对应 https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html
本文参考:
- NVIDIA CUDA C++ Programming Guide 第 7、9 、20章,硬件架构和算力发展
- Professional CUDA C Programming 第 章
- 一个直观学习汇编的网站
第四章 硬件实现
NVIDIA GPU 架构围绕着可扩展的多线程流式多处理器 Streaming Multiprocessors (SMs) 阵列构建。当主机 CPU 上的 CUDA 程序调用内核 grid 时,grid 的 block 会被枚举并分配给具有可用执行能力的 SM。block 中的 thread 在一个多处理器上并发执行,并且多个 block 可以在一个 SM 上并发执行。随着 block 执行结束,新的 block 会在空闲的 SM 上启动。
多处理器旨在同时执行数百个线程。为了管理如此大量的线程,它采用了一种名为单指令多线程 SIMT (Single-Instruction, Multiple-Thread) 的独特架构,该架构在 SIMT Architecture 中有描述。指令采用流水线方式执行,利用单个线程内的指令级并行性,以及通过 Hardware Multithreading 中详述的同步硬件多线程实现广泛的线程级并行性。与 CPU 内核不同,这些指令按顺序发出,不存在分支预测或推测执行。
SIMT Architecture 和 Hardware Multithreading 描述了所有设备通用的流式多处理器的架构特性,关于架构的算力,见 Compute Capability。
NVIDIA GPU 架构使用小端模式。
SIMT 架构
多处理器以 32 个并行线程为一组创建、管理、调度和执行线程,这些线程组称为线程束 warps。组成一个线程束的各个线程从相同的程序地址一起启动,但它们有自己的指令地址计数器和寄存器状态,因此可以自由分支并独立执行。术语线程束源于最早的并行线程技术——编织。half-warp 是指一个线程束的前半部分或后半部分。quarter-warp 是指一个线程束的前四分之一、第二个四分之一、第三个四分之一或第四个四分之一。
warp 是 GPU 调度的 “最小单元”
当一个 SM 被分配一个或多个 block 来执行时,它会将这些 block 划分成 warp,每个 warp 由一个 warp scheduler 调度执行。将 block 划分为 warp 的方式始终相同;每个 warp 包含连续递增的线程 ID 的线程,第一个线程束包含线程 0。Thread Hierarchy 描述了线程 ID 与线程块中的线程索引之间的关系。
一个 warp 每次执行一条公共指令,因此当一个 warp 的所有 32 个线程在执行路径上达成一致时,就能实现最高效率。如果一个 warp 的线程通过数据相关的条件分支发生分歧,该 warp 会执行所采用的各个分支路径,并禁用不在该路径上的线程。分支分歧仅发生在一个线程束内;不同的线程束独立执行,无论它们执行的是相同还是不同的代码路径。
单指令多线程(SIMT)架构与单指令多数据(SIMD)向量组织类似,即 一条指令控制多个处理单元。一个关键区别在于,SIMD 向量组织会向软件暴露 SIMD 宽度,而 SIMT 指令指定单个线程的执行和分支行为。与 SIMD 向量机相比,SIMT 使程序员能够为独立的标量线程编写线程级并行代码,以及为协同线程编写数据并行代码。为确保正确性,程序员基本上可以忽略 SIMT 行为;然而,通过确保代码极少需要线程束(warp)中的线程发生分支发散(diverge),可以实现显著的性能提升。在实际应用中,这与传统代码中缓存行(cache line)的作用类似:在追求代码正确性的设计阶段,缓存行大小可安全忽略,但在追求峰值性能的代码结构设计中,则必须将其纳入考量。另一方面,向量架构(vector architectures)要求软件将加载操作合并(coalesce)为向量形式,并手动管理分支发散问题。
在 Volta 架构之前,warp 使用一个在该 warp 所有 32 个线程间共享的程序计数器,以及一个指定该 warp 活跃线程的活跃掩码。因此,处于分歧区域或不同执行状态的同一线程束中的线程无法相互发信号或交换数据,并且,根据竞争线程所属的线程束不同,需要由锁或互斥锁保护的细粒度数据共享的算法很容易导致死锁。
从 Volta 架构开始,独立线程调度 Independent Thread Scheduling 允许线程之间实现完全并发,无论线程束如何。借助独立线程调度,GPU 维护每个线程的执行状态,包括程序计数器和调用堆栈,并且可以以每个线程为粒度让出执行权,这既可以更好地利用执行资源,也可以让一个线程等待另一个线程生成的数据。调度优化器决定如何将来自同一线程束的活动线程组合成单指令多线程(SIMT)单元。这保留了与英伟达之前的 GPU 中 SIMT 执行相同的高吞吐量,但具有更大的灵活性:线程现在可以在小于线程束的粒度上出现分支和重新聚合。
若开发者对先前硬件架构的线程束同步性(warp-synchronicity)存在假定,那么独立线程调度(Independent Thread Scheduling)可能会导致实际参与代码执行的线程集合与预期存在较大差异。具体而言,所有线程束同步代码(例如无同步操作的线程束内归约运算)都应重新审视,以确保其能与 NVIDIA Volta 及后续架构兼容。有关详细信息,请参阅 Compute Capability 7.x。
独立线程调度
2 术语线程束同步 warp-synchronous 是指隐式假定同一 warp 中的线程在每条指令处都同步的代码。 “独立线程调度(Independent Thread Scheduling, ITS)”—— 线程束内的每个线程可以独立调度、独立执行(比如线程 A 因等待内存而暂停时,线程 B 可以继续执行后续指令)。这种机制能提升硬件利用率,但直接 “打破” 了旧架构的 “同步性假设”。
参与当前指令的线程束中的线程称为活动 active 线程,而不参与当前指令的线程则为非活动 inactive(禁用)线程。线程处于非活动状态可能有多种原因,包括比其所在线程束中的其他线程更早退出、采取了与线程束当前执行的分支路径不同的分支路径,或者是线程数量不是线程束大小倍数的线程块中的最后几个线程。
如果一个线程束执行的非原子指令,使该线程束中的多个线程写入全局或共享内存中的同一位置,则写入该位置的串行写入次数会因设备的计算能力而异(请参阅 Compute Capability 5.x, Compute Capability 6.x, and Compute Capability 7.x),且最终执行写入操作的是哪个线程是不确定的。
