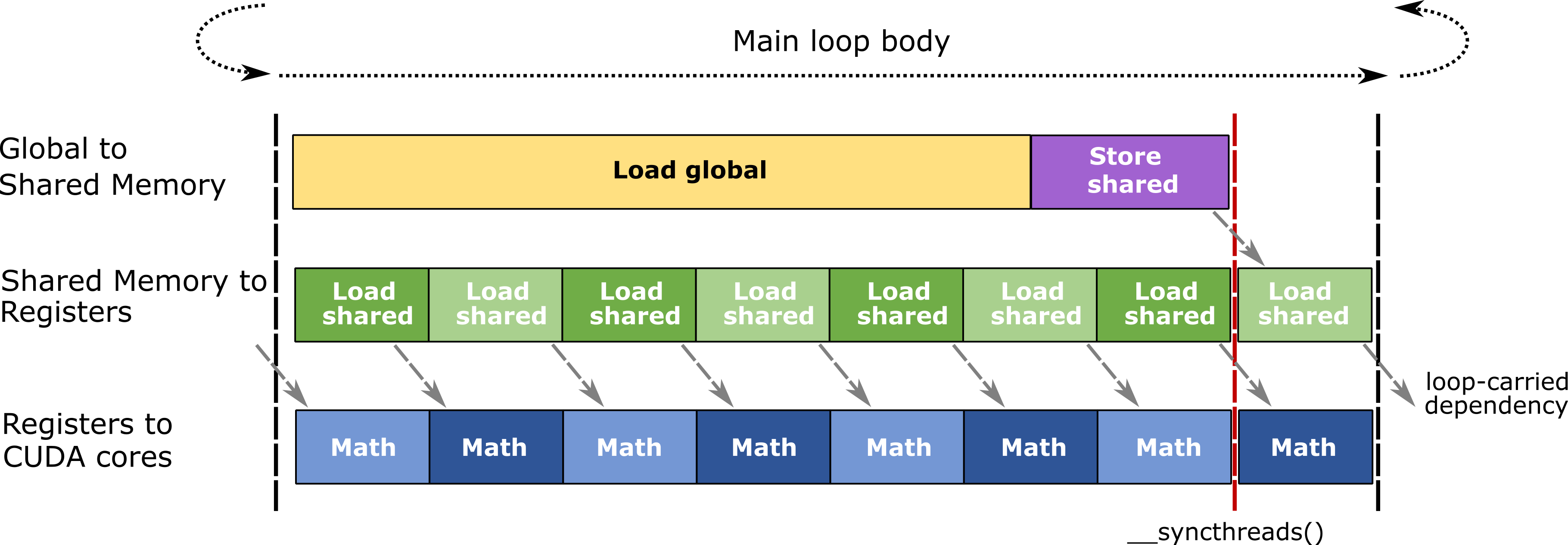
The blocked structure demands a large storage allocation within the registers of each CUDA thread. The accumulator elements typically occupy at least half a thread’s total register budget. Consequently, occupancy – the number of concurrent threads, warps, and threadblocks – is relatively low compared to other classes of GPU workloads. This limits the GPU’s ability to hide memory latency and other stalls by context switching to other concurrent threads within an SM.
这种分块结构要求在每个 CUDA 线程的寄存器中分配大量存储空间。累加器元素通常至少占据线程总寄存器预算的一半。因此,与其他类型的 GPU 工作负载相比,占用率(即并发线程、 warp 和线程块的数量)相对较低。这限制了 GPU 通过上下文切换到 SM 内的其他并发线程来隐藏内存延迟和其他停顿的能力。
To mitigate the effects of memory latency, CUTLASS uses software pipelining to overlap memory accesses with other computation within a thread. CUTLASS accomplishes this by double buffering at the following scopes.
Threadblock-scoped shared memory tiles: two tiles are allocated in shared memory. One is used to load data for the current matrix operation, while the other tile is used to buffer data loaded from global memory for the next mainloop iteration.
Warp-scoped matrix fragments: two fragments are allocated within registers. One fragment is passed to CUDA and TensorCores during the current matrix computation, while the other is used to receive shared memory fetch returns for the next warp-level matrix operation.
The following diagram illustrates the efficient, pipelined mainloop body used in CUTLASS GEMMs.
Threadblock Rasterization
To maximize reuse of data held in the last level cache, CUTLASS defines several functions to affect the mapping of threadblocks to logical partitions of the GEMM problem. These map consecutively launched threadblocks to packed two-dimensional regions of the partitioned GEMM problem to increase the probability that these will access the same tiles of global memory at approximately the same time.
Matrix product computations expose parallelism among O(MN) independent inner product computations. For sufficiently large problem sizes, a GEMM kernel in CUTLASS may approach the theoretical maximum computational throughput. For small problems, however, there are too few threadblocks to efficiently occupy the entire GPU.
As a recourse, parallelizing the reduction performed during the inner product computation enables more threadblocks to execute concurrently while still taking advantage of the throughput benefits of large threadblock-level GEMM tiles.
CUTLASS implements parallel reductions across threadblocks by partitioning the GEMM K dimension and launching an additional set of threadblocks for each partition. Consequently, we refer to this strategy within CUTLASS as “parallel reduction splitK.” The “parallel reduction splitK” strategy requires the execution of 2 kernels: partitionedK GEMM, and batched reduction.
PartitionedK GEMM resembles one flavor of batched strided GEMM. Instead of requiring users to specify the problem size of each batch, partitionedK GEMM asks for the overall problem size and the number of partitions that will be applied along the K dimension for operands A and B. For example, parameters of m=128, n=128, k=4096 and partition=16 will result in 16 batched strided GEMMs with each batch of m=128, n=128, k=256. PartitionedK also allows scenario where k is not divisible by the partition count.
For example, parameters of m=128, n=128, k=4096 and partition=20 will result in 20 batched strided GEMMs. The first 19 batches will have m=128, n=128, and k=4096/20=204, and the last batch will have m=128, n=128, and k=220.
The batched reduction kernel takes as input the output (C) of partitionedK GEMM, and performs a reduction along the K-dimension. Users must manage workspace memory to store this intermediate result.
