Ch 20 Programming a Heterogeneous Computing Cluster
An introduction to CUDA streams
So far, we have focused on programming a heterogeneous computing system with one host and one device. In high-performance computing (HPC), applications require the aggregate computing power of a cluster of computing nodes. Many of the HPC clusters today have one or more hosts and one or more devices in each node. Historically, these clusters have been programmed predominately with Message Passing Interface (MPI).
In this chapter we will present an introduction to joint MPI/CUDA programming. We will present only the MPI concepts that programmers need to understand to scale their heterogeneous applications to multiple nodes in a cluster environment. In particular, we will focus on domain partitioning, point-to-point communication, and collective communication in the context of scaling a CUDA kernel into multiple nodes.
Using joint MPI/CUDA programming to scale a CUDA kernel into multiple nodes.
20.1 Background
Although practically no top supercomputers used GPUs before 2009, the need for better energy efficiency has led to fast adoption of GPUs in recent years. Many of the top supercomputers in the world today use both CPUs and GPUs in each node. The effectiveness of this approach is validated by their high rankings in the Green 500 list, which reflects their high energy efficiency.
GPUs offer better energy efficiency.
The dominating programming interface for computing clusters today is MPI (Gropp et al., 1999), which is a set of API functions for communication between processes running in a computing cluster. MPI assumes a distributed memory model in which processes exchange information by sending messages to each other. When an application uses API communication functions, it does not need to deal with the details of the interconnect network. The MPI implementation allows the processes to address each other using logical numbers, in much the same way as using phone numbers in a telephone system: Telephone users can dial each other using phone numbers without knowing exactly where the called person is and how the call is routed.
MPI assumes a distributed memory model where processes exchange information by sending messages.
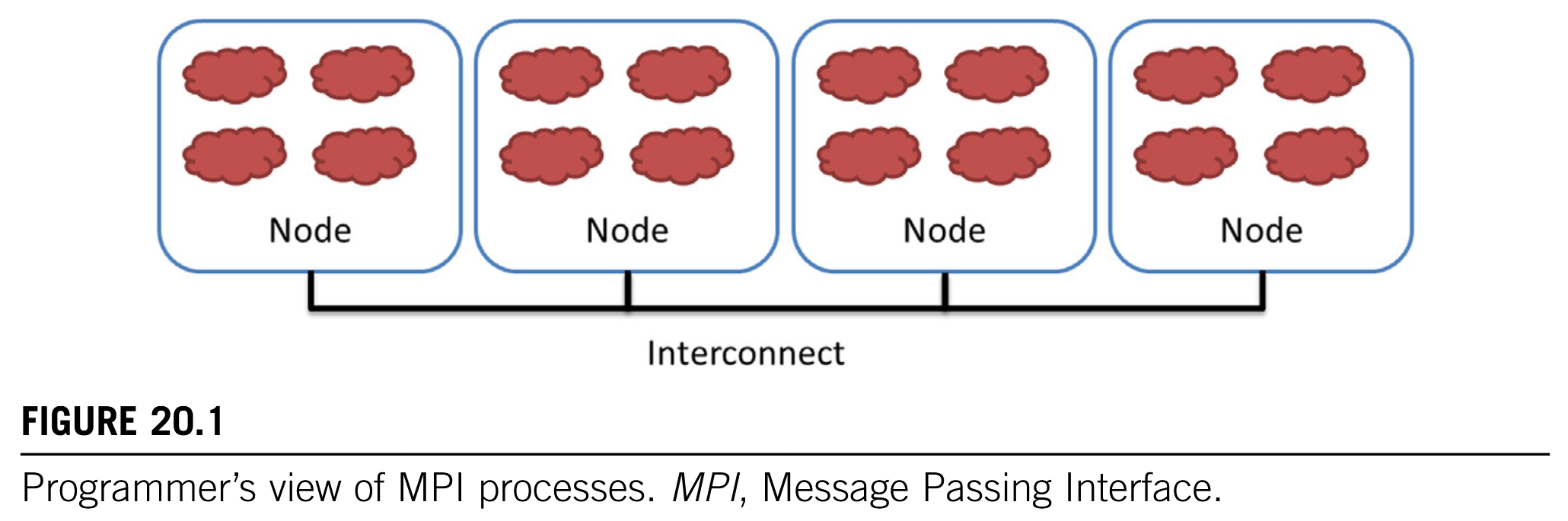
In a typical MPI application, data and work are partitioned among processes. As is shown in Fig. 20.1, each node can contain one or more processes, shown as clouds within nodes. As these processes progress, they may need data from each other. This need is satisfied by sending and receiving messages. In some cases, the processes also need to synchronize with each other and generate collective results when collaborating on a large task. This is done with collective communication API functions.