执行当前指令的 Warp 中的线程称为活动线程,而未执行当前指令的线程是非活动的(禁用)。线程可能由于多种原因而处于非活动状态,包括比 warp 中的其他线程更早退出、执行与 warp 不同的分支路径、或线程数不是 Warp 大小的倍数的块中的最后一些线程。
如果 Warp 执行了一个 atomic,该指令是让 Warp 中的多个线程写入全局或共享内存中的同一位置,则该位置发生的序列化写入次数取决于设备的计算能力(参见 Compute Capability 3.x、Compute Capability 5.x、Compute Capability 6.x 和 Compute Capability 7.x),哪个线程会最后写入是不确定的。
如果一个线程束执行的原子指令针 atomic 对线程束中多个线程对全局内存中的同一位置进行读取、修改和写入操作,对该位置的每次读取/修改/写入操作都会发生,且这些操作都会被序列化,但操作发生的顺序是未定义的。
warp 内的读写
- 非原子指令写同一块内存时,结果不可预测(最终写入线程 undefined),必须避免这种场景;
- 原子指令写同一块内存时,操作完整性有保障(所有线程的操作都会执行),但顺序 undefined,需确保业务逻辑不依赖执行顺序;
硬件多线程
多处理器(multiprocessor)所处理的每个线程束(warp),其执行上下文(包括程序计数器、寄存器等)会在线程束的整个生命周期内都保存在片上(on-chip)中。因此,从一个执行上下文切换到另一个执行上下文没有额外开销;并且在每次指令发射(instruction issue)时,线程束调度器(warp scheduler)会选择一个 “存在可执行下一条指令的线程(即该线程束的活跃线程)” 的线程束,然后将指令发射(issue)给这些线程。
具体而言,每个 SM 都拥有一组 32 位寄存器,这些寄存器会在 warp 之间进行分配;此外,多处理器还配备了一块并行数据缓存(parallel data cache)或共享内存(shared memory),该存储区域会在各个 block 之间进行分配。
对于给定的内核,在多处理器上能够同时驻留并处理的 block 和 warp 数量,取决于:
- 内核使用的寄存器和共享内存数量,以及
- 多处理器上可用的寄存器和共享内存数量。
- 每个多处理器也有常驻线程块的最大数量和常驻线程束的最大数量。
这些限制以及多处理器上可用的寄存器和共享内存数量,是设备计算能力的函数,并在 Compute Capabilities 中有说明。如果每个多处理器上没有足够的寄存器或共享内存来处理至少一个线程块,内核将无法启动。
一个线程块中的线程束总数如下:
- 是每个线程块的线程数
- 是线程束大小,等于 32
- 表示将 向上舍入到最接近的 的倍数。
为一个 block 分配的寄存器总数和共享内存总量,记录在 CUDA 工具包提供的 CUDA Occupancy Calculator 中(见 4-1性能指南)。
CUDA-Enabled GPUs
https://developer.nvidia.com/cuda-gpus 列出了所有支持 CUDA 的设备及其计算能力。
也可以使 用运行时查询计算能力、多处理器数量、时钟频率、设备内存总量和其他属性(见参考手册)。
Compute Capability
CC 总览: https://developer.nvidia.com/cuda-gpus
https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#compute-capabilities
Summary
Hardware Implementation (Key Points)
- Core Architecture: NVIDIA GPUs consist of scalable Streaming Multiprocessors (SMs). Thread blocks of a kernel grid are distributed to SMs with available capacity; threads in a block run concurrently on one SM, and multiple blocks can execute on an SM.
- 7.1. SIMT Architecture:
- Threads are grouped into 32-thread units called warps. Warps execute a single instruction at a time, with threads having independent registers and program counters.
- Divergent branches within a warp cause it to execute all paths, disabling non-participating threads.
- Independent Thread Scheduling (Volta+): Threads maintain individual execution states (PC, call stacks), enabling flexible divergence/reconvergence and sub-warp granularity.
- Memory behavior: Unsynchronized writes to the same location by a warp have undefined results. Atomic operations on shared locations are serialized but ordered unpredictably.
- 7.2. Hardware Multithreading:
- SMs manage warp execution contexts (registers, PC) on-chip, allowing zero-cost context switches. Warp schedulers select ready warps for instruction issuance.
- Resident blocks/warps per SM depend on register/shared memory usage and hardware limits (compute capability-specific). Insufficient resources prevent kernel launch.
- Warps per block: Calculated as
