CUTLASS (CUDA Templates for Linear Algebra Subroutines) is NVIDIA’s high-performance matrix multiplication library for CUDA that provides both C++ template abstractions and Python DSL interfaces for implementing fast matrix-matrix multiplication (GEMM) and related computations. The library decomposes these operations into reusable, modular software components that can be specialized and tuned via custom tiling sizes, data types, and algorithmic policies.
CUTLASS 4.0 introduces a dual-interface architecture:
- C++ Template API: Low-level template abstractions providing extensive control over kernel implementation
- Python DSL (CuTe DSL): High-level domain-specific language for rapid kernel development with native integration into deep learning frameworks
The library targets programmable, high-throughput Tensor Cores implemented by NVIDIA’s Ampere, Hopper, and Blackwell architectures, enabling developers to achieve performance comparable to vendor-provided libraries like cuBLAS and cuDNN.
README.md7-15 README.md28-38 README.md48-52
Architecture Overview
CUTLASS follows a layered architecture that supports both high-level Python DSL and low-level C++ template interfaces, with automatic kernel generation and hardware-specific optimizations.
Overall System Architecture
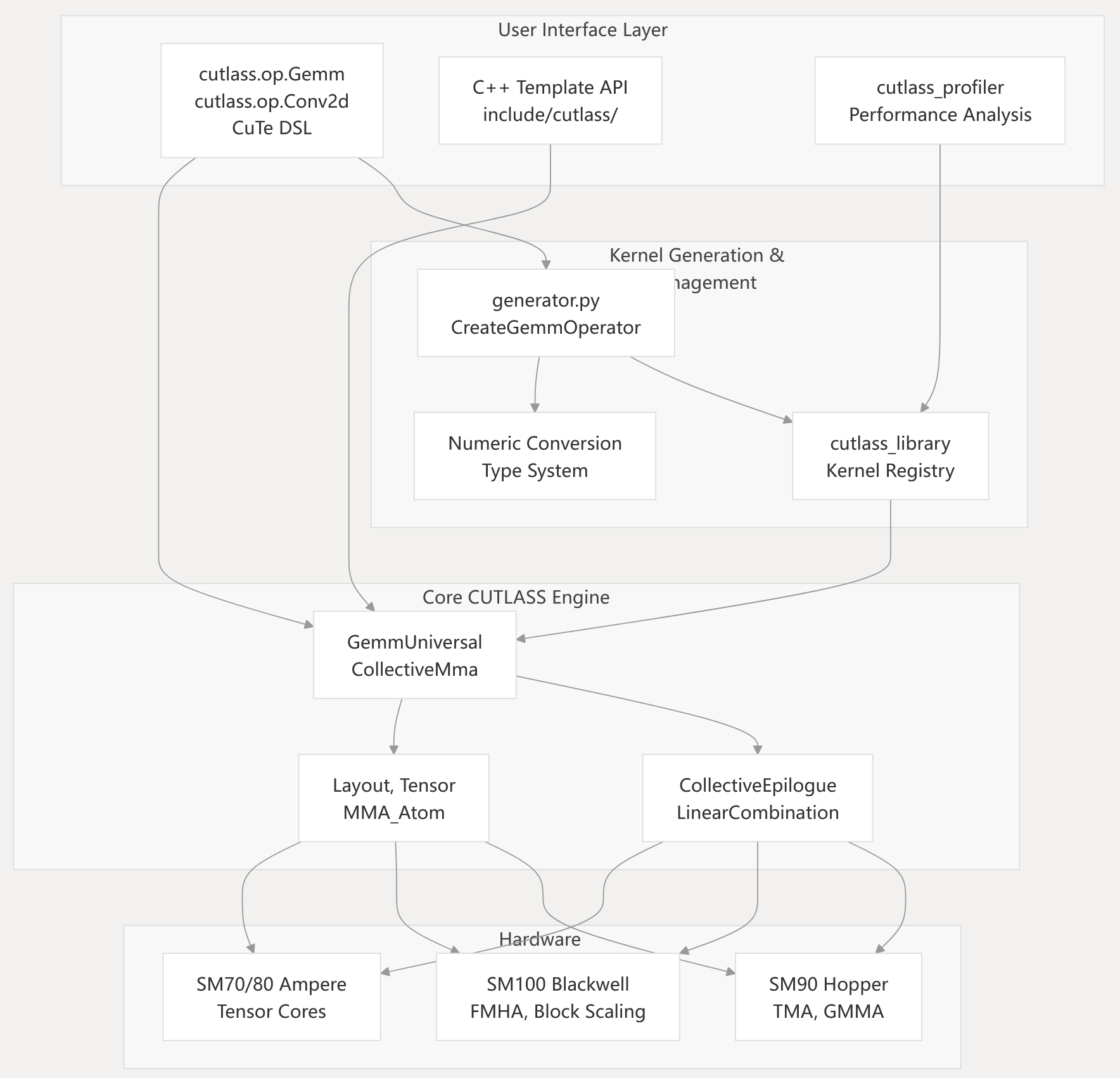
Sources: README.md48-52 python/cutlass/init.py140-143
Python Interface and DSL
CUTLASS 4.0 introduces CuTe DSL, a Python domain-specific language that provides high-level operation APIs while maintaining full performance parity with C++ implementations.