Transfer data by sending and receiving messages, synchronize via collective communication APIs.
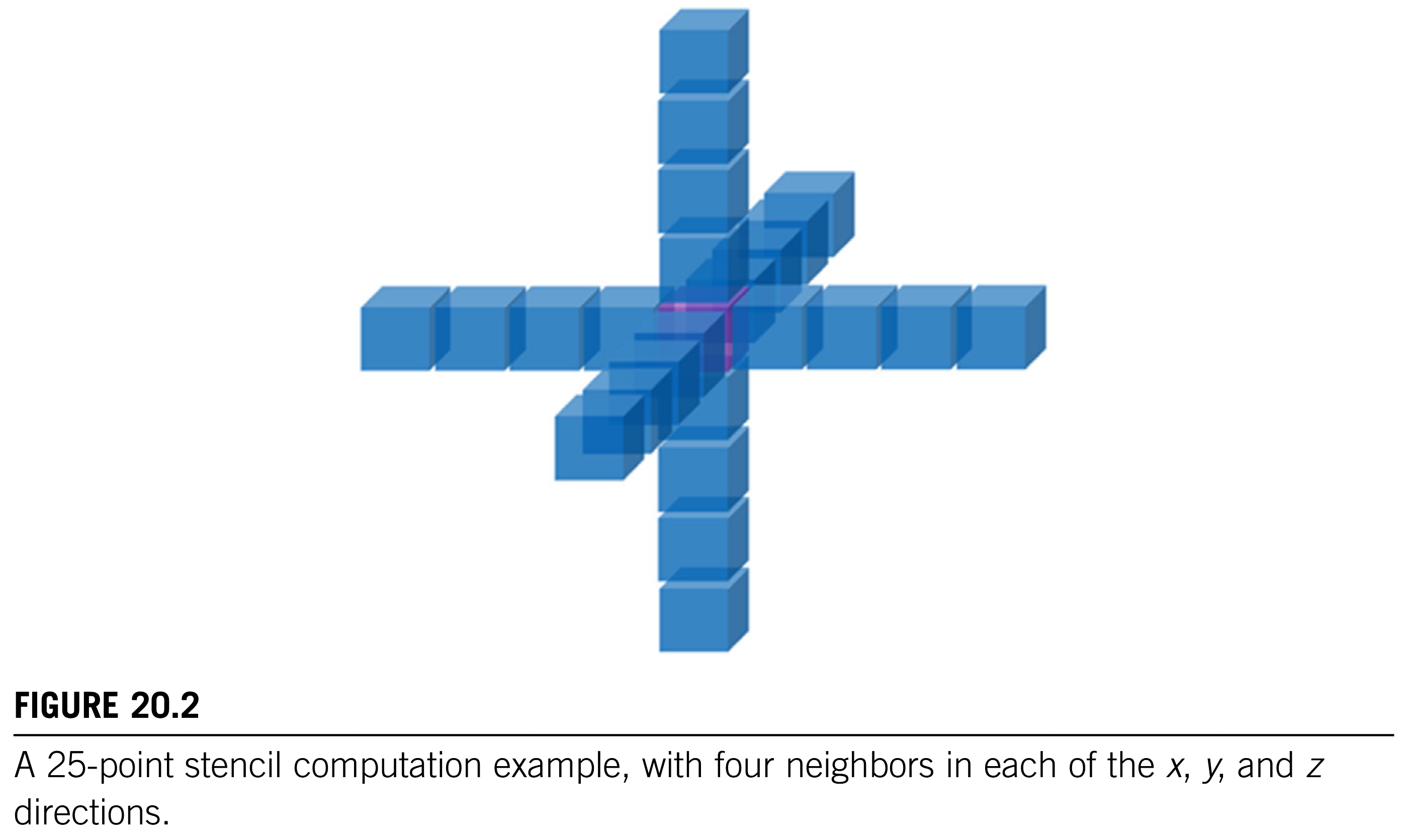
20.2 A Running Example (TODO)
20.3 Message Passing Interface Basics
Like CUDA, MPI programs are based on the SPMD parallel programming model.