Sliced K - reduction across warps
Similar to the split-k scenario, sliced-k aims at improving the efficiency of kernels with smaller M and N dimensions, but large K dimension. At the thread-block level, the parameters CtaTileN and CtaTileM expose parallelism by partitioning the work among warps. Larger warpTiles expose better instruction-level parallelism (ILP) and reuse, but also limit the number of warps running per threadblock, which reduces efficiency.
In order to improve efficiency in such scenarios, partitioning the warpTiles also along ctaTileK helps use the hardware more efficiently by allowing more warps to run concurrently in a CTA. Sliced-k kernels break down a threadblock’s computation among participating warps not just among the CtaTileN, CtaTileM dimension, but also the CtaTileK dimension. Thus, sliced-k entails a small cost in form of a reduction which has to happen at the end among the participating warps. This is because each warp computes using only a “slice” of CtaTileK, so each warp only has a partial sum before the reduction.
CUTLASS 3.x introduces CuTe, a library that simplifies thread-data organization by representing tensors of threads and data using a hierarchical layout representation, enabling developers to write high-performance CUDA code.
CuTe’s layout algebra allows users to build complicated layouts from simple known layouts or partition one layout across another, eliminating the need for hand-implemented complicated post-partitioned iteration schemes and supporting features like WGMMA on NVIDIA Hopper H100 and UMMA on NVIDIA Blackwell B200.
CuTe provides a unified interface for dense linear algebra on modern NVIDIA GPUs, abstracting away low-level details of tensor layout and thread mapping, and is used in CUTLASS 3.x to simplify the programming model and improve performance on NVIDIA GPUs.
It is now entering the next phase of development with a new Python interface. The fundamental abstractions introduced with the CUTLASS 3.x redesign are exposed directly in Python with CUTLASS 4.0. In this post, we discussed the design principles underlying CUTLASS 3.x, its core backend library, CUDA Tensors and Spatial Microkernels (CuTe), and optimization examples leveraging CuTe’s key features.
CUTLASS 3 introduced CuTe, a new library premised on the layout concept as a uniform and composable abstraction for describing and manipulating threads and data. By elevating layouts to a first-class citizen of the programming model, usage of CuTe greatly simplifies thread-data organization. CuTe reveals indexing logic to developers in an understandable and statically checkable way, while retaining the same high level of performance and Tensor Core operation coverage as in CUTLASS 2.x.
Beyond this more meaningful approach to layouts, CUTLASS 3 shares the same goals as all prior versions of CUTLASS — to help CUDA developers author high-performance GPU linear algebra kernels by developing an intuitive programming model around the latest hardware features. With this new major iteration, we emphasized the following:
The ability to customize any layer in the design of the library while preserving composability with other layers for developer productivity and cleaner separation of moving parts
Compile-time checks to ensure the correctness of kernel constructions. This guarantees that if it compiles, it will run correctly, with actionable static assert messages otherwise.
Reduce API surface area with fewer named types and a flatter learning curve with single points of entry that are also customization hooks.
Great performance on NVIDIA Hopper H100 and NVIDIA Blackwell B200 to use features such as WGMMA (for Hopper) or UMMA (for Blackwell), Tensor Memory Accelerator for Hopper (TMA), and threadblock clusters.
CuTe Core
At the heart of CUTLASS 3.x is CuTe, a new library to describe and manipulate tensors of threads and data.
CuTe is made of two parts: a powerful layout representation and an algebra of operations acting on those layouts.
特点
CuTe’s layout representation is natively hierarchical, naturally supports static and dynamic information, and is used to represent multidimensional tensors. The same layout representation is used to describe tensors of data and tensors of threads. Using the same vocabulary type across multiple independent resources shows the broad applicability of the CuTe Layout concept.
Building on this representational power, CuTe provides a formalized algebra of layouts that enable users to build complicated layouts from simple known layouts or to partition one layout across another layout. This lets programmers focus on the logical descriptions of their algorithms while CuTe does the mechanical bookkeeping for them. With these tools, users can quickly design, implement, and modify dense linear algebra algorithms.
Unlike any previous GPU programming model, the functional composition of threads and data tensors eliminates one of the most complex hurdles in GPU programming, which is that of consistently mapping a large set of threads to the data they operate upon. Once thread layouts have been described independently of the layouts of data they’ll be operating on, CuTe’s layout algebra can partition data across threads instead of having to hand implement complicated post-partitioned iteration schemes.
CuTe provides Layout and Tensor objects that compactly package the type, shape, memory space, and layout of data, while performing the complicated indexing for the user.
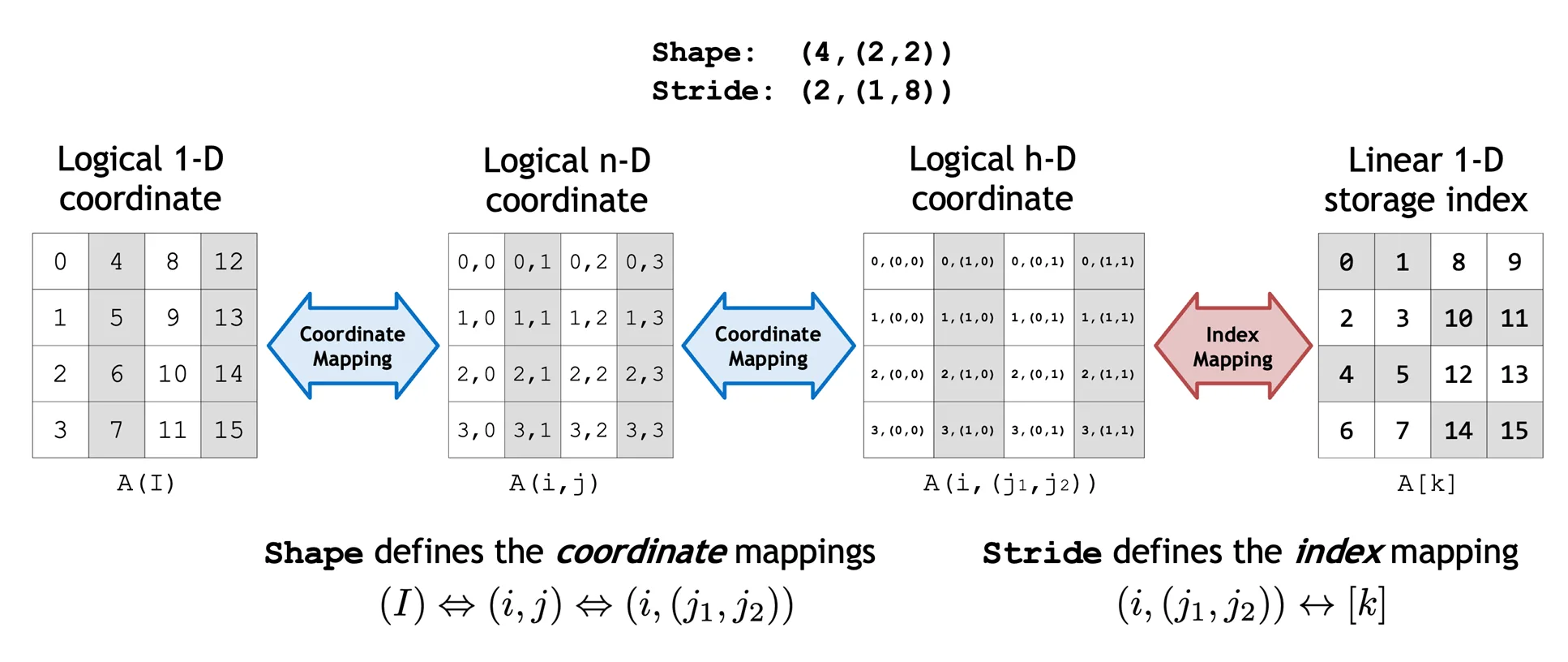
Layout<Shape,Stride> provides a map between logical coordinates within Shape and indices computed with Stride. (See Figure 1 as an example)
Shape defines one or more coordinate spaces and maps between them.