Python Operation APIs
The Python DSL provides:
- Rapid Prototyping: Orders of magnitude faster compile times compared to C++ templates
- Framework Integration: Native integration with PyTorch and other ML frameworks without glue code
- Intuitive Metaprogramming: High-level abstractions that don’t require deep C++ template expertise
- Performance Parity: Generated kernels achieve identical performance to hand-optimized C++ implementations
README.md28-38 python/cutlass/init.py140-143
GEMM Execution Pipeline
The CUTLASS GEMM operations follow a structured execution pipeline that transforms input arguments into a completed matrix multiplication operation. The pipeline involves several distinct phases:
Sources: include/cutlass/pipeline/sm90_pipeline.hpp32-102
Specialization Hierarchy
CUTLASS provides multiple specialized implementations of GEMM operations tailored to different GPU architectures, data types, and performance requirements.
Sources: include/cutlass/gemm/collective/sm90_mma_array_tma_gmma_rs_warpspecialized_mixed_input.hpp51-98
CuTe: CUDA Tensor Library
CUTLASS 3.0 introduced CuTe, a core library that provides abstractions for defining and operating on hierarchically multidimensional layouts of threads and data. CuTe is used extensively throughout CUTLASS to simplify the implementation of complex tensor operations.
Sources: README.md98-117
Data Types and Hardware Support
CUTLASS 4.0 provides extensive support for mixed-precision computations with specialized support for block-scaled data types introduced in CUTLASS 3.8+ for Blackwell architecture.
Data Types
| Category | Data Types | Architecture Support |
|---|---|---|
| Standard Floating Point | FP64, FP32, TF32, FP16, BF16 | All supported architectures |
| Low Precision FP | FP8 (e4m3, e5m2) | Hopper SM90+, Blackwell SM100+ |
| Block Scaled (New) | NVFP4, MXFP4, MXFP6, MXFP8 | Blackwell SM100+, SM120+ |
| Integer | INT4, INT8, signed/unsigned | Turing SM75+ |
| Binary | B1 (where supported) | Architecture dependent |
| Emulated | BF16x9 (FP32 emulation) | Blackwell SM100+ |
Hardware Architecture Support
| Architecture | Compute Capability | Key Features | CUDA Requirement |
|---|---|---|---|
| Volta | 7.0 | First Tensor Cores (FP16) | CUDA 11.4+ |
| Turing | 7.5 | INT4/INT8 Tensor Cores | CUDA 11.4+ |
| Ampere | 8.0, 8.6 | TF32, BF16, Sparse Tensor Cores | CUDA 11.4+ |
| Ada | 8.9 | Enhanced Tensor Cores | CUDA 11.8+ |
| Hopper | 9.0 | FP8, TMA, WGMMA, Thread Block Clusters | CUDA 11.8+ |
| Blackwell | 10.0, 10.1, 12.0 | Block-scaled types, FMHA, MLA | CUDA 12.8+ |
Family Specific Architecture Features
CUTLASS 4.0 supports Family Specific Architecture Features introduced in CUDA 12.9:
sm100f,sm101f,sm120ftargets allow running the same binary across chips in the same family- Enables deployment flexibility without recompilation for different Blackwell variants
README.md17-26 README.md68-69 README.md175-190
Performance
CUTLASS is designed to deliver near-peak theoretical performance for GEMM operations on NVIDIA GPUs. The library achieves high efficiency by leveraging architecture-specific features like Tensor Cores while providing flexibility through its template-based design.
When used to construct device-wide GEMM kernels, CUTLASS primitives exhibit excellent utilization of the GPU’s peak theoretical throughput. For example, on NVIDIA Blackwell architecture, CUTLASS achieves over 90% of peak performance for many data type combinations.
The library continues to improve with each release, incorporating optimizations for newer architectures and introducing features like Stream-K for better load balancing across SMs.
README.md78-96 media/images/cutlass-3.5.1-gemm-peak-performance.png
{kind=link}
{kind=link}
media/images/cutlass-3.5.1-gemm-peak-performance-fp8.png
Library Organization
CUTLASS 4.0 is organized into C++ template libraries, Python packages, tools, and examples that work together to provide both low-level and high-level interfaces.
Core Components Structure
Directory Structure
C++ Core Libraries:
include/cutlass/ # C++ template library
arch/ # Architecture features (SM90, SM100)
gemm/ # GEMM kernel implementations
collective/ # CollectiveMma, CollectiveEpilogue
kernel/ # GemmUniversal, tile schedulers
epilogue/ # Post-computation operations
conv/ # Convolution via implicit GEMM
include/cute/ # CuTe tensor abstractions
algorithm/ # Core tensor algorithms
atom/ # MMA_Atom, Copy_Atom
arch/ # Hardware-specific operations
Python Interface:
python/cutlass/ # High-level Python API
op/ # cutlass.op.Gemm, cutlass.op.Conv2d
backend/ # Compilation and execution backend
python/cutlass_library/ # Kernel generation system
generator.py # CreateGemmOperator functions
library_defaults.py # OptionRegistry implementation
python/CuTeDSL/ # CuTe DSL implementation
Tools and Utilities:
tools/profiler/ # Performance benchmarking
cutlass_profiler # Command-line profiling tool
tools/library/ # Pre-instantiated kernel library
tools/util/ # Utility classes and functions
README.md315-358 python/cutlass/init.py140-143
Functionality Evolution
CUTLASS evolves with each NVIDIA GPU architecture release, adding support for new hardware features and optimizations:
- Volta (SM70): First introduction of Tensor Cores with FP16 input/FP32 accumulation
- Turing (SM75): Added integer (INT4/INT8) tensor core operations
- Ampere (SM80): Added TF32, BF16, and sparse tensor operations
- Hopper (SM90): Added FP8 tensor operations, distributed GEMM, warp specialization
- Blackwell (SM100): Added block-scaled data types (NVFP4, MXFP4, etc.)
Each new architecture typically brings improvements in performance and efficiency for existing operations along with support for new data types and computational patterns.