本文参考:
- NVIDIA CUDA C++ Programming Guide 第 1-4 章
- Professional CUDA C Programming 第 1 章
CUDA 简介
Parallel Computing
The high-performance computing (HPC) landscape is always changing as new technologies and processes become commonplace, and the definition of HPC changes accordingly. In general, it pertains to the use of multiple processors or computers to accomplish a complex task concurrently with high throughput and efficiency. It is common to consider HPC as not only a computing architecture but also as a set of elements, including hardware systems, software tools, programming platforms, and parallel programming paradigms. Over the last decade, high-performance computing has evolved significantly, particularly because of the emergence of GPU-CPU heterogeneous architectures, which have led to a fundamental paradigm shift in parallel programming. This chapter begins your understanding of heterogeneous parallel programming.
From a pure calculation perspective, parallel computing can be defined as a form of computation in which many calculations are carried out simultaneously, operating on the principle that large problems can often be divided into smaller ones, which are then solved concurrently.
In fact, parallel computing usually involves two distinct areas of computing technologies:
- Computer architecture (hardware aspect)
- Parallel programming (software aspect)
Computer architecture focuses on supporting parallelism at an architectural level, while parallel programming focuses on solving a problem concurrently by fully using the computational power of the computer architecture. In order to achieve parallel execution in software, the hardware must provide a platform that supports concurrent execution of multiple processes or multiple threads.
Most modern processors implement the Harvard architecture, as shown in Figure 1-1, which is comprised of three main components:
- Memory (instruction memory and data memory)
- Central processing unit (control unit and arithmetic logic unit)
- Input/Output interfaces
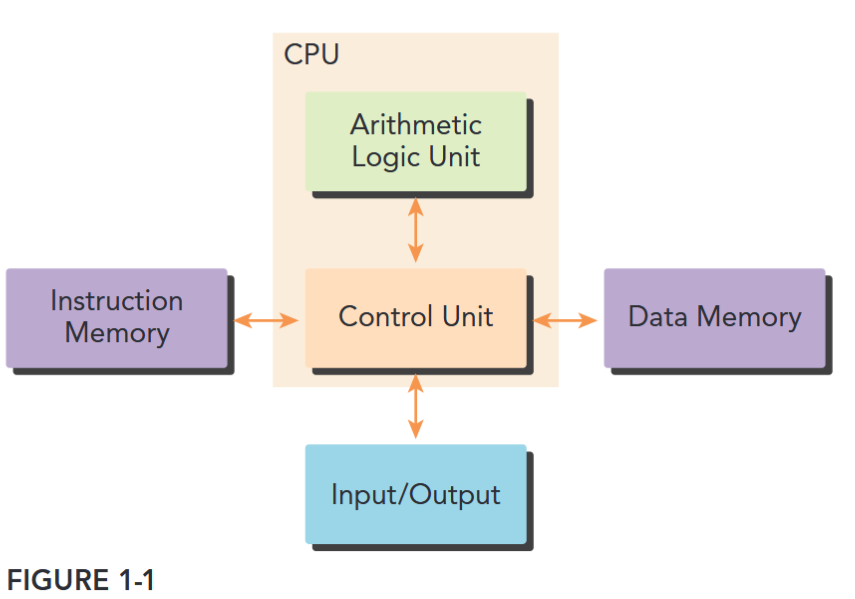
The key component in high-performance computing is the central processing unit (CPU), usually called the core. In the early days of the computer, there was only one core on a chip. This architecture is referred to as a uniprocessor. Nowadays, the trend in chip design is to integrate multiple cores onto a single processor, usually termed multicore, to support parallelism at the architecture level. Therefore, programming can be viewed as the process of mapping the computation of a problem to available cores such that parallel execution is obtained.
Parallel Programming
When solving a problem with a computer program, it is natural to divide the problem into a discrete series of calculations; each calculation performs a specified task, as shown in Figure 1-2. Such a program is called a sequential program.
There are two ways to classify the relationship between two pieces of computation: Some are related by a precedence restraint and therefore must be calculated sequentially; others have no such restraints and can be calculated concurrently. Any program containing tasks that are performed concurrently is a parallel program. As shown in Figure 1-3, a parallel program may, and most likely will, have some sequential parts.