ceil(threads_per_block / 32).
- Other: GPUs use little-endian format. Active threads in a warp execute the current instruction; inactive threads are disabled (e.g., due to divergence).
硬件架构总结
CUDA 的硬件架构与软件编程模型之间的映射关系是理解 GPU 并行计算的核心。这种映射通过多层次抽象实现:从物理硬件的流多处理器(SM)、内存层次,到软件层面的线程网格(Grid)、线程块(Block),形成了一套完整的并行计算体系。以下从硬件到软件逐层解析:
当一个 kernel 被执行时,它的 grid 中的线程块被分配到 SM 上,一个线程块只能在一个 SM 上被调度。SM 一般可以调度多个线程块,这要看 SM 本身的能力。
那么有可能一个 kernel 的各个线程块被分配多个 SM,所以 grid 只是逻辑层,而 SM 才是执行的物理层。SM 采用的是 SIMT (Single-Instruction, Multiple-Thread,单指令多线程) 架构,基本的执行单元是线程束(warps),线程束包含 32 个线程,这些线程同时执行相同的指令,但是每个线程都包含自己的指令地址计数器和寄存器状态,也有自己独立的执行路径。
一、CUDA 硬件架构核心组件
1. 流多处理器(Streaming Multiprocessor, SM)
GPU 实际上是一个 SM 的阵列,每个 SM 包含 N 个计算核,现在我们的常用 GPU 中这个数量一般为 128 或 192。一个 GPU 设备中包含一个或多个 SM,这是处理器具有可扩展性的关键因素。如果向设备中增加更多的 SM,GPU 就可以在同一时刻处理更多的任务,或者对于同一任务,如果有足够的并行性的话,GPU 可以更快完成它。
具体而言,以 Fermi 架构的 GPU 为例,其结构如下图。
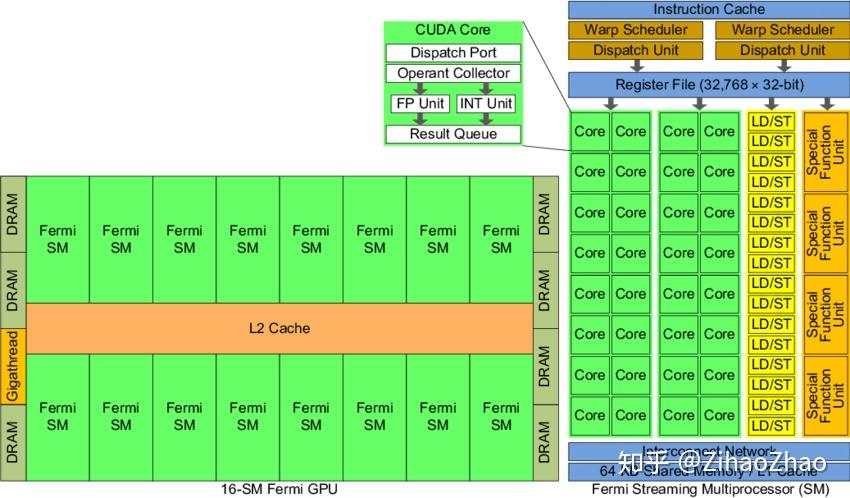
左边是 GPU 的整体结构,其主要是由大量的 SM(Streaming-Multiprocessor)和 DRAM 存储等构成的。右图是对单个 SM 进行放大,可以看到 SM 由大量计算核(有时也称 SP 或 CUDA 核)、LDU(Load-Store Units)、SFU(Special-Function Units)、寄存器、共享内存等构成。这种结构正是 GPU 具有高并行度计算能力的基础。通过一定的层级结构组织大量计算核,并给各级都配有相应的内存系统,GPU 获得了出色的计算能力。
其中流式多处理器(SM)是 GPU 架构的核心,类似于 CPU 中的核,但设计更专注于并行计算。GPU 中的每一个 SM 都能支持数百个线程并发执行,每个 GPU 通常有多个 SM,所以在一个 GPU 上并发执行数千个线程是有可能的。当启动一个内核网络时,它的线程块会被分布在可用的 SM 上来执行。当线程块一旦被调度到一个 SM 上,其中的线程只会在那个指定的 SM 上并发执行。多个线程块可能会被分配到同一个 SM 上,而且是根据 SM 资源的可用性进行调度的。
每个 SM 包含:
- 计算核心:
- CUDA Core:执行通用浮点和整数运算(FP32/FP64/INT32)。
- Tensor Core:专用矩阵运算单元,支持 FP16/BF16/INT8 等低精度计算,大幅提升 AI 任务效率(如 A100 的 Tensor Core 峰值性能达 312 TFLOPS)。
- 内存层次:
- 寄存器(Registers):线程私有,访问速度最快(约 1 周期延迟)。
- 共享内存(Shared Memory):线程块内共享,速度接近寄存器(约 10 周期延迟),容量有限(如 A100 每个 SM 有 192KB)。
- 调度单元:
- Warp 调度器:以 32 个线程为一组(Warp)调度执行,同一 Warp 内线程执行相同指令(SIMT 架构)。
线程束调度器(Warp Scheduler)顾名思义是进行线程束的调度,负责将软件线程分配到计算核上;LDU(Load-Store Units)负责将值加载到内存或从内存中加载值;SFU(Special-Function Units)用来处理 sin、cos、求倒数、开平方特殊函数。
上面说到了 kernel 的线程组织层次,那么一个 kernel 实际上会启动很多线程,这些线程是逻辑上并行的,但是在物理层却并不一定。这其实和 CPU 的多线程有类似之处,多线程如果没有多核支持,在物理层也是无法实现并行的。但是好在 GPU 存在很多 CUDA 核心,充分利用 CUDA 核心可以充分发挥 GPU 的并行计算能力。
2. 线程调度机制
- Warp(线程束):32 个线程组成一个 Warp,是硬件调度的基本单位。
- SIMT(单指令多线程)执行:同一 Warp 内所有线程执行相同指令,但操作不同数据。
- Warp 调度过程:
- SM 将 Block 拆分为多个 Warp。
- Warp 调度器选择就绪 Warp(无数据依赖),发射指令到计算核心。
- 若 Warp 遇到内存访问等长延迟操作,调度器切换到其他 Warp 执行(隐藏延迟)。
3. 内存系统
GPU 内存分为多级层次,越靠近计算核心速度越快但容量越小:
| 内存类型 | 访问范围 | 容量(典型值) | 访问延迟 | 用途 |
|---|---|---|---|---|
| 寄存器 | 线程私有 | 数万 / 线程 | ~1 周期 | 存储线程局部变量 |
| 共享内存 | 线程块内共享 | 64KB~192KB/SM | ~10 周期 | 线程间数据交换、数据缓存 |
| L1/L2 缓存 | SM 私有 / 全局 | 16KB~64KB/SM | ~30 周期 | 缓存全局内存数据 |
| 全局内存 | 整个 GPU | 8GB~80GB | ~400 周期 | 存储大规模数据(需与主机内存交换) |
二、软件编程模型与硬件的映射
1. 线程组织层次
CUDA 软件通过三级层次组织线程,与硬件形成对应关系:
- 线程(Thread):执行最小单元,映射到硬件中的计算核心(CUDA Core/Tensor Core)。
- 线程块(Block):由多个线程组成(如 128~1024 线程),映射到单个 SM 上执行。块内线程通过共享内存通信,并可通过
__syncthreads()同步。 - 线程网格(Grid):由多个 Block 组成,可分布在多个 SM 上并行执行。
2. 关键映射关系
| 软件概念 | 硬件对应 | 约束条件 |
|---|---|---|
| 线程(Thread) | CUDA Core/Tensor Core | 每个线程由一个计算核心执行 |