Stride defines the index map that converts coordinates to indices.
Tensor<Engine,Layout> provides the composition of a Layout with an iterator. The iterator may be a pointer to data in global memory, shared memory, register memory, or anything else that provides random access offset and dereference.
Figure 1. Multiple matrix types that can be manipulated by Shape and Stride functions to create indexes
It’s worth highlighting that layouts in CuTe are hierarchical and inspired by folding tensor operations in tensor algebra. As shown in the figure, the hierarchical Shape and Stride enable representations of layouts that go far beyond simple row-major and column-major. At the same time, hierarchical layouts can still be accessed just like a normal tensor (e.g., the logical 2-D coordinate shown), so these more advanced data layouts are abstracted over in algorithmic development.
CUTLASS 3.x uses a single vocabulary type (cute::Layout), resulting in a simplified, formalized, and uniform layout representation to help users write extremely fast kernels with great ease.
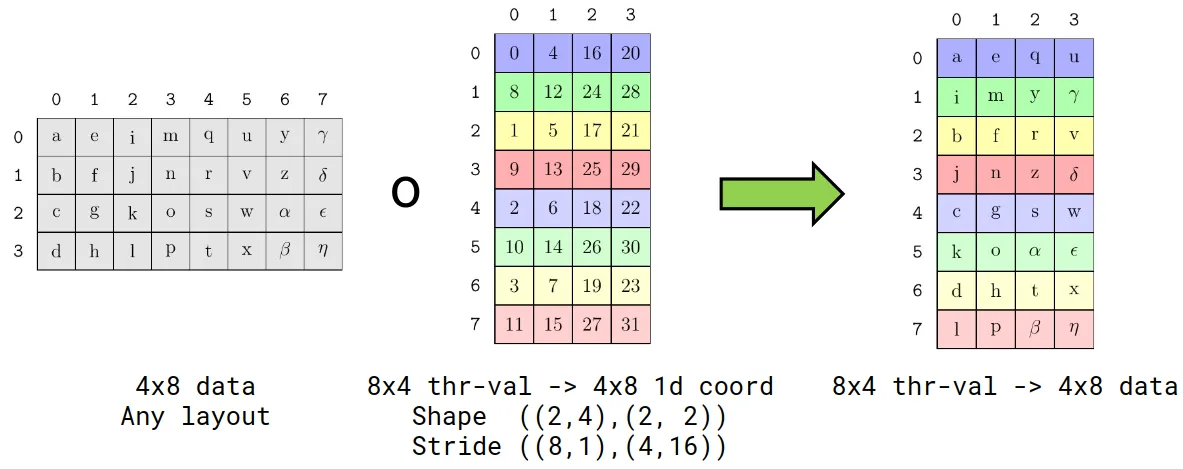
CuTe Layouts support functional composition as a core operation. Functional composition can be used to transform the shape and order of another layout. If we have a layout of data with coordinates (m,n) and we want to use coordinates (thread_idx,value_idx) instead, then we compose the data layout with a layout that describes the mapping (thread_idx,value_idx) → (m,n). The result is a layout of data with coordinates (thread_idx,value_idx), which we can use to access each value of each thread very easily!
As an example, consider a 4×8 layout of data. Further, suppose that we want to assign threads and values to each coordinate of that 4×8 data. We write a “TV layout” that records the particular partitioning pattern, then perform a functional composition between the data layout and the TV layout.
As shown, the composition permutes and reshapes the data such that each thread’s values are arranged across each row of the result. Simply slicing the result with our thread index completes the partitioning.
Figure 3. An example of how a 4×8 layout of data can be assigned a thread and value pair to help coordinate access to the 4×8 data. This is known as a “TV layout”
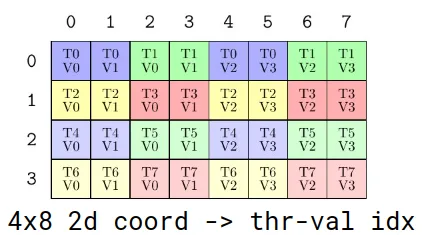
A more intuitive view of the partitioning pattern is the inverse of the TV layout.
Figure 4. Another 4×8 matrix representing how the original data can be mapped, the inverse of the TV layout
This layout shows the map from each coordinate within the 4×8 data layout to the thread and value. Arbitrary partitioning patterns can be recorded and applied to arbitrary data layouts. Additional documentation on CuTe Layout Algebra can be found on GitHub.
An atom is the smallest collection of threads and data that must cooperatively participate in the execution of a hardware-accelerated math or copy operation.