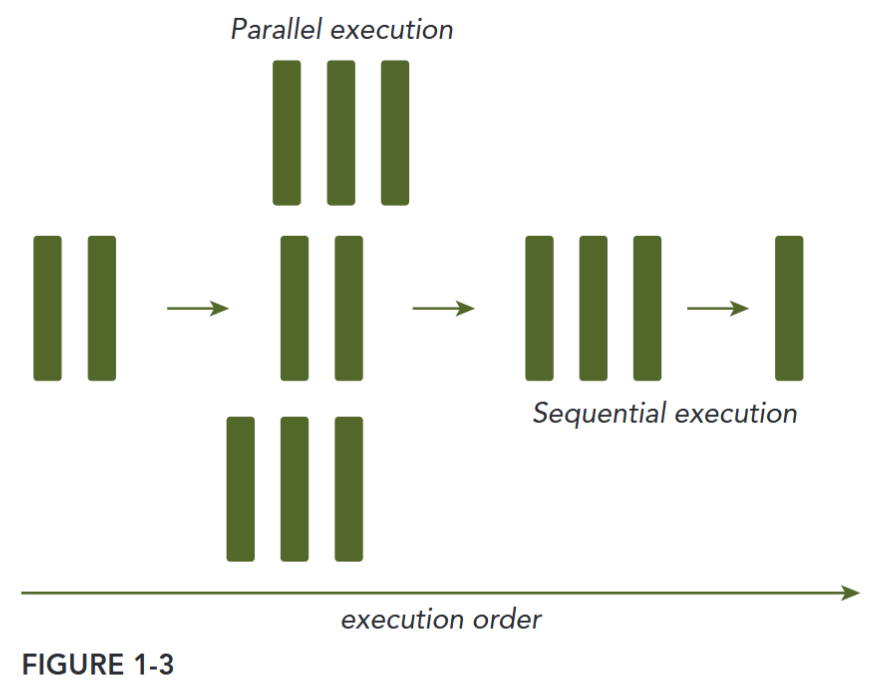
From the eye of a programmer, a program consists of two basic ingredients: instruction and data. When a computational problem is broken down into many small pieces of computation, each piece is called a task. In a task, individual instructions consume inputs, apply a function, and produce outputs. A data dependency occurs when an instruction consumes data produced by a preceding instruction. Therefore, you can classify the relationship between any two tasks as either dependent, if one consumes the output of another, or independent.
There are two fundamental types of parallelism in applications:
- Task parallelism. Task parallelism arises when there are many tasks or functions that can be operated independently and largely in parallel. Task parallelism focuses on distributing functions across multiple cores.
- Data parallelism. Data parallelism arises when there are many data items that can be operated on at the same time. Data parallelism focuses on distributing the data across multiple cores.
CUDA programming is especially well-suited to address problems that can be expressed as dataparallel computations.
DATA PARTITIONS There are two basic approaches to partitioning data:
- Block: Each thread takes one portion of the data, usually an equal portion of the data.
- Cyclic: Each thread takes more than one portion of the data. The performance of a program is usually sensitive to the block size.
Computer Architecture
There are several different ways to classify computer architectures. One widely used classification scheme is Flynn’s Taxonomy, which classifies architectures into four different types according to how instructions and data flow through cores (see Figure 1-6), including:
- Single Instruction Single Data (SISD)
- Single Instruction Multiple Data (SIMD)
- Multiple Instruction Single Data (MISD)
- Multiple Instruction Multiple Data (MIMD)
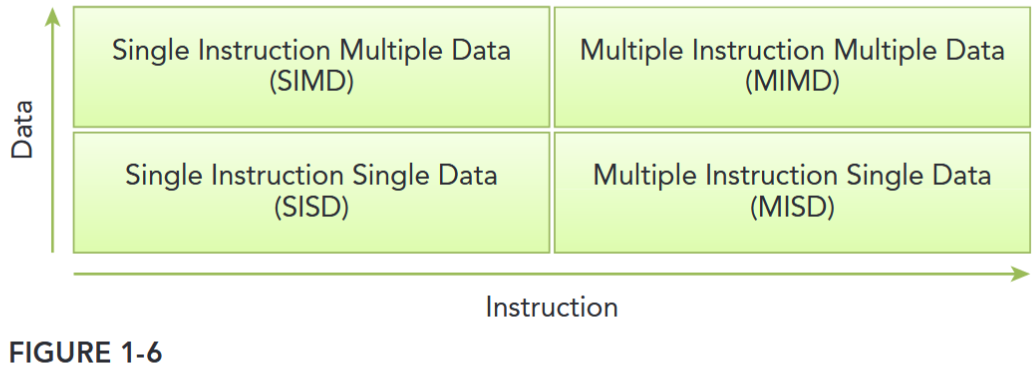
- Single Instruction Single Data refers to the traditional computer: a serial architecture. There is only one core in the computer. At any time only one instruction stream is executed, and operations are performed on one data stream.