All MPI processes execute the same program. The MPI system provides a set of API functions to establish communication systems that allow the processes to communicate with each other. Fig. 20.5 shows five essential MPI functions that set up and tear down the communication system for an MPI application.

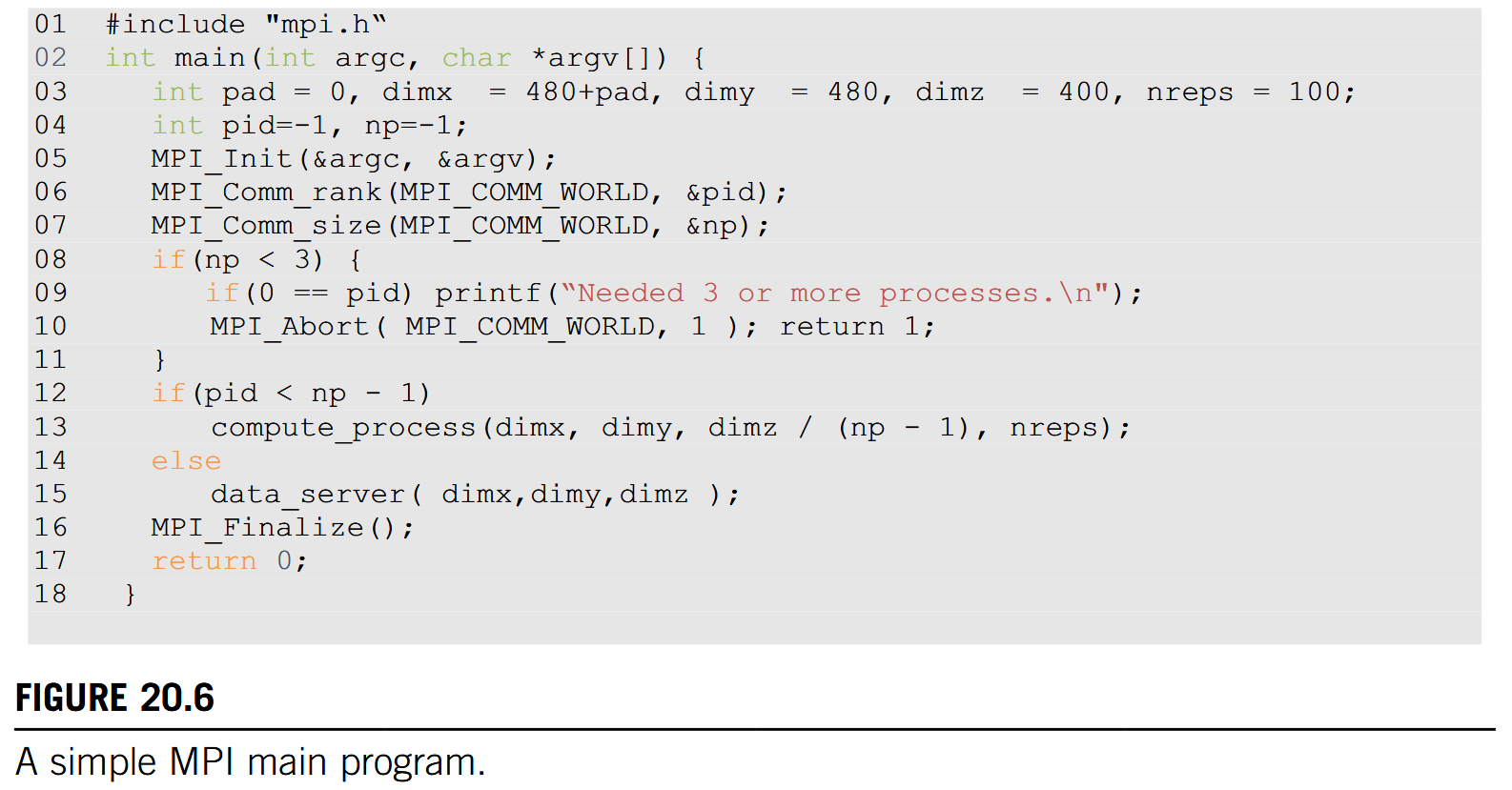
We will use a simple MPI program, shown in Fig. 20.6, to illustrate the usage the API functions. To launch an MPI application in a cluster, a user needs to supply the executable file of the program to the mpirun command or the mpiexec command in the login node of the cluster. Each process starts by initializing the MPI runtime with an MPI_Init () call (line 05). This initializes the communication system for all the processes that are running the application. Once the MPI runtime has been initialized, each process calls two functions to prepare for communication. The first function is MPI_Comm_rank () (line 06), which returns a unique number to each calling process, which is called the MPI rank or process id for the process. The numbers that are received by the processes vary from 0 to the number of processes minus 1. The MPI rank for a process is analogous to the expression blockIdx.x * blockDim.x + threadIdx.x for a CUDA thread. It uniquely identifies the process in a communication, which is also equivalent to the phone number in a telephone system. The main differences are that MPI ranks are one-dimensional.
Interested readers should refer to the MPI reference manual (Gropp et al., 1999 [1]) for details on creating and using multiple communicators in an application, in particular the definition and use intracommunicators and intercommunicators.