An Atom combines a PTX instruction with metadata about the shape and arrangement of threads and values that must participate in that instruction. This metadata is expressed as CuTe TV layouts that can then be used to partition arbitrary tensors of input and output data. A user should in general, not have to extend this layer, as we’ll provide implementations of CuTe atoms for new architectures.
统一数据分区:原子的 TV 布局元数据可直接用于“分割任意输入/输出张量”,确保线程组能精准获取计算所需的数据,避免数据分配混乱。
The above image shows the SM70_8x8x4_F32F16F16F32_NT instruction and its associated MMA_Traits metadata. On the left, the TV layouts mapping (thread_id,value_id) -> coord are recorded in the traits, and on the right, the traits are visualized with the inverse coord -> (thread_id,value_id) mapping. The image on the right can be generated with print_latex(make_tiled_mma(cute::SM70_8x8x4_F32F16F16F32_NT{}))
以 SM70_8x8x4_F32F16F16F32_NT 原子为例:
PTX 指令含义:针对 SM70 架构(如 Volta 系列 GPU),执行“8x8x4 尺寸的 MMA”,输入矩阵 A/B 为 F16 精度,累加矩阵 C 和输出矩阵 D 为 F32 精度,“NT”表示矩阵 A 按“非转置(Non-Transposed)”布局、矩阵 B 按“转置(Transposed)”布局。
Additional CuTe documentation on matrix multiply-accumulate (MMA) atoms is on GitHub.
CuTe Tiled MMAs
Tiled MMA and tiled copy are tilings of MMA atoms and copy atoms, respectively. We call this level “tiled” because it builds larger operations on top of the atoms as if fitting together individual tiles to build a reusable component of a mosaic. The tilings reproduce atoms across threads and data, with possible permutations and interleaving of the atoms as well.
This layer is most analogous to the warp-level tiling of MMA instructions in CUTLASS 2.x; however, it views the tiling from the perspective of all threads participating in the operation and generalizes the concept to copy operations as well. The purpose of this layer is to build composable GPU micro-kernels out of a plethora of hardware-accelerated math and data movement operations, each potentially with their own intrinsic layouts of threads and data. The tiled MMA and tiled Copy types present all these various hardware-accelerated CuTe atoms with a single, consistent API for partitioning data.
For example, CuTe might provide an MMA atom that users can call on a single warp, for fixed M, N, and K dimensions. We can then use CuTe operations make_tiled_mma to turn this atom into an operation that works on an entire thread block, for larger M, N, and K dimensions. We’ve already seen one example of a Tiled MMA in the previous section, the 1x1x1 tiling of SM70_8x8x4_F32F16F16F32_NT.
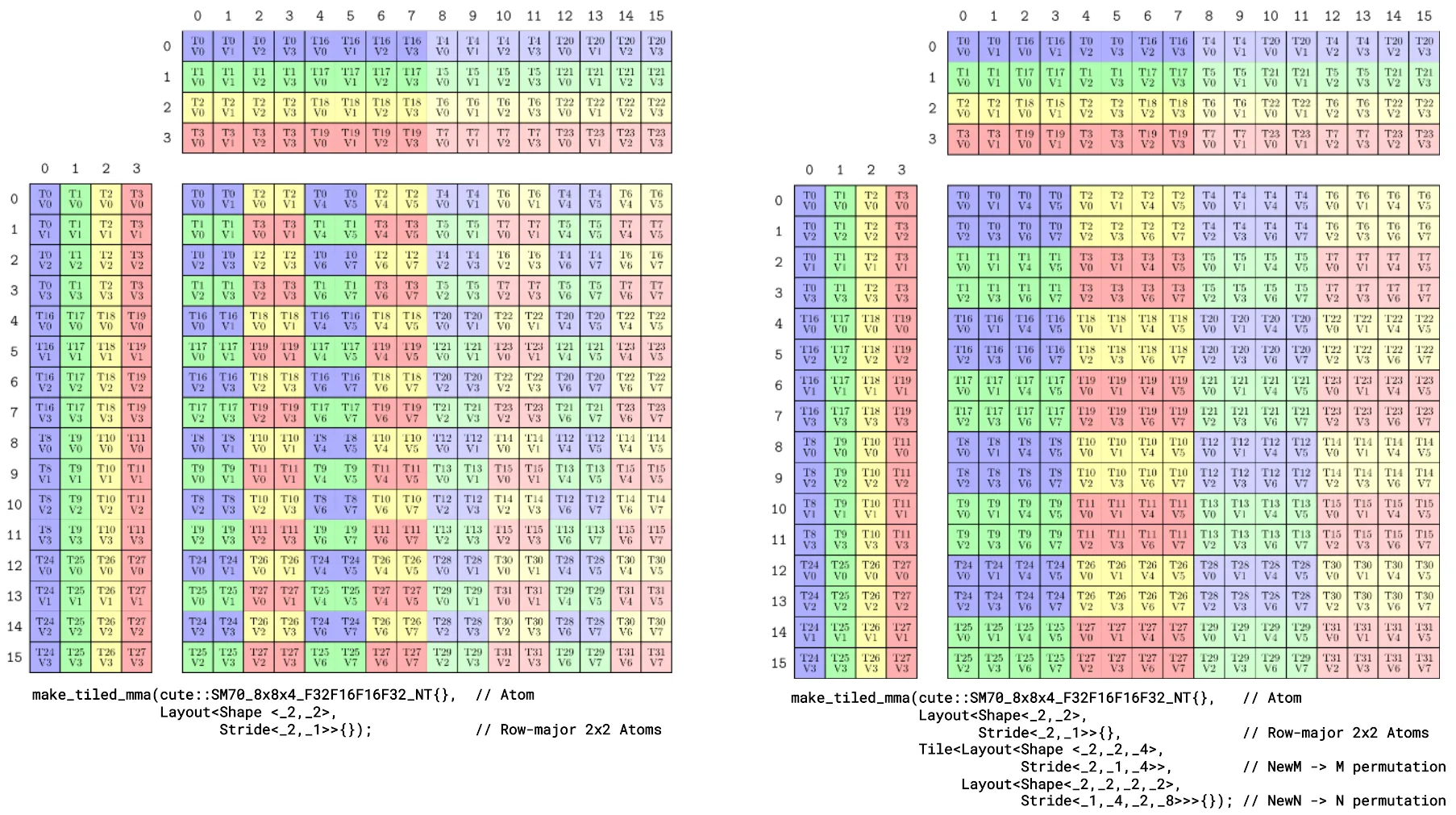
Figure 6. The above image shows two more tiled MMAs using the same SM70_8x8x4_F32F16F16F32_NT atom
This image shows two more tiled MMAs using the same SM70_8x8x4_F32F16F16F32_NT atom. On the left, four of these atoms are combined in a 2×2 row-major layout to produce a one-warp 16x16x4 MMA. On the right, four of these atoms are 2×2 row-major layouts to produce a one-warp 16x16x4 MMA, and then the rows (M) and the columns (N) are permuted to interleave the atoms. Both of these produce partitioning patterns that can be applied to any data layout, as demonstrated in the following section.