- Single Instruction Multiple Data refers to a type of parallel architecture. There are multiple cores in the computer. All cores execute the same instruction stream at any time, each operating on different data streams. Vector computers are typically characterized as SIMD, and most modern computers employ a SIMD architecture.
- Multiple Instruction Single Data refers to an uncommon architecture, where each core operates on the same data stream via separate instruction streams.
- Multiple Instruction Multiple Data refers to a type of parallel architecture in which multiple cores operate on multiple data streams, each executing independent instructions. Many MIMD architectures also include SIMD execution sub-components.
At the architectural level, many advances have been made to achieve the following objectives:
- Decrease latency. Latency is the time it takes for an operation to start and complete.
- Increase bandwidth. Bandwidth is the amount of data that can be processed per unit of time.
- Increase throughput. Throughput is the amount of operations that can be processed per unit of time
Latency measures the time to complete an operation, while throughput measures the number of operations processed in a given time unit.
Computer architectures can also be subdivided by their memory organization, which is generally classified into the following two types:
- Multi-node with distributed memory
- Multiprocessor with shared memory
In a multi-node system, large scale computational engines are constructed from many processors connected by a network. Each processor has its own local memory, and processors can communicate the contents of their local memory over the network. Figure 1-7 shows a typical multi-node system with distributed memory. These systems are often referred to as clusters.
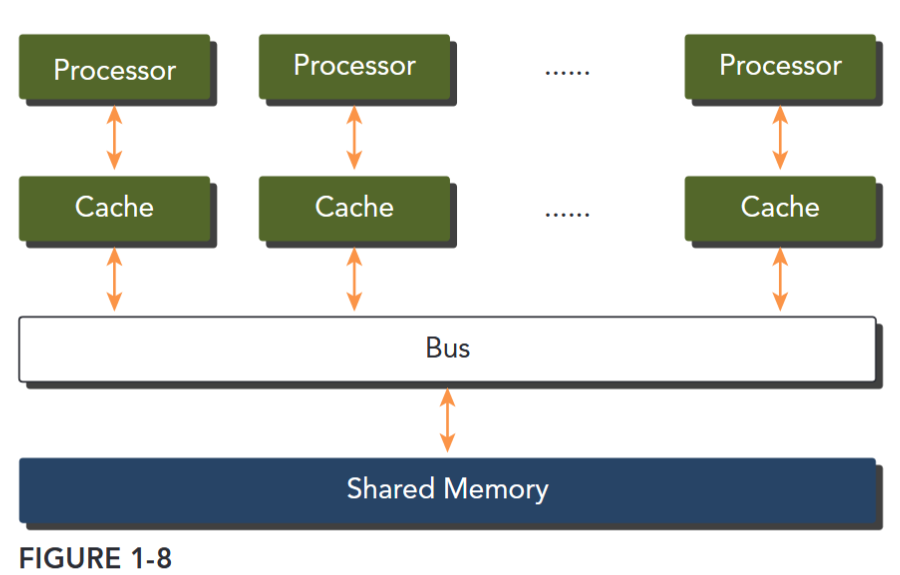
Multiprocessor architectures typically range in size from dual-processor to dozens or hundreds of processors. These processors are either physically connected to the same memory (as shown in Figure 1-8), or share a low-latency link (such as PCI-Express or PCIe). Although sharing memory implies a shared address space, it does not necessarily mean there is a single physical memory. Such multiprocessors include both single-chip systems with multiple cores, known as multicore, and computers consisting of multiple chips, each of which might have a multicore design. Multicore architectures have displaced single-core architectures permanently.
GPUs represent a many-core architecture, and have virtually every type of parallelism described previously: multithreading, MIMD, SIMD, and instruction-level parallelism. NVIDIA coined the phrase Single Instruction, Multiple Thread (SIMT) for this type of architecture.
GPU CORE VERSUS CPU CORE
Even though many-core and multicore are used to label GPU and CPU architectures, a GPU core is quite different than a CPU core.