MPI_Comm_rank ()
The MPI_Comm_rank () function in line 06 of Fig. 20.6 takes two parameters.
The first is an MPI built-in type MPI_Comm that specifies the scope of the request, that is, the collection of processes that form the group identified by a MIP_Comm variable. Each variable of the MPI_comm type is commonly referred to as a communicator. MPI_Comm and other MPI built-in types are defined in the “mpi. h” header file (line 01), which should be included in all C program files that use MPI. An MPI application can create one or more communicators, each of which is a group of MPI processes for the purpose of communication. MPI_Comm_rank () assigns a unique id to each process in a communicator. In Fig. 20.6 the parameter value that is passed is MPI_COMM_WORLD, which is used as a default and means that the communicator includes all MPI processes that are running the application.
A communicator defines the communication scope (i.e., a group of processes) for MPI processes and provide unique identifiers for processes within the group to enable communication.
The second parameter of the MPI_Comm_rank () function is a pointer to an integer variable into which the function will deposit the returned rank value. In Fig. 20.6 a variable pid is declared for this purpose. After the MPI_Comm_rank () has returned, the pid variable will contain the unique id for the calling process.
MPI_Comm_size ()
The second API function is MPI_Comm_size () (line 07), which returns the total number of MPI processes running in the communicator. The MPI_Comm_size () function takes two parameters.