MMA Atom 是 CuTe 中最小粒度的硬件加速矩阵乘法单元,特点如下:
硬件绑定:针对特定 GPU 架构(如 SM70,即 Volta 架构)设计,直接调用硬件原生加速指令;
右图:在 2×2 排列基础上,对 M(行)、N(列)维度进行排列,实现 Atom 交错,适配不同数据布局需求;
统一接口:无论底层 MMA Atom 或 Copy Atom 的硬件布局、数据类型如何,Tiled 层都提供一致的 API 来划分数据,降低上层使用复杂度。
CuTe GEMMs and Mainloops
With the architecture agnostic tiled API, users can build a consistent interface to GEMM outer loops, with inner loops from the atom layer.
Tensor gA = . . . // Tile of 64x16 gmem for ATensor gB = . . . // Tile of 96x16 gmem for BTensor gC = . . . // Tile of 64x96 gmem for C// 64x16 static-layout padded row-major smem for ATensor sA = make_tensor(make_smem_ptr<TA>(smemAptr), Layout<Shape < _64,_16>, Stride<Int<17>, _1>>{});// 96x16 static-layout interleaved col-major smem for BTensor sB = make_tensor(make_smem_ptr<TB>(smemBptr), Layout<Shape <Shape <_32, _3>,_16>, Stride<Stride< _1,_512>,_32>>{});// Partition tensors across threads according to the TiledMMAThrMMA thr_mma = tiled_mma.get_slice(thread_idx);Tensor tCsA = thr_mma.partition_A(sA); // (MMA, MMA_M, MMA_K) smemTensor tCsB = thr_mma.partition_B(sB); // (MMA, MMA_N, MMA_K) smemTensor tCgC = thr_mma.partition_C(gC); // (MMA, MMA_M, MMA_N) gmem// Make register tensors the same shape/layout as aboveTensor tCrA = thr_mma.make_fragment_A(tCsA); // (MMA, MMA_M, MMA_K) rmemTensor tCrB = thr_mma.make_fragment_B(tCsB); // (MMA, MMA_N, MMA_K) rmemTensor tCrC = thr_mma.make_fragment_C(tCgC); // (MMA, MMA_M, MMA_N) rmem// COPY from smem to rmem thread-level partitionscute::copy(tCsA, tCrA);cute::copy(tCsB, tCrB);// CLEAR rmem thread-level partition (accumulators)cute::clear(tCrC);// GEMM on rmem: (V,M,K) x (V,N,K) => (V,M,N)cute::gemm(tiled_mma, tCrA, tCrB, tCrC);// Equivalent to// for(int k = 0; k < size<2>(tCrA); ++k)// for(int m = 0; m < size<1>(tCrC); ++m)// for(int n = 0; n < size<2>(tCrC); ++n)// tiled_mma.call(tCrA(_,m,k), tCrB(_,n,k), tCrC(_,m,n));// AXPBY from rmem to gmem thread-level partitionscute::axpby(alpha, tCrC, beta, tCgC);// Equivalent to// for(int i = 0; i < size(tCrC); ++i)// tCgC(i) = alpha * tCrC(i) + beta * tCgC(i)
There are now many decisions to be made for the above code regarding the temporal interleaving of compute and copy instructions
Allocate rmem as only A: (MMA,MMA_M) and B: (MMA,MMA_N) and C: (MMA,MMA_M,MMA_N) Tensors and copy to it on each k-block iteration.
Account for multiple k-tiles of gmem and copy to smem on each k-tile iteration.
Overlap the above copy stages with compute stages asynchronously.
Optimize by finding better layouts of smem that improve the access patterns for the smem → rmem copy.
Optimize by finding efficient TiledCopy partitioning patterns for the gmem → smem copy.
These concerns are considered part of the “temporal micro-kernels” rather than the “spatial micro-kernels” that CuTe provides. In general, decisions regarding the pipelining and execution of instructions over CuTe Tensors are left to the CUTLASS level and will be discussed in the next part of this series.
Summary
In summary, CuTe empowers developers to write more readable, maintainable, and high-performance CUDA code by abstracting away the low-level details of tensor layout and thread mapping, and providing a unified, algebraic interface for dense linear algebra on modern NVIDIA GPUs.
核心:CuTe is a collection of C++ CUDA template abstractions for defining and operating on hierarchically multidimensional layouts of threads and data.
组成:CuTe provides Layout and Tensor objects that compactly packages the type, shape, memory space, and layout of data, while performing the complicated indexing for the user.
优势:This lets programmers focus on the logical descriptions of their algorithms while CuTe does the mechanical bookkeeping for them. With these tools, we can quickly design, implement, and modify all dense linear algebra operations.
扩展:Layout: The core abstraction of CuTe are the hierarchically multidimensional layouts which can be composed with data arrays to represent tensors. The representation of layouts is powerful enough to represent nearly everything we need to implement efficient dense linear algebra. Layouts can also be combined and manipulated via functional composition, on which we build a large set of common operations such as tiling and partitioning.
需求:CuTe shares CUTLASS 3.x’s software requirements, including NVCC with a C++17 host compiler.
The cute::print function has overloads for almost all CuTe types, including Pointers, Integers, Strides, Shapes, Layouts, and Tensors. When in doubt, try calling print on it.
编译调试
The cute::print function has overloads for almost all CuTe types, including Pointers, Integers, Strides, Shapes, Layouts, and Tensors. When in doubt, try calling print on it.