- A CPU core, relatively heavy-weight, is designed for very complex control logic, seeking to optimize the execution of sequential programs.
- A GPU core, relatively light-weight, is optimized for data-parallel tasks with simpler control logic, focusing on the throughput of parallel programs.
HETEROGENEOUS COMPUTING
异构计算架构
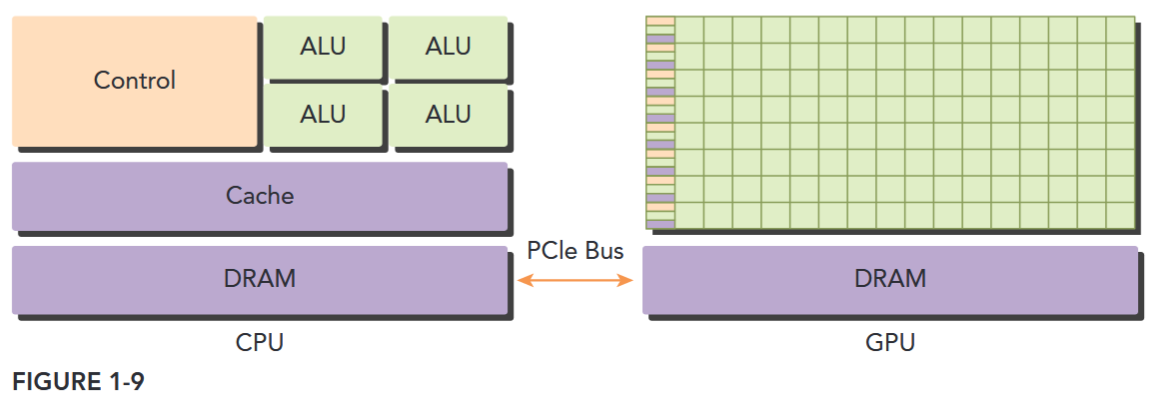
A typical heterogeneous compute node nowadays consists of two multicore CPU sockets and two or more many-core GPUs. A GPU is currently not a standalone platform but a co-processor to a CPU. Therefore, GPUs must operate in conjunction with a CPU-based host through a PCI-Express bus, as shown in Figure 1-9. That is why, in GPU computing terms, the CPU is called the host and the GPU is called the device.
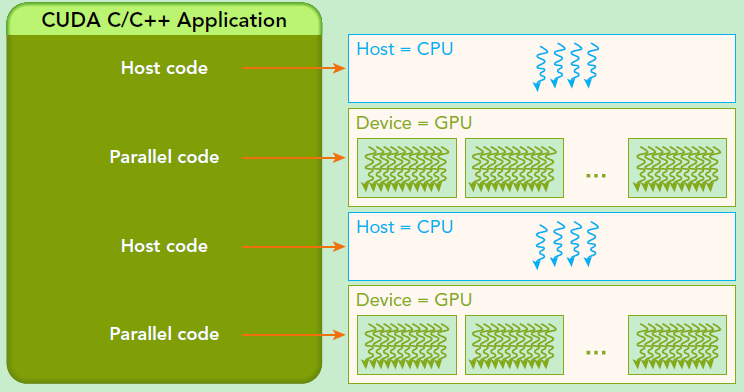
A heterogeneous application consists of two parts:
- Host code
- Device code Host code runs on CPUs and device code runs on GPUs. An application executing on a heterogeneous platform is typically initialized by the CPU. The CPU code is responsible for managing the environment, code, and data for the device before loading compute-intensive tasks on the device. With computational intensive applications, program sections often exhibit a rich amount of data parallelism. GPUs are used to accelerate the execution of this portion of data parallelism. When a hardware component that is physically separate from the CPU is used to accelerate computationally intensive sections of an application, it is referred to as a hardware accelerator.
可以看到 GPU 包括更多的运算核心,其特别适合数据并行的计算密集型任务,如大型矩阵运算,而 CPU 的运算核心较少,但是其可以实现复杂的逻辑运算,因此其适合控制密集型任务。另外,CPU 上的线程是重量级的,上下文切换开销大,但是 GPU 由于存在很多核心,其线程是轻量级的。因此,基于 CPU+GPU 的异构计算平台可以优势互补,CPU 负责处理逻辑复杂的串行程序,而 GPU 重点处理数据密集型的并行计算程序,从而发挥最大功效。
There are two important features that describe GPU capability:
- Number of CUDA cores
- Memory size
Accordingly, there are two different metrics for describing GPU performance:
- Peak computational performance. Peak computational performance is a measure of computational capability, usually defined as how many single-precision or double-precision floating point calculations can be processed per second.