The first one is of MPI_Comm type that gives the scope of the request. In Fig. 20.6 the parameter value that is passed in is MPI_COMM_WORLD, which means that the scope of the MPI_Comm_size () is all the processes in the application. Since the scope is all MPI processes, the returned value is the total number of MPI processes that are running the application. This value is configured by the user when the application is executed by using the mpirun command or the mpiexec command. However, the user may not have requested a sufficient number of processes. Also, the system may or may not be able to create all the processes that the user requested. Therefore it is a good practice for an MPI application program to check the actual number of processes that are running.
The second parameter is a pointer to an integer variable into which the MPI_Comm_size() function will deposit the return value. In Fig. 20.6 a variable np is declared for this purpose. After the function returns, the variable np contains the number of MPI processes that are running the application. In Fig. 20.6 we assume that the application requires at least 3 MPI processes. Therefore it checks whether the number of processes is at least 3 (line 08). If not, it calls MPI_Comm_abort() function to terminate the communication connections and return with an error flag value 1 (line 10).
Fig. 20.6 also shows a common pattern for reporting errors or other chores. There are multiple MPI processes, but we need to report the error only once. The application code designates the process with pid = 0 to do the reporting (line 09). This is similar to the pattern in CUDA kernels in which some tasks need to be done by only one of the threads in a thread-block.
MPI_Comm_abort ()
As is shown in Fig. 20.5, the MPI_Comm_abort () function takes two parameters (line 10). The first sets the scope of the request. In Fig. 20.6 the scope is set as MPI_COMM_WORLD, which means all MPI processes that are running the application. The second parameter is a code for the type of error that caused the abort. Any number other than 0 indicates that an error has happened.
Perform the Calculation
If the number of processes satisfies the requirement, the application program goes on to perform the calculation. In Fig. 20.6, the application uses np - 1 processes (pid from 0 to np - 2) to perform the calculation (lines 12 13) and one process (the last one whose pid is np - 1) to perform I/O service for the other processes (lines 14 15). We will refer to the process that performs the I/O services as the data server and the processes that perform the calculation as compute processes. In Fig. 20.6, if the pid of a process is within the range from 0 to np - 2, it is a compute process and calls the compute_process () function (line 13). If the process pid is np - 1, it is the data server and calls the data_server () function (line 15). This is similar to the pattern in which threads perform different actions according to their thread ids.
After the application has completed its computation, it notifies the MPI runtime with a call to MPI_Finalize (), which frees all MPI communication resources that are allocated to the application (line 16). The application can then exit with a return value 0, which indicates that no error has occurred (line 17).
20.4 Message Passing Interface Point-to-point Communication
MPI supports two major types of communication. The first is the point-to-point type, which involves one source process and one destination process. The source process calls the MPI_Send() function, and the destination process calls the MPI_Recv () function. This is analogous to a caller dialing a call and a receiver answering a call in a telephone system.
Point-to-point communication involves one source process and one destination process.
MPI_Send()
Fig. 20.7 shows the syntax for using the MPI_Send () function.
- The first parameter is a pointer to the starting location of the memory area where the data to be sent can be found.
- The second parameter is an integer that gives that number of data elements to be sent.
- The third parameter is of the MPI built-in type
MPI_Datatype. It specifies the type of each data element that is being sent as far as the MPI library implementation is concerned. The values that can be held by a variable or argument of theMPI_Datatypeare defined inmpi. hand includeMPI_DOUBLE(double-precision floating-point),MPI_FLOAT(single-precision floating-point),MPI_INT(integer), andMPI_CHAR(character). The exact sizes of these types depend on the size of the corresponding C types in the host processor. See the MPI reference manual for more sophisticated use of MPI types (Gropp et al., 1999 [1]). - The fourth parameter for
MPI_Send ()is an integer that gives the MPI rank of the destination process. - The fifth parameter gives a tag that can be used to classify the messages that are sent by the same process. The sixth parameter is a communicator that specifies the context in which the destination MPI rank is defined.

MPI_Recv ()
Fig. 20.8 shows the syntax for using the MPI_Recv () function.
- The first parameter is a pointer to the area in memory where the received data should be deposited.