| 线程块(Block) | 单个 SM | 一个 Block 必须在同一个 SM 上执行 |
| Warp(32 线程) | 硬件调度单元 | 同一 Warp 内线程必须执行相同指令 |
| 共享内存 | SM 内的共享内存单元 | 容量限制(如 A100 每个 SM 192KB) |
| 全局内存 | 设备 DRAM | 高延迟,需优化访问模式 |
CUDA 采用单指令多线程(SIMT)架构来管理和执行线程,每32 个线程为一组,被称为线程束(Warp)。线程束中所有线程同时执行相同的指令。每个线程都有自己的指令地址计数器和寄存器状态,利用自身的数据执行当前的指令。每个 SM 都将分配给它的线程块划分到包含 32 个线程的线程束中,然后在可用的硬件资源上调度执行。
SIMT 架构和 CPU 编程中常见的SIMD(单指令多数据)架构相似。两者都是将相同的指令广播给多个执行单元来实现并行。一个关键的区别就是 SIMD 要求同一个向量中的所有元素要在一个统一的同步组中一起执行,而 SIMT 允许同一线程束的多个线程独立执行。尽管一个线程数中的所有线程在相同的程序地址上同时开始执行,但是单独的线程仍有可能有不同的行为。
下面这幅图分别从逻辑视图和硬件视图描述了 CUDA 编程对应的组件。
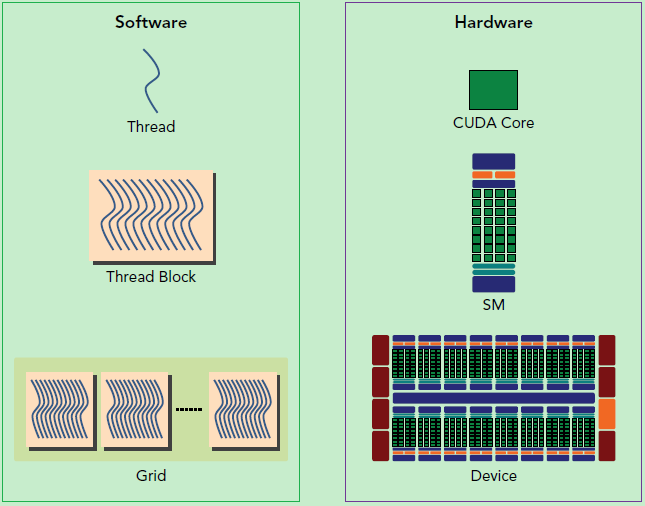
左侧是逻辑视图,自上而下,从线程构成线程块再构成线程网络。对应右侧的硬件就是 CUDA core、SM、GPU。
一个线程块只能在一个 SM 上被调度,而且一旦线程块在一个 SM 上被调度,就会保存在该 SM 上直到执行完成。需要注意的是,这两种层级并不是完全一一对应的,比如在同一时间,一个 SM 可以容纳多个线程块。
在 SM 中,共享内存和寄存器是非常重要的资源。共享内存被分配在 SM 上的常驻线程块中,寄存器在线程中被分配。线程块中的线程通过这些资源可以进行相互的合作和通信。尽管线程块里的所有线程都可以逻辑地并行运行,但并不是所有线程都可以同时在物理层面执行。因此线程块里的不同线程可能会以不同速度前进。我们可以使用 CUDA 语句在需要的时候进行线程的同步。
尽管线程块里的线程束可以任意顺序调度,但活跃的线程束数量还是会由 SM 的资源所限制。当线程数由于任何理由闲置的时候(比如等待从设备内存中读取数值)这时 SM 可以从同一 SM 上的常驻线程块中调度其他可用的线程束。在并发的线程束间切换并没有额外开销,因为硬件资源已经被分配到了 SM 上的所有线程和线程块中。这种策略有效地帮助 GPU 隐藏了访存的延时,因为随时有大量线程束可供调度,理想状态下计算核将一直处于忙碌状态,从而可以获得很高的吞吐量。
总结一下,SM 是 GPU 架构的核心,而寄存器和共享内存是 SM 中的稀缺资源。CUDA 将这些资源分配到 SM 中的所有常驻线程里。因此,这些有限的资源限制了在 SM 上活跃的线程束数量,而活跃的线程束数量对应于 SM 上的并行量。
三、内存访问模式与硬件的交互
1. 全局内存访问优化
- 合并访问(Coalesced Access):
- 硬件要求:Warp 内连续线程访问连续的内存地址(如
d_data[tid])。 - 原因:GPU 以 128 字节为单位批量读取全局内存(如 A100),若满足合并条件,一个内存事务可服务整个 Warp(32×4 字节)。
- 反例:
d_data[tid*4]可能导致每个线程触发独立内存事务,效率降低 4 倍。
- 硬件要求:Warp 内连续线程访问连续的内存地址(如
2. 共享内存的 Bank 冲突
-
Bank 机制:共享内存被分为 32 个 Bank(每个 Bank 带宽 32 位 / 周期)。
-
冲突场景:若同一 Warp 的多个线程访问同一 Bank 的不同地址,会导致串行访问。
__shared__ float data[256]; float val = data[threadIdx.x + offset]; // 若offset=0,线程0和32会访问同一Bank -
优化方法:通过填充数组避免地址冲突。
__shared__ float data[256 + 32]; // 填充32个元素,错开地址
四、计算资源的分配与利用
1. SM 资源限制
每个 SM 有固定资源,决定了可同时运行的 Block 数量:
- 寄存器限制:每个 Block 使用的寄存器总数不能超过 SM 的寄存器容量(如 A100 每个 SM 有 65536 个 32 位寄存器)。
- 共享内存限制:每个 Block 使用的共享内存不能超过 SM 的共享内存容量。
- 线程限制:每个 SM 最多可同时运行的线程数(如 A100 为 2048 线程)。
2. Occupancy(占用率)计算
-
定义:实际活跃 Warp 数与最大可能 Warp 数的比值。
-
计算公式:
每个SM的最大Warp数 = min(最大线程数/SM ÷ 32, 最大寄存器数/SM ÷ 每个线程的寄存器数, 最大共享内存/SM ÷ 每个Block的共享内存) Occupancy = 实际活跃Warp数 ÷ 每个SM的最大Warp数 -
优化目标:通过调整 Block 大小和资源使用,使 Occupancy 接近 100%,充分利用 SM 资源。
五、性能优化的映射实践
1. 矩阵乘法优化示例
- 朴素实现:
- 每个线程直接从全局内存读取矩阵元素,导致大量重复访问。
- 映射问题:全局内存访问延迟高,计算单元利用率低。
- 共享内存优化:
- 将矩阵分块(Tiling)加载到共享内存,每个线程块负责计算一个子矩阵。
- 映射改进:减少全局内存访问,利用共享内存的高速特性。
- Tensor Core 优化:
- 使用 WMMA 库将数据组织为 16×16 矩阵块,调用 Tensor Core 执行矩阵乘。
- 映射改进:充分利用 Tensor Core 的高吞吐量(每个周期可执行 64 次 FP16 乘法累加)。
GPU 微架构
Turing 架构
最新的 NVIDIA GPU 为 Turing 架构,继上一代的 Pascal 架构有了不小的改变。以 Turing 架构中我们最常见的 RTX 2080 为例,RTX 2080 采用的是 TU 104 核心,其架构如下图。与上文介绍的略有不同,我们能看到一个叫 GPC(Graphics Processing Cluster)的层次,TU 104 共有 6 个 GPC,其中每个 GPC 包括 4 个 TPC(Texture Processing Cluster),每个 TPC 包含 2 个 SM,总计有 48 个 SM 可供使用。而每个 SM 包含 64 个 CUDA 核(一般指 FP 32 的数量),总计有 3072 个 CUDA 核可供使用。(感谢评论区幽玄大佬指正错误!)