- Memory bandwidth. Memory bandwidth is a measure of the ratio at which data can be read from or stored to memory.
CPU computing is good for control-intensive tasks, and GPU computing is good for data-parallel computation-intensive tasks.
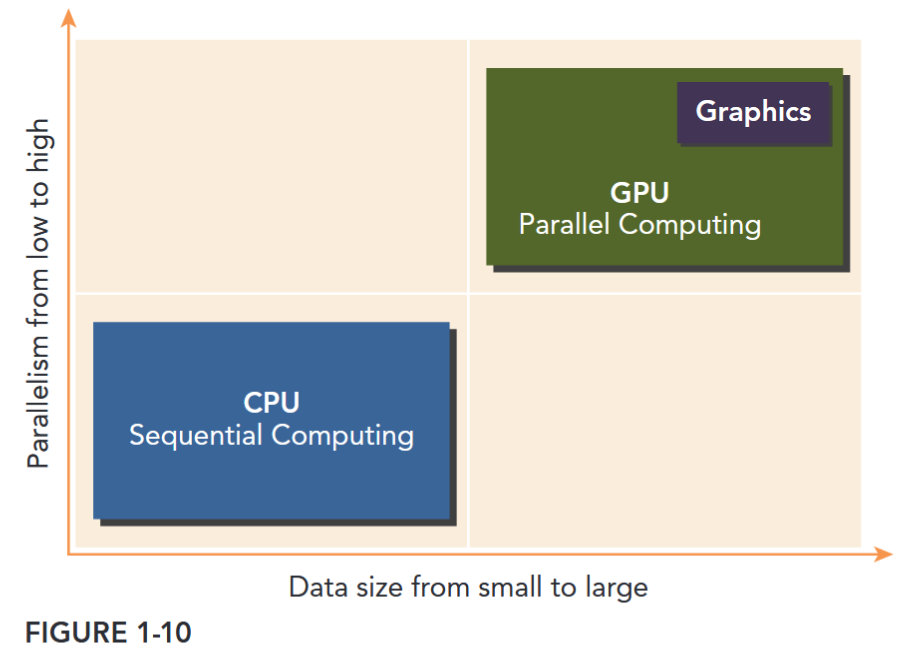
The CPU is optimized for dynamic workloads marked by short sequences of computational operations and unpredictable control flow; and GPUs aim at the other end of the spectrum: workloads that are dominated by computational tasks with simple control flow. As shown in Figure 1-10, there are two dimensions that differentiate the scope of applications for CPU and GPU:
- Parallelism level
- Data size If a problem has a small data size, sophisticated control logic, and/or low-level parallelism, the CPU is a good choice because of its ability to handle complex logic and instruction-level parallelism. If the problem at hand instead processes a huge amount of data and exhibits massive data parallelism, the GPU is the right choice because it has a large number of programmable cores, can support massive multi-threading, and has a larger peak bandwidth compared to the CPU.