- The second parameter is an integer that gives the maximum number of elements that the
MPI_Recv ()function is allowed to receive. - The third parameter is an
MPI_Datatypethat specifies the type of each element to be received. - The fourth parameter is an integer that gives the process id of the source of the message.
- The fifth parameter is an integer that specifies the tag value that is expected by the destination process. If the destination process does not want to be limited to a particular tag value, it can use
MPI_ANY_TAG, which means that the receiver is willing to accept messages of any tag value from the source.
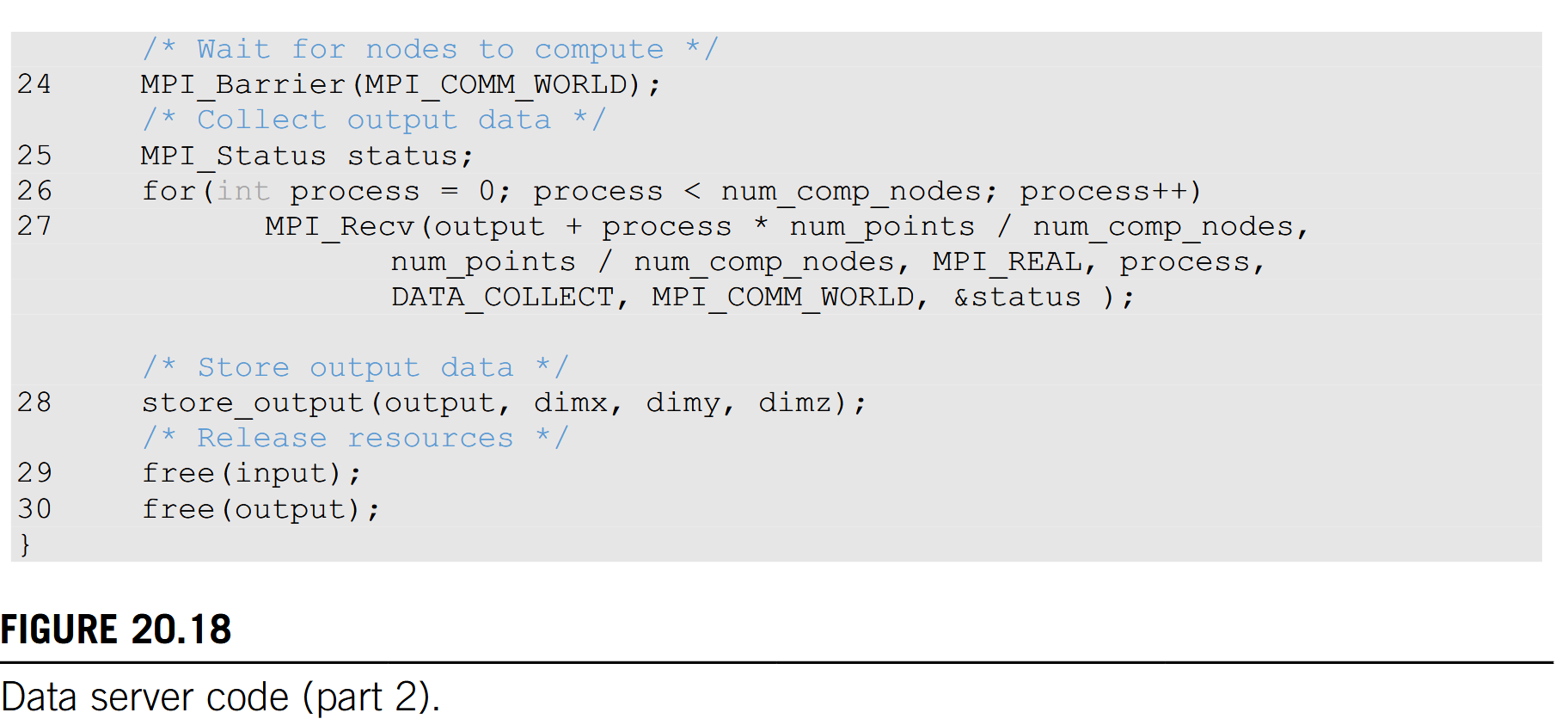
Data Server as an Example TODO
We will first use the data server to illustrate the use of point-to-point communication. In a real application the data server process would typically perform data input and output operations for the compute processes. However, input and output have too much system-dependent complexity. Since I/O is not the focus of our discussion, we will avoid the complexity of I/O operations in a cluster environment. That is, instead of reading data from a file system, we will just have the data server initialize the data with random numbers and distribute the data to the compute processes. The first part of the data server code is shown in Fig. 20.9.