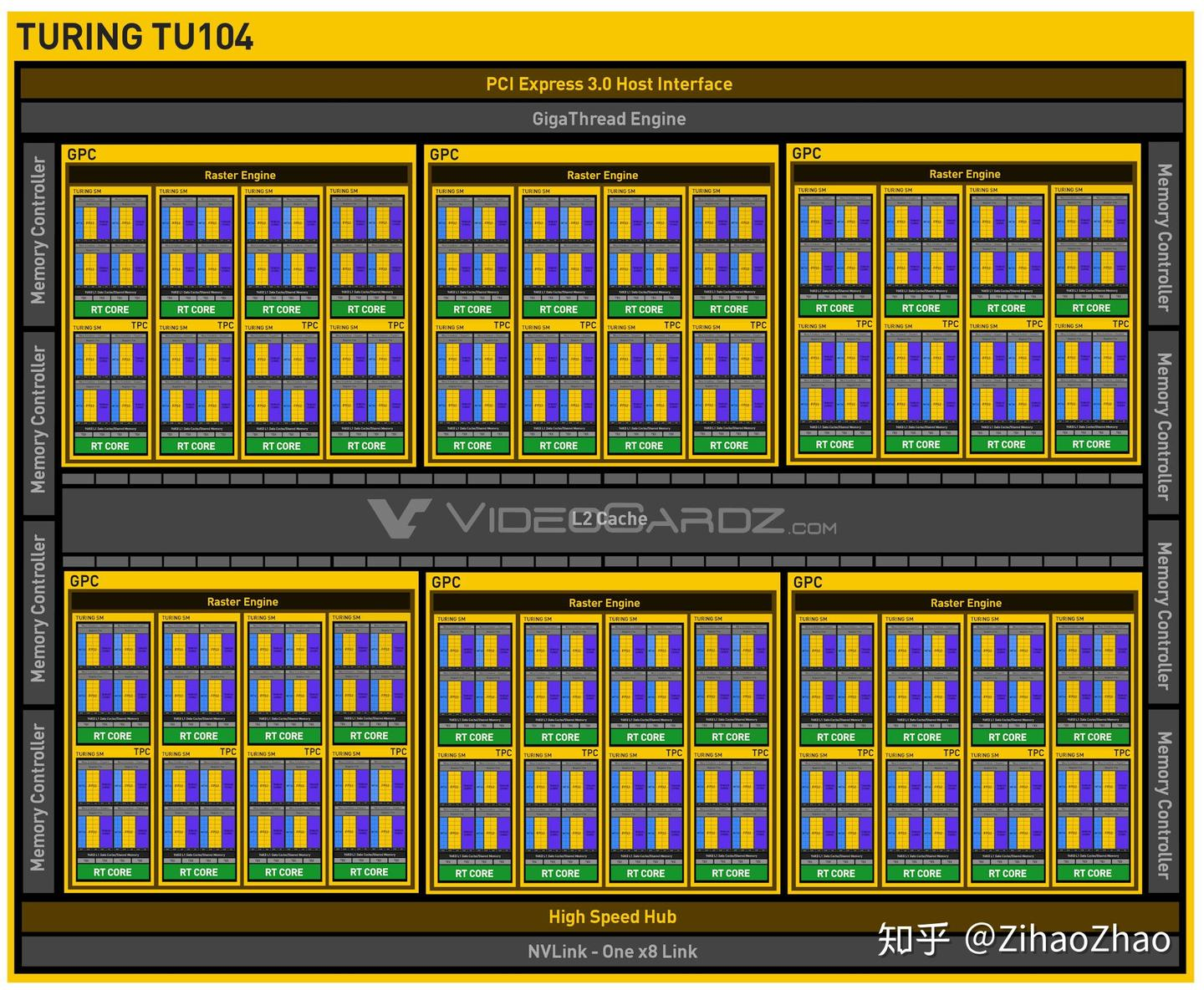
再具体看其中每个 SM 的结构,如下图。Turing 架构在 SM 中增加了新的处理单元,INT 32。这让 Turing 架构的 GPU 有能力并行处理浮点数和非浮点数。官方宣称,理论上这将提高 GPU 在浮点操作时 36% 的吞吐量。还有每个 SM 上的 L 1 缓存/共享内存也增加到了 96 KB。

最后来欣赏一下芯片内部结构,12 nmFFN 工艺制造的。官方渲染图也搞得十分精致,黑金范。

Hoppper 架构解读
https://zhuanlan.zhihu.com/p/1895527304509236945
架构发展
NVIDIA 十年 GPU 架构与 CUDA 编程模型演进:从通用计算到 AI 加速的革命
过去十年,NVIDIA GPU 架构经历了从通用计算到 AI 加速的深刻转变,CUDA 编程模型也随之不断演进,以充分发挥硬件潜力并简化开发者工作。从 2014 年的 CUDA 7.0 到 2025 年的 CUDA 12.8,从 Maxwell 到 Blackwell 架构,NVIDIA 通过持续创新,在计算能力、内存管理和并行编程模型方面取得了突破性进展。这种软硬协同演进不仅推动了深度学习、科学计算和图形渲染等领域的革命性进步,也重新定义了现代计算的范式。
一、GPU 架构演进:从通用计算到 AI 专用加速
NVIDIA GPU 架构在过去十年间经历了显著的代际变化,这些变化主要体现在制程工艺、CUDA 核心数量以及专用计算单元的引入上。各代架构的演进路线清晰反映了 NVIDIA 从通用图形处理器向 AI 专用加速器转变的战略方向。
制程工艺的持续进步是架构演进的基础。从 Fermi 架构的 40nm 工艺开始,NVIDIA 逐步过渡到更先进的制程:Maxwell 和 Kepler 采用 28nm,Pascal 升级到 16nm,Volta 和 Turing 使用 12nm,Ampere 采用 8nm,Ada Lovelace 和 Blackwell 则分别使用 TSMC 4N 和 4NP 工艺 。这种工艺改进使晶体管密度和能效比大幅提升,为更高性能计算提供了物理基础。例如,Blackwell 架构的 GB200 芯片集成高达 2080 亿个晶体管,是 Hopper 架构的 2.5 倍,成为 NVIDIA 历史上最大的 GPU 芯片 。
CUDA 核心数量的指数级增长显著提升了通用计算能力。Fermi 架构仅有 512 个 CUDA 核心,到 Volta 增加至 5120 个,Turing 为 4352 个,Ampere 达到 10496 个,Ada Lovelace 为 16384 个,而 Blackwell 架构的 RTX 5090 则拥有 21760 个 CUDA 核心 。这种增长使单卡 FP32 计算能力从 Volta 的 125 TFLOPS 提升至 Blackwell 的 125 Tera Operations per Second (TOPS),性能提升超过 100 倍。值得注意的是,Blackwell 架构的 CUDA 核心数量是消费级 RTX 5090 的 21760 个,而数据中心级 B100 和 B200 分别达到 18432 和 24576 个 ,这种差异化设计满足了不同应用场景的需求。
专用计算单元的引入是架构演进的核心特征。2017 年 Volta 架构首次引入 Tensor Core,专门用于加速矩阵乘法等深度学习运算 ;2018 年 Turing 架构增加了 RT Core,用于加速光线追踪 ;2020 年 Ampere 架构升级到第三代 Tensor Core 并优化了稀疏计算 ;2022 年 Hopper 架构引入第四代 Tensor Core 和 Transformer 引擎,支持 FP8 格式 ;2024 年 Blackwell 架构则推出了第五代 Tensor Core 和第四代 RT Core,分别支持 FP4 精度和更高效的光线追踪 。这些专用单元的迭代不仅提升了特定领域的计算效率,也推动了 CUDA 编程模型的相应发展。
| 架构 | 发布年份 | 制程工艺 | CUDA 核心数 | Tensor Core 代 | RT Core 代 | 显存类型 | AI 算力 (典型型号) |
|---|---|---|---|---|---|---|---|
| Fermi | 2010 | 40nm | 512 | - | - | GDDR5 | - |
| Maxwell | 2014 | 28nm | 960-3072 | - | - | GDDR5 | - |
| Pascal | 2016 | 16nm | 3584-3840 | - | - | GDDR5X | - |
| Volta | 2017 | 12nm | 5120 | 第一代 | - | HBM2 | 112 TFLOPS(FP16) |
| Turing | 2018 | 12nm | 4352 | 第二代 | 第一代 | GDDR6 | 500 TFLOPS(Tensor) |
| Ampere | 2020 | 8nm | 10496 | 第三代 | 第二代 | GDDR6X | 624 TFLOPS(FP8) |
| Ada Lovelace | 2022 | 4N | 16384 | 第四代 | 第三代 | GDDR6X | - |
| Hopper | 2022 | 4N | 18432 | 第四代 | 第二代 | HBM3 | 1978 TFLOPS(FP8) |
| Blackwell | 2024 | 4NP | 21760-24576 | 第五代 | 第四代 | GDDR7/HBM3e | 20 PFLOPS(FP4) |
二、CUDA 编程模型演进:从基础并行到异构计算
CUDA 编程模型在过去十年间经历了从基础并行计算到全面支持异构计算的转变,其版本演进与 GPU 架构的革新紧密相关。CUDA 编程模型的核心是简化 GPU 并行计算的复杂性,使开发者能够专注于算法设计而非硬件细节。