也可以利用重载的 cout
CuTe’s print functions work on either host or device. Note that on device, printing is expensive.
You might also only want to print on thread 0 of each threadblock, or threadblock 0 of the grid. The thread0() function returns true only for global thread 0 of the kernel, that is, for thread 0 of threadblock 0. A common idiom for printing CuTe objects to print only on global thread 0.
if (thread0()) { print(some_cute_object);}
Some algorithms depend on some thread or threadblock, so you may need to print on threads or threadblocks other than zero. The header file cute/util/debug.hpp, among other utilities, includes the function bool thread(int tid, int bid) that returns true if running on thread tid and threadblock bid.
Some CuTe types have special printing functions that use a different output format.
The cute::print_layout function will display any rank-2 layout in a plain text table. This is excellent for visualizing the map from coordinates to indices.
The cute::print_tensor function will display any rank-1, rank-2, rank-3, or rank-4 tensor in a plain text multidimensional table. The values of the tensor are printed so you can verify the tile of data is what you expect after a copy, for example.
The cute::print_latex function will print LaTeX commands that you can use to build a nicely formatted and colored tables via pdflatex. This work for Layout, TiledCopy, and TiledMMA, which can be very useful to get a sense of layout patterns and partitioning patterns within CuTe.
Library Organization
CuTe is a header-only C++ library, so there is no source code that needs building. Library headers are contained within the top level include/cute directory, with components of the library grouped by directories that represent their semantics.
Meta-information for instructions in arch and utilities like partitioning and tiling.
库文件组织是 CuTe 的功能实现,下面将介绍 CuTe 提供的核心功能。
Layout
Fundamentally, a Layout maps from coordinate space(s) to an index space.
Layouts present a common interface to multidimensional array access that abstracts away the details of how the array’s elements are organized in memory. CuTe also provides an “algebra of Layouts.” Layouts can be combined and manipulated to construct more complicated layouts and to tile layouts across other layouts.
Integers
CuTe makes great use of dynamic (known only at run-time) and static (known at compile-time) integers.
Dynamic integers (or “run-time integers”) are just ordinary integral types like int or size_t or uint16_t. Anything that is accepted by std::is_integral<T> is considered a dynamic integer in CuTe.
Static integers (or “compile-time integers”) are instantiations of types like std::integral_constant<Value>. These types encode the value as a static constexpr member. They also support casting to their underlying dynamic types, so they can be used in expressions with dynamic integers. CuTe defines its own CUDA-compatibe static integer types cute::C<Value> along with overloaded math operators so that math on static integers results in static integers. CuTe defines shortcut aliases Int<1>, Int<2>, Int<3> and _1, _2, _3 as conveniences, which you should see often within examples.
CuTe attempts to handle static and dynamic integers identically. In the examples that follow, all dynamic integers could be replaced with static integers and vice versa. When we say “integer” in CuTe, we almost always mean a static OR dynamic integer.
CuTe provides a number of traits to work with integers.
cute::is_integral<T>: Checks whether T is a static or dynamic integer type.
cute::is_std_integral<T>: Checks whether T is a dynamic integer type. Equivalent to std::is_integral<T>.
cute::is_static<T>: Checks whether T is an empty type (so instantiations cannot depend on any dynamic information). Equivalent to std::is_empty.
cute::is_constant<N,T>: Checks that T is a static integer AND its value is equivalent to N.
A tuple is a finite ordered list of zero or more elements. The cute::tuple class behaves like std::tuple, but works on device and host. It imposes restrictions on its template arguments and strips down the implementation for performance and simplicity.
CuTe 提供在 host device 都支持的 tuple 类型,并做了限制以简化和性能。
IntTuple
CuTe defines the IntTuple concept as either an integer, or a tuple of IntTuples. Note the recursive definition. In C++, we define operations on IntTuple.
Examples of IntTuples include:
int{2}, the dynamic integer 2.
Int<3>{}, the static integer 3.
make_tuple(int{2}, Int<3>{}), the tuple of dynamic-2, and static-3.
make_tuple(uint16_t{42}, make_tuple(Int<1>{}, int32_t{3}), Int<17>{}), the tuple of dynamic-42, tuple of static-1 and dynamic-3, and static-17.
CuTe reuses the IntTuple concept for many different things, including Shape, Stride, Step, and Coord (see include/cute/layout.hpp).
Operations defined on IntTuples include the following.
rank(IntTuple): The number of elements in an IntTuple. A single integer has rank 1, and a tuple has rank tuple_size.
get<I>(IntTuple): The Ith element of the IntTuple, with I < rank. For single integers, get<0> is just that integer.
depth(IntTuple): The number of hierarchical IntTuples. A single integer has depth 0, a tuple of integers has depth 1, a tuple that contains a tuple of integers has depth 2, etc.
size(IntTuple): The product of all elements of the IntTuple.
We write IntTuples with parentheses to denote the hierarchy. For example, 6, (2), (4,3), and (3,(6,2),8) are all IntTuples.
A Layout is a tuple of (Shape, Stride). Semantically, it implements a mapping from any coordinate within the Shape to an index via the Stride.
Tensor
A Layout can be composed with data – e.g., a pointer or an array – to create a Tensor. The index generated by the Layout is used to subscript an iterator to retrieve the appropriate data.
A Layout is a pair of IntTuples: the Shape and the Stride. The first element defines the abstract shape of the Layout, and the second element defines the strides, which map from coordinates within the shape to the index space.
We define many operations on Layouts analogous to those defined on IntTuple.
rank(Layout): The number of modes in a Layout. Equivalent to the tuple size of the Layout’s shape.
get<I>(Layout): The Ith sub-layout of the Layout, with I < rank.
depth(Layout): The depth of the Layout’s shape. A single integer has depth 0, a tuple of integers has depth 1, a tuple of tuples of integers has depth 2, etc.
shape(Layout): The shape of the Layout.
stride(Layout): The stride of the Layout.
size(Layout): The size of the Layout function’s domain. Equivalent to size(shape(Layout)).
cosize(Layout): The size of the Layout function’s codomain (not necessarily the range). Equivalent to A(size(A) - 1) + 1.