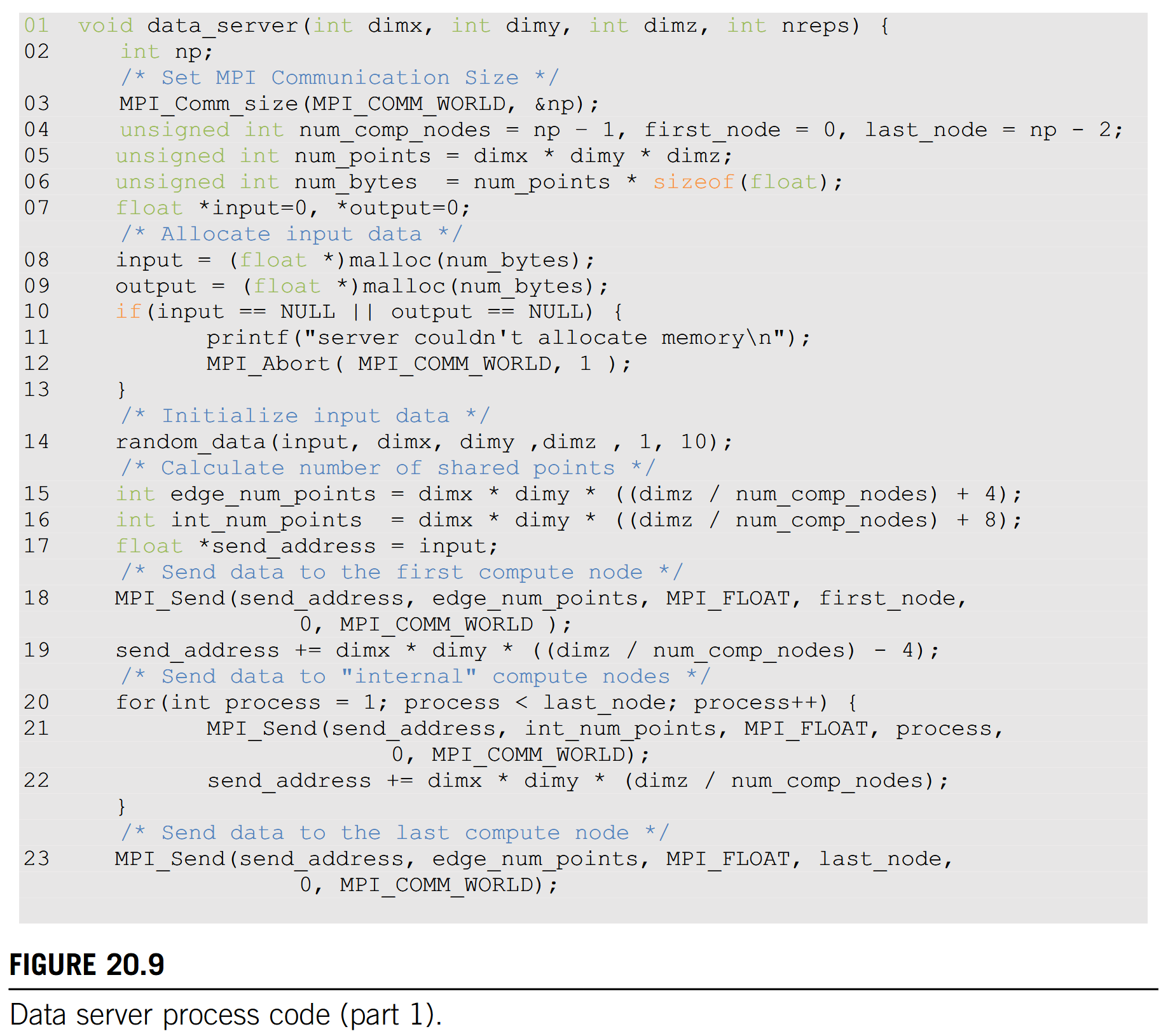
The data server function takes four parameters. The first three parameters specify the size of the 3D grid: the number of elements in the x dimension, dimx; the number of elements in the y dimension, dimy; and the number of elements in the z dimension, dimz. The fourth parameter specifies the number of iterations that need to be done for all the data points in the grid.