**CUDA 7.0(2014)**是 Maxwell 架构的配套版本,引入了动态并行 (Dynamic Parallelism) 功能,允许核函数内动态启动新线程块 。这一特性通过 -rdc=true 编译选项启用,支持从 sm_35 架构开始的 GPU 。动态并行为递归算法和自适应计算提供了新可能,例如在图像处理中根据计算结果动态调整后续处理步骤 。
**CUDA 8.0(2016)**针对 Pascal 架构优化,引入了 cudaMemAdvise 接口,允许开发者通过内存访问模式建议 (如 SetReadMostly) 优化统一内存管理 (UVM) 性能,减少页面迁移开销 。此外,CUDA 8.0 还支持 GPU 直接同步,使 GPU 可以在没有 CPU 辅助的情况下交换数据,进一步提升了并行计算效率 。
**CUDA 9.0(2017)**是 Volta 架构的配套版本,首次引入 Tensor Core 编程接口 (如 __nvcuda__::matmult),支持混合精度训练 (FP16/INT8) 。这一版本还强化了 RT Core 编程接口,为光线追踪加速提供了软件支持 。CUDA 9.0 标志着 CUDA 从通用计算向 AI 专用加速的转变,为深度学习应用提供了更高效的编程工具。
**CUDA 10.0(2019)**针对 Turing 架构优化,强化了 RT Core 编程接口 (如 rtcoreCreate),并优化了内存层次结构,支持更高效的全局内存访问模式 。此外,CUDA 10.0 还引入了多级缓存和共享内存优化,进一步提升了数据密集型应用的性能 。
**CUDA 11.0(2020)**支持 Ampere 架构,引入第三代 Tensor Core 编程接口,优化了稀疏张量计算 (如 cutlass::layout::RowMajor),并增强了多 GPU 协作 。这一版本还改进了统一内存管理 (UVM) 的性能,特别是在多 GPU 系统中,通过 cudaMemAdvise 接口提供了更精细的内存控制 。
**CUDA 12.0(2022)**是 Hopper 架构的配套版本,新增 Transformer 引擎编程工具链 (如 nvcuda::transformerEngine),支持 FP8 格式 。这一版本还引入了编程二级缓存到 SM 多播的功能,优化了 L2 缓存压缩策略,通过 cudaMemAdvise 接口提供了更精细的内存控制 。此外,CUDA 12.0 还支持 SIMT 集体的公共 PTX 指令,如 elect_one,为基因组学和 DPX 指令提供了更快的组合数学运算支持 。
**CUDA 12.8(2025)**支持 Blackwell 架构,引入了 FP4 计算单元编程接口 (如 __nvcuda__::fp4 MatMult),并改进了多芯片互联的内存管理 。这一版本还通过 CUDA Graph 条件节点优化,新增 IF/ELSE 和 SWITCH 节点,允许 GPU 端动态控制执行流程,减少 CPU 干预,提升 LLM 训练/推理性能 。此外,CUDA 12.8 还支持对 Blackwell 架构的显存带宽优化,通过 --gpu-architecture咨询 指定 Blackwell 架构 (如 sm_90),充分利用 GDDR7 显存的高带宽特性 。
CUDA 编程模型的核心演进体现在三个方面:首先,线程层次结构保持 Grid-Block-Warp-Thread 的两级并行机制,但随着 SM 规模扩大,每个 SM 可支持的线程数量也随之增加;其次,内存管理从 CUDA 6.0 的 UVM 到 CUDA 12.8 的多芯片 UVM,逐步简化开发者内存操作,实现跨 GPU 的透明地址空间;最后,专用单元支持通过 cutensor、rtcore 等命名空间的 API 逐步开放,使开发者能够直接调用 Tensor Core 和 RT Core 的硬件加速功能 。
三、AI 算力演进:从 Tensor Core 到 FP4 计算单元
NVIDIA GPU 架构的 AI 算力在过去十年间经历了从专用加速单元到全精度优化的演进,这种演进主要体现在数据精度支持和专用计算单元的优化上,使 AI 计算效率实现了指数级提升。
**Volta 架构 (2017)**的 Tensor Core 支持 FP16/INT8 精度,AI 训练算力达到 125 TFLOPS(FP16) 和 250 TFLOPS(INT8) 。这一架构首次在硬件层面实现了矩阵乘法加速,使深度学习训练速度大幅提升。Volta 架构的 Tensor Core 通过 HMMA 指令 (半精度矩阵乘法和累加) 提供了专用硬件加速,每个 Tensor Core 每周期能够计算相当于 4x4x4 矩阵乘法的运算,相当于每个 SM 每周期 1024 FLOP 。
**Turing 架构 (2018)**的 Tensor Core 升级为第二代,增加了对 INT8 和 INT4 精度的支持,但 FP16 算力仅为 65 TFLOPS 。这一架构的 AI 算力提升主要体现在推理领域,通过 Tensor Core 加速实现了更高效的 AI 推理。Turing 架构的 Tensor Core 采用了 Warp-Level 同步 MMA,提高了并行计算效率 。
**Ampere 架构 (2020)**的 Tensor Core 升级为第三代,优化了稀疏计算,AI 算力达到 624 TFLOPS(FP8) 和 312 TFLOPS(FP16) 。这一架构的 AI 算力提升主要体现在训练领域,通过稀疏张量支持减少了不必要的计算,提高了计算效率。Ampere 架构的 Tensor Core 每周期可以完成 256 个浮点数乘累加,是老架构的两倍,主频为 1.41GHz 。
**Hopper 架构 (2022)**的 Tensor Core 升级为第四代,并引入了 Transformer 引擎,AI 算力达到 1978 TFLOPS(FP8) 和 985 TFLOPS(FP16) 。这一架构的 AI 算力提升主要体现在对 Transformer 模型的专用优化上,通过硬件加速了注意力机制等核心运算。Hopper 架构的 Tensor Core 单个 SM 核心一个周期可以完成的 FP16 乘累加数再翻一倍,达到 512 次,主频提高到 1.83GHz 。
**Blackwell 架构 (2024)**的 Tensor Core 升级为第五代,并新增了 FP4 计算单元,AI 算力达到 10 PFLOPS(FP8) 和 20 PFLOPS(FP4) 。这一架构的 AI 算力提升主要体现在对超低精度计算的支持上,通过 NVFP4 格式实现了接近 FP8 的准确度,同时获得了约 2 倍的计算速度提升和 1.8 倍的内存占用减少 。Blackwell 架构的 Tensor Core 采用了微张量缩放技术 (Micro Tensor Scaling),能够动态调整数值范围,在保持精度的同时最大化表示效率 。
AI 算力的演进路径清晰反映了 NVIDIA 从通用计算向 AI 专用加速的转变。从 Volta 到 Blackwell,AI 训练算力从 125 TFLOPS(FP16) 提升至 10 PFLOPS(FP8),提升了约 80 倍;AI 推理算力从 65 TFLOPS(FP16) 提升至 20 PFLOPS(FP4),提升了约 300 倍。这种算力提升主要得益于三个因素:专用计算单元的迭代、数据精度的降低以及内存带宽的提升。