Hierarchical Access Functions
IntTuples and Layouts can be arbitrarily nested. For convenience, we define versions of some of the above functions that take a sequence of integers, instead of just one integer. This makes it possible to access elements inside of nested IntTuple or Layout more easily. For example, we permit get<I...>(x), where I... is a “C++ parameter pack” that denotes zero or more (integer) template arguments. These hierarchical access functions include the following.
get<I0,I1,...,IN>(x) := get<IN>(...(get<I1>(get<I0>(x)))...). Extract the INth of the … of the I1st of the I0th element of x.
rank<I...>(x) := rank(get<I...>(x)). The rank of the I...th element of x.
depth<I...>(x) := depth(get<I...>(x)). The depth of the I...th element of x.
shape<I...>(x) := shape(get<I...>(x)). The shape of the I...th element of x.
size<I...>(x) := size(get<I...>(x)). The size of the I...th element of x.
In the following examples, you’ll see use of size<0> and size<1> to determine loops bounds for the 0th and 1st mode of a layout or tensor.
Constructing a Layout
代码见:
A Layout can be constructed in many different ways. It can include any combination of compile-time (static) integers or run-time (dynamic) integers.
The make_layout function returns a Layout. It deduces the types of the function’s arguments and returns a Layout with the appropriate template arguments. Similarly, the make_shape and make_stride functions return a Shape resp. Stride. CuTe often uses these make_* functions due to restrictions around constructor template argument deduction (CTAD) and to avoid having to repeat static or dynamic integer types.
When the Stride argument is omitted, it is generated from the provided Shape with LayoutLeft as default. The LayoutLeft tag constructs strides as an exclusive prefix product of the Shape from left to right, without regard to the Shape’s hierarchy. This can be considered a “generalized column-major stride generation”. The LayoutRight tag constructs strides as an exclusive prefix product of the Shape from right to left, without regard to the Shape’s hierarchy. For shapes of depth one, this can be considered a “row-major stride generation”, but for hierarchical shapes the resulting strides may be surprising. For example, the strides of s2xh4 above could be generated with LayoutRight.
The Shape:Stride notation is used quite often for Layout. The _N notation is shorthand for a static integer while other integers are dynamic integers. Observe that both Shape and Stride may be composed of both static and dynamic integers.
Also note that the Shape and Stride are assumed to be congruent. That is, Shape and Stride have the same tuple profiles. For every integer in Shape, there is a corresponding integer in Stride. This can be asserted with
GEMM optimization on GPUs is a modular problem. Performant implementations need to specify hyperparameters such as tile shapes, math and copy instructions, and warp-specialization schemes. These hyperparameters are, to a large extent, independent from each other; moreover, the best choices may vary significantly based on hardware, problem shape, or other user needs.
With the 3.x redesign, CUTLASS aimed to maximize coverage of the space of GEMM implementations through a hierarchical system of composable, orthogonal building blocks, while also improving code readability and extending support to later NVIDIA architectures such as Hopper and Blackwell. As this design philosophy is linked to the hierarchical hardware design of the GPU, it can also be a good choice for other GPU applications – for example, FlashAttention-3 uses familiar CUTLASS abstractions in its design.
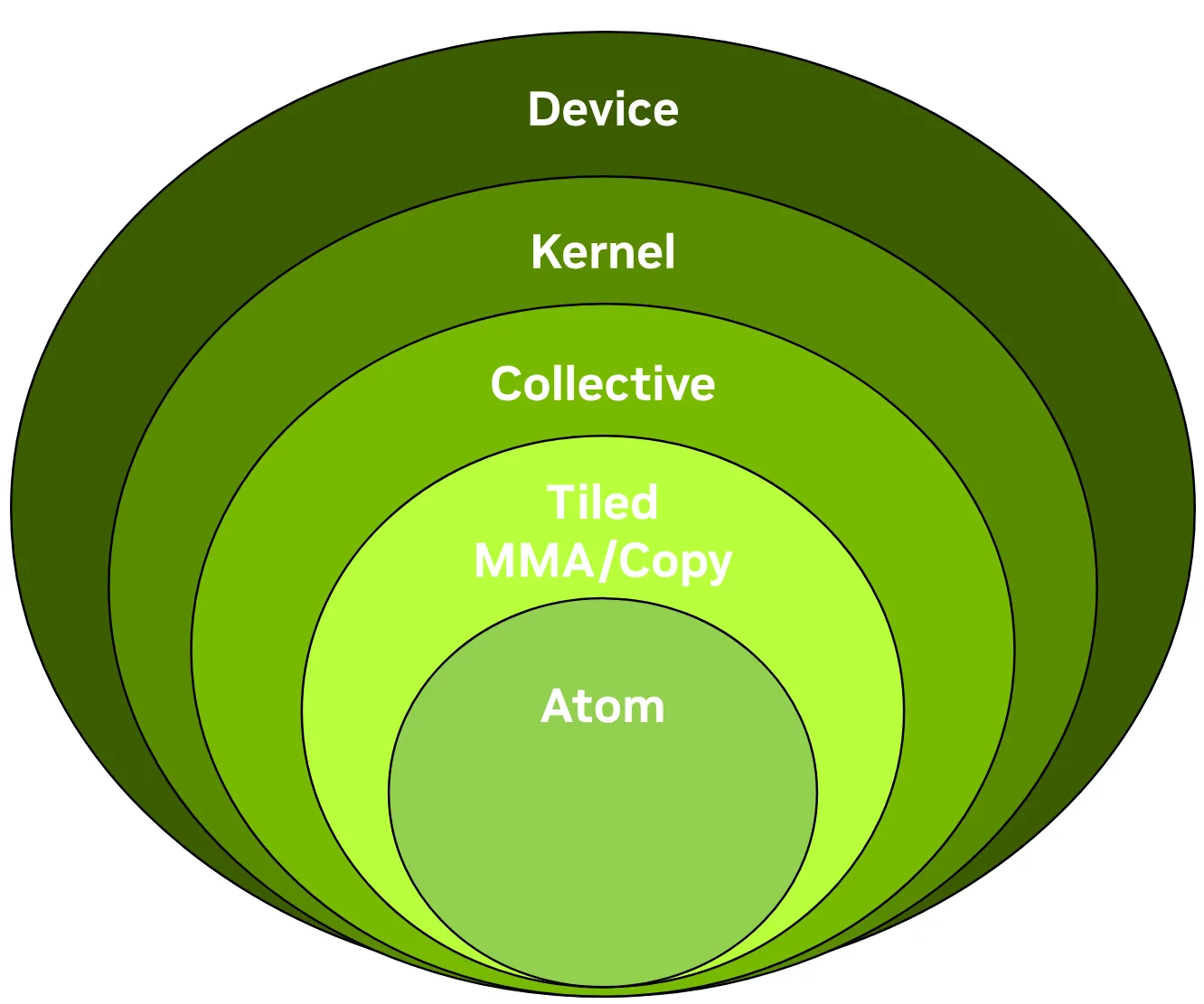
CUTLASS presents a uniform programming model for matrix multiply-accumulate (MMA) operations at different levels of the GPU system hierarchy. CUTLASS 3.0 has GEMM APIs corresponding to the following levels in order of highest to the lowest level.