20 .5 Overlapping Computation and Communication TODO
A simple way to perform the computation steps is for each compute process to perform a computation step on its entire partition, exchange halo data with the left and right neighbors, and repeat. While this is a very simple strategy, it is not very effective. The reason is that this strategy forces the system to be in one of the two modes. In the first mode, all compute processes are performing computation steps. During this time, the communication network is not used. In the second mode, all compute processes are exchanging halo data with their left and right neighbors. During this time, the computation hardware is not well utilized. Ideally, we would like to achieve better performance by utilizing both the communication network and the computation hardware all the time. This can be achieved by dividing the computation tasks of each compute process into two stages, as illustrated in Fig. 20.12.
Achieve better performance by utilizing both the communication network and the computation hardware
20.6 Message Passing Interface Collective Communication
We saw an example of the MPI collective communication API in the previous section: MPI_Barrier. The other commonly used group collective communication types are broadcast, reduce, gather, and scatter (Gropp et al., 1999 [1]).
Barrier synchronization MPI_Barrier () is perhaps the most commonly used collective communication function. As we saw in the stencil example, barriers are used to ensure that all MPI processes are ready before they begin to interact with each other. We will not elaborate on the other types of MPI collective communication functions, but we encourage the reader to read the details of these functions. In general, collective communication functions are highly optimized by the MPI runtime developers and system vendors. Using them usually leads to better performance as well as readability and productivity than trying to achieve the same functionality with combinations of send and receive calls.
Barriers ensure that all MPI processes are ready before they begin to interact with each other.
See more in the reference manul.
TODO
20 .8 Summary
In this chapter we covered basic patterns of joint CUDA/MPI programming for HPC clusters with heterogeneous computing nodes.
- All processes in an MPI application run the same program. However, each process can follow different control flow and function call paths to specialize their roles, as illustrated by the data server and the compute processes in our example.
- We also used the stencil pattern to show how compute processes exchange data.
- We presented the use of CUDA streams and asynchronous data transfers to enable the overlap of computation and communication.
- We also showed how to use the MPI barrier to ensure that all processes are ready to exchange data with each other.
- Finally, we briefly outlined the use of CUDA-aware MPI to simplify the exchange of data in the device memory.
We would like to point out that while MPI is a very different programming system, all major MPI concepts that we covered in this chapter, namely, SPMD, MPI ranks, and barriers, have counterparts in the CUDA programming model. This confirms our belief that by teaching parallel programming well with one model, our students can quickly and easily pick up other programming models. We would like to encourage the reader to build on the foundation provided by this chapter and study more advanced MPI features and other important patterns.
References
- Gropp, W., Lusk, E., Skjellum, A., 1999. Using MPI, Portable Parallel Programming with the Message Passing Interface, 2nd Ed. MIT Press, Cambridge, MA, Scientific and Engineering Computation Series. ISBN 978-0-262 57132-6.