四、内存管理与线程调度:从分层结构到统一内存
NVIDIA GPU 架构的内存管理与线程调度在过去十年间经历了从分层结构到统一内存的演进,这种演进主要体现在内存层次结构的优化和线程调度机制的改进上,使 GPU 能够更高效地处理大规模并行计算任务。
内存层次结构的演进从早期的分层结构 (全局内存、纹理内存、常量内存、共享内存和局部内存) 逐步发展为统一内存管理 (UVM) 。在 CUDA 6.0 之前,开发者需要手动管理不同层次的内存,包括全局内存到共享内存的数据加载、共享内存的 Bank 冲突规避以及全局内存的合并访问 。CUDA 6.0 引入了 UVM,允许开发者通过单一、连续的内存镜像访问所有 CPU 和 GPU 内存,简化了内存管理 。CUDA 12.0 进一步优化了 UVM,通过 编程二级缓存到SM多播 功能优化了 L2 缓存压缩策略,减少了页面迁移开销 。CUDA 12.8 则通过 UVM 扩展支持跨 GPU 的透明地址空间,使开发者无需手动管理多芯片内存分配,大大简化了分布式计算的开发流程 。
线程调度机制的演进从早期的固定线程分配逐步发展为动态线程调度 。在 CUDA 7.0 之前,线程调度主要依赖于静态配置,开发者需要预先确定线程块和线程数量。CUDA 7.0 引入了动态并行功能,允许核函数内动态启动新线程块,为递归算法和自适应计算提供了新可能 。CUDA 8.0 进一步优化了线程调度,引入了 cudaMemAdvise 接口,允许开发者通过内存访问模式建议优化线程调度 。CUDA 12.8 则通过 CUDA Graph 条件节点优化,新增 IF/ELSE 和 SWITCH 节点,允许 GPU 端动态控制执行流程,减少了 CPU 干预,提升了并行计算效率 。
共享内存的优化是线程调度演进的重要组成部分。早期的共享内存采用 16 个 Bank 的并行架构,当多个线程访问同一 Bank 不同地址时,会触发串行化。随着架构演进,共享内存的 Bank 数量增加到 32 个,支持更灵活的访问模式 。CUDA 12.0 还引入了 cudaDeviceSetSharedMemConfig 函数,允许开发者设置 Bank 大小为四个字节 (默认值) 或八个字节,以避免共享内存 Bank 冲突 。此外,CUDA 12.0 还支持 cudaFuncCachePreferEqual 选项,获得 32KB 共享内存/32KB L1 缓存的设置,优化了内存层次结构 。
内存带宽的提升是 GPU 架构演进的重要指标。从 Volta 的 HBM2 到 Blackwell 的 GDDR7/HBM3e,内存带宽不断提升,为大规模并行计算提供了更高效的内存访问 。Blackwell 架构的 RTX 5090 采用 512 位 GDDR7 接口,带宽达到 1.792TB/s,是 Hopper 架构的约 1.5 倍 。这种带宽提升使 GPU 能够更高效地处理大规模数据集,支持更复杂的 AI 模型和图形渲染。
内存压缩技术的引入是内存管理演进的重要里程碑。Hopper 架构的 L2 缓存支持数据压缩和解压缩技术,通过 cudaMemAdvise 接口优化了内存使用效率 。Blackwell 架构进一步扩展了内存压缩技术,支持 LZ4、Snappy 和 Deflate 等压缩格式,通过 解压缩引擎 加速数据库查询和数据分析 。这些压缩技术使 GPU 能够在有限的内存带宽下处理更大的数据集,提高了计算效率。
五、通信机制:从 PCIe 到 NVLink
NVIDIA GPU 架构的通信机制在过去十年间经历了从 PCIe 到 NVLink 的演进,这种演进主要体现在 GPU 间通信带宽和延迟的优化上,使大规模并行计算和分布式 AI 训练成为可能。
PCIe 接口的演进从早期的 PCIe 3.0 逐步发展到 PCIe 5.0 。PCIe 3.0 带宽为 8GB/s,而 PCIe 5.0 带宽达到 40GB/s,提升了 5 倍。这种带宽提升使 CPU 和 GPU 之间的数据传输更加高效,减少了通信瓶颈。CUDA 12.8 还引入了 cudaStreamGetDevice API,允许开发者检索与 CUDA 流关联的设备,简化了多设备应用的开发流程 。
NVLink 的演进是通信机制演进的核心。从第一代 NVLink(300GB/s) 到第五代 NVLink(1.8TB/s),带宽不断提升,为 GPU 间通信提供了更高效的通道 。Hopper 架构的 NVLink 4 带宽达到 900GB/s,而 Blackwell 架构的第五代 NVLink 带宽进一步提升至 1.8TB/s,是 Hopper 架构的两倍 。这种带宽提升使 GPU 集群能够更高效地处理大规模 AI 模型和科学计算任务,支持更多的 GPU 连接 (从 256 个到 576 个) 。
NVLink-C2C 技术的引入是通信机制演进的重要里程碑。这一技术使 GPU 可以在没有 CPU 辅助的情况下交换数据,通过 ATS 地址转换服务优化了内存访问效率。Hopper 架构的 NVLink-C2C 带宽达到 900GB/s,使 GPU 可以直接访问 CPU 内存,扩展了 GPU 的内存容量 。Blackwell 架构进一步扩展了这一技术,通过 NVLink Switch 芯片支持更多的 GPU 连接和更高效的网络拓扑 。
CUDA 流的优化是通信机制演进的重要组成部分。CUDA 12.0 引入了流优先级设置功能,允许开发者通过 API(如 cuStreamSetPriority咨询) 设置流的优先级,优化了 GPU 资源分配 。CUDA 12.8 进一步扩展了这一功能,通过 CUDA新流API 减少了对主机 CPU 的调用,缩短了内核处理与启动之间的时间,提高了令牌生成率,有助于模型推理 。