Device
Kernel
Collective
Tiled MMA and Copy
Atom
这篇博客讲解 CUTLASS 3.x 中 GEMM 分层系统背后的设计原则,主要设计前 3 哥层次,并且会用到低级 CuTe 抽象来构建 GEMM 内核,关于下面两个层次见下文 CuTe an Introduction 以及对应的博客 part 1。
CUTLASS GEMM Model
CUTLASS implements algorithms that express the classical “triply nested loop” GEMM algorithm with a tiled structure mirroring the above hierarchy.
The following pseudocode describes the model for a GEMM kernel targeting a warp-synchronous matrix multiply instruction like mma.sync. The entire operation is referred to as “Gemm,” as it is assumed that an epilogue operation performs the general matrix update similar to BLAS.
// cutlass::gemm::kernel::GemmUniversal: ClusterTileM and ClusterTileN loops// are either rasterized by the hardware or scheduled by the kernel in persistent kernels.// Parallelism over thread block clustersfor (int cluster_m = 0; cluster_m < GemmM; cluster_m += ClusterTileM) { for (int cluster_n = 0; cluster_n < GemmN; cluster_n += ClusterTileN) { // cutlass::gemm::collective::CollectiveMma: mainloop that iterates over all k-tiles // No loop unrolling is performed at this stage for (int k_tile = 0; k_tile < size<2>(gmem_tensor_A); k_tile++) { // loops inside cute::gemm(tiled_mma, a, b, c); Dispatch 5: (V,M,K) x (V,N,K) => (V,M,N) // TiledMma uses the hardware instruction provided through its Mma_Atom // TiledMma's atom layout, value layout, and permutations define the iteration order for (int tiled_mma_k = 0; tiled_mma_k < size<2>(A); tiled_mma_k++) { for (int tiled_mma_m = 0; tiled_mma_m < size<1>(A); tiled_mma_m++) { for (int tiled_mma_n = 0; tiled_mma_n < size<1>(B); tiled_mma_n++) { // TiledMma's vector mode dispatches to the underlying instruction. mma.call(d, a, b, c); } // tiled_mma_n } // tiled_mma_m } // tiled_mma_k } // k_tile mainloop } // cluster_m} // cluster_n
The first three nested for loops correspond to parallelism over thread block clusters. The code does not actually express them as explicit for loops. Instead, the parallelization scheme over tiles is implied by CUDA grid launch semantics. However, for persistent kernels, these three loops are expressed in the source code as a single while loop that queries the work tile scheduler for problem tiles on which to compute.
Inside the three nested for loops, one finds code that pulls matrix tiles from global memory into more “local” memory (like shared memory or registers) and computes MMAs. These tiled copy and tiled mma iterations are generally fully static and get fully unrolled.
前三个嵌套的 for 循环对应于线程块集群上的并行性。代码实际上并没有将它们表示为显式的 for 循环。相反,基于瓦片的并行化方案是由 CUDA 网格启动语义暗示的。然而,对于持久内核,这三个循环在源代码中被表示为一个单独的 while 循环,该循环会向工作瓦片调度器查询要在其上进行计算的问题瓦片。
在这三个嵌套的 for 循环内部,可以看到将矩阵瓦片从全局内存提取到更“本地”的内存(如共享内存或寄存器)并计算矩阵乘法累加运算(MMAs)的代码。这些分块复制和分块矩阵乘法累加迭代通常是完全静态的,并会被完全展开。
A New Conceptual GEMM Hierarchy in CUTLASS 3.x
CUTLASS 3.x develops a conceptual GEMM hierarchy that’s independent of specific hardware features. It is structured into five layers:
Figure 1. Conceptual diagram of the CUTLASS GEMM hierarchy independent of hardware
CUTLASS expresses the above loop nest with the following components which are specialized for data type, layout, and math instruction.
API level
API Class and/or function names
Device
Host-side setup and interface
cutlass::gemm::device::GemmUniversalAdapter
Kernel
Device code for executing a kernel over a grid of threadblocks/clusters
cutlass::gemm::kernel::GemmUniversal
Collective
Temporal micro-kernels that use architecture-specific synchronization to orchestrate the execution of one or more spatial micro-kernels to compute a single output tile
Spatial micro-kernels that allow for arbitrary interleaving and tiling of architecture specific atoms
cute::TiledMma and cute::TiledCopy cute::gemm() and cute::copy()
Atom
Architecture-specific instructions, and associated meta-information
cute::Mma_Atom and cute::Copy_Atom
Each layer serves as a composition point for abstractions from the previous layer, which can be highly customized using template parameters. Users can either stick to the highest layers, trusting CUTLASS’s compile-time logic to provide a performant GEMM implementation, or opt in to advanced modifications exposed by lower levels of the hierarchy. The spatial micro-kernels provided by the Atom and Tiled MMA/Copy layers are the domain of CuTe and were discussed in part 1. The rest of this post will cover the temporal and kernel-level organization of GEMM made available in the higher layers.
GTC 2024
In CUTLASS 3.0, we assemble kernels by first composing a collective mainloop and collective epilogue together at the kernel layer, and then wrapping them with a host-side adapter to form a GEMM handle to that kernel.
The following sections describe these components in the order a user should instantiate them in order to assemble a kernel. This order is
assemble the required collective mainloop and epilogues,