PCIe 5.0 支持的引入使 Blackwell 架构能够与更高效的 CPU 互连 。RTX 50 系列支持 PCIe 5.0 接口,其带宽是 PCIe 4.0 的两倍,可提高 CPU 内存的数据传输速度,并为 AI、数据科学和 3D 建模等数据密集型任务释放更快的性能 。这种支持使开发者能够充分利用最新的 CPU 和 GPU 互连技术,优化整体系统性能。
六、基于 GPU 的算子开发策略演变
基于 GPU 的算子开发策略在过去十年间经历了从通用计算到专用加速的转变,这种转变主要体现在数据精度支持、专用计算单元利用以及分布式计算优化上,使开发者能够更高效地实现 AI 模型的训练和推理。
Volta 架构 (2017) 的算子开发主要基于 Tensor Core 的 MMA 指令 (如 cutensorHMMA咨询),通过 cutensor 库调用 Tensor Core 的 FP16/INT8 矩阵乘法。这一时期的算子开发需要开发者熟悉 Tensor Core 的指令集和内存布局,手动编写内核函数以利用硬件加速。例如,在实现卷积算子时,开发者需要将输入数据和权重转换为 Tensor Core 支持的格式,然后调用相应的 MMA 指令进行计算。
Ampere 架构 (2020) 的算子开发引入了稀疏张量支持,算子开发需要优化稀疏格式 (如 CSR) 以利用第三代 Tensor Core 的稀疏计算能力 。这一时期的算子开发更加注重计算效率的优化,通过稀疏化减少不必要的计算,提高 Tensor Core 利用率。例如,在实现注意力机制算子时,开发者可以利用稀疏格式减少计算量,提高计算效率。
Hopper 架构 (2022) 的算子开发引入了 Transformer 引擎 API(如 nvcuda::TransformerEngineConfig),支持 FP8 格式 。这一时期的算子开发更加注重对 Transformer 模型的专用优化,通过硬件加速注意力机制等核心运算,提高 AI 模型训练和推理效率。例如,在实现 Transformer 模型时,开发者可以利用 Transformer 引擎 API 直接调用硬件加速的注意力机制,提高计算效率。
Blackwell 架构 (2024) 的算子开发通过 NVFP4 量化和 CUTLASS 3.8 开发低精度算子,结合 UVM 和 CUDA Graph 优化多芯片协作 。这一时期的算子开发更加注重对超低精度计算的支持,通过量化减少内存占用,提高计算效率。例如,在实现 LLM 推理时,开发者可以使用 TensorRT Model Optimizer 将模型转换为 NVFP4 格式,减少显存占用,提高推理速度 。
算子开发策略的演变可以分为三个阶段:第一阶段 (2014-2018) 主要基于通用 CUDA 核心开发算子,通过并行化和内存优化提高性能;第二阶段 (2019-2022) 开始利用专用计算单元 (Tensor Core 和 RT Core) 开发算子,通过硬件加速提高特定领域性能;第三阶段 (2023-2025) 则专注于低精度计算和分布式优化,通过量化和多芯片协作进一步提升 AI 模型性能 。
Blackwell 架构的算子开发需要特别关注以下几点:首先,利用 NVFP4 量化减少内存占用,提高计算效率;其次,通过 CUTLASS 3.8 支持的 mxFP4 和 NVFP4 格式开发专用算子,充分利用第五代 Tensor Core 的 FP4 运算能力 ;最后,利用 CUDA Graph 条件节点优化,实现 GPU 端动态控制流,减少 CPU 干预,提高分布式算子效率 。例如,在实现 Flash Attention 算子时,开发者可以利用 Blackwell 的 Transformer 引擎和 FP4 计算单元,实现吞吐量额外提升 15%,支持更长的上下文窗口 。
七、未来趋势:从 Blackwell 到 Rubin 架构
NVIDIA GPU 架构和 CUDA 编程模型的演进仍在继续,未来趋势将更加注重低精度计算、多芯片互联和专用硬件加速,以满足 AI 和科学计算等领域不断增长的需求。
**Rubin 架构 (预计 2026 年)**将是 Blackwell 架构的继任者,采用台积电 3nm 小芯片 chiplet 架构,通过多颗较小芯片整合单一封装,改善良率并降低成本 。这一架构将支持更高效的 FP4 计算和更大的模型训练,为 AI 和科学计算提供更强大的硬件基础。CUDA 编程模型也将随之演进,提供更高效的 API 和工具链,简化开发者工作。
多芯片互联技术将进一步发展,支持更多的 GPU 连接和更高效的网络拓扑。Blackwell 架构的第五代 NVLink 带宽已达 1.8TB/s,而 Rubin 架构预计将支持更高的带宽和更低的延迟,使分布式 AI 训练和推理更加高效 。CUDA 编程模型也将提供更完善的多芯片内存管理和通信机制,使开发者能够轻松构建分布式计算应用。
专用硬件加速单元将继续迭代,针对特定 AI 模型和计算任务提供更高效的加速。Blackwell 架构的第五代 Tensor Core 和第四代 RT Core 已经支持 FP4 和更高效的光线追踪 ,而 Rubin 架构预计将引入更先进的 Transformer 引擎和光线追踪单元,进一步提升 AI 和图形渲染性能。CUDA 编程模型也将提供更完善的专用单元 API 和工具链,使开发者能够充分利用硬件加速能力。
低精度计算将成为未来算力提升的主要方向。Blackwell 架构的 NVFP4 格式已经实现了接近 FP8 的准确度,同时获得了约 2 倍的计算速度提升和 1.8 倍的内存占用减少 。未来将进一步发展更高效的低精度格式和量化技术,使 AI 模型能够在更小的内存和更短的时间内完成训练和推理。CUDA 编程模型也将提供更完善的低精度计算 API 和工具链,简化量化和格式转换过程。
异构计算将进一步发展,支持 CPU、GPU、NPU 等多种计算单元的协同工作。Blackwell 架构的双芯片设计 (Grace CPU 和 Blackwell GPU) 已经展示了异构计算的潜力 ,而未来将进一步优化 CPU 和 GPU 之间的通信和数据共享,使异构计算更加高效。CUDA 编程模型也将提供更完善的异构计算 API 和工具链,使开发者能够轻松构建异构计算应用。