CPU THREAD VERSUS GPU THREAD
CPU 上的线程通常是重量级实体。操作系统必须在线程之间切换,将它们换入和换出 CPU 执行通道,以提供多线程能力。上下文切换速度慢且成本高。 GPU 上的线程则极其轻量。在典型系统中,有成千上万个线程排队等待处理任务。如果 GPU 必须等待一组线程,它会直接开始执行另一组线程的任务。 CPU 核心旨在最大限度地减少同时处理一两个线程时的延迟,而 GPU 核心则旨在处理大量并发的轻量级线程,以最大限度地提高吞吐量。 GPU(Graphics Processing Unit)在相同的价格和功率范围内,比 CPU 提供更高的指令吞吐量和内存带宽。许多应用程序利用这些更高的能力,使得自己在 GPU 上比在 CPU 上运行得更快。其他计算设备,如 FPGA,也非常节能,但提供的编程灵活性要比 GPU 少得多。
GPU 和 CPU 之间的主要区别在于设计思想的不同。CPU 的设计初衷是为了实现在执行一系列操作(称之为一个 thread)时达到尽可能高的性能,同时可能只能实现其中数十个线程的并行化,GPU 的设计初衷是为了实现在在并行执行数千个线程时达到尽可能高的性能(通过分摊较慢的单线程程序以实现更高的吞吐量)。
为了能够实现更高强度的并行计算,GPU 将更多的晶体管用于数据计算而不是数据缓存或控制流。下图显示了 CPU 与 GPU 的芯片资源分布示例。
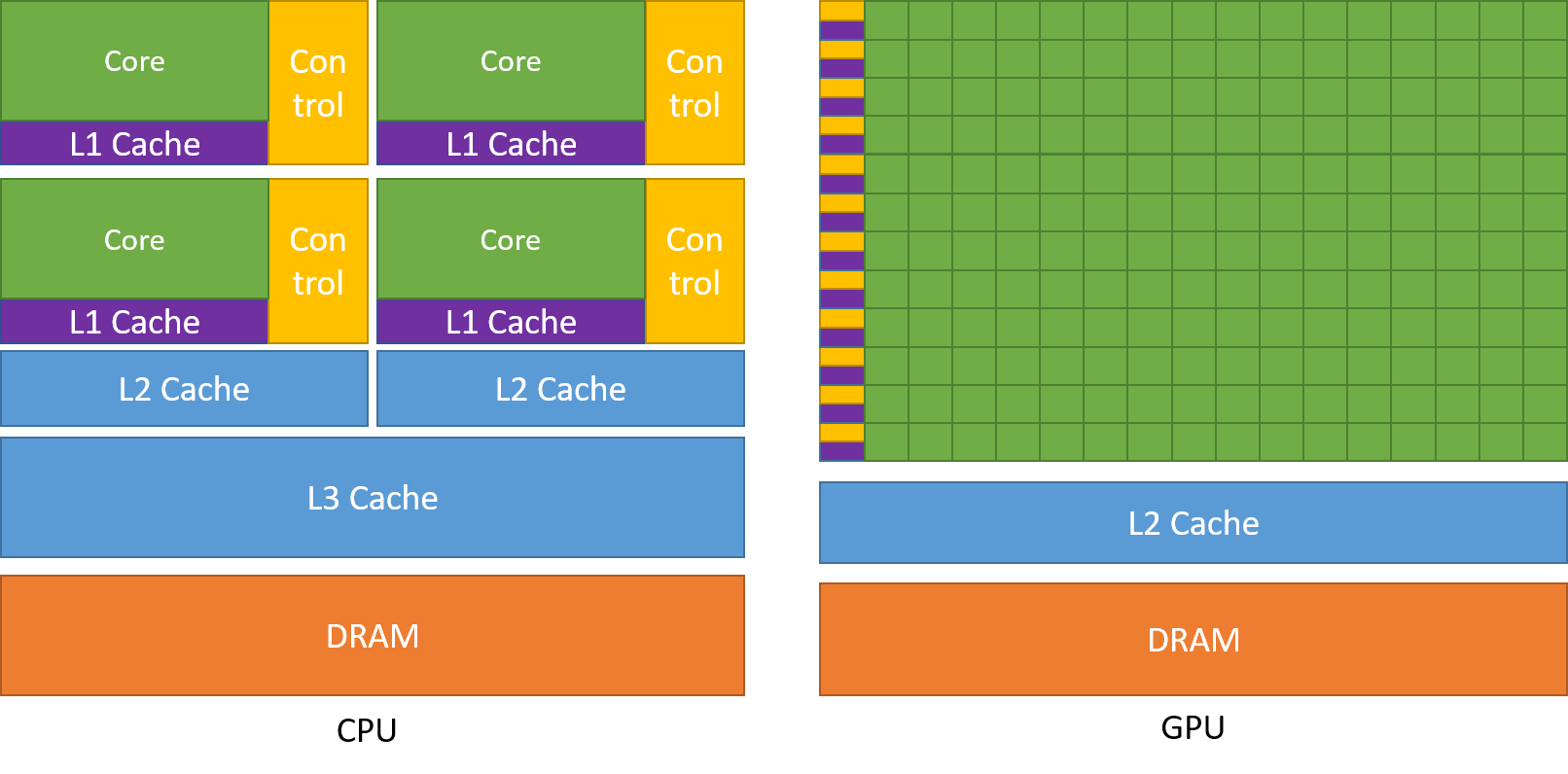
一般来说,应用程序有并行和串行部分,所以系统可以利用 GPU 和 CPU 的混搭来获得更高的整体性能。对于并行度高的程序也可以利用 GPU 的大规模并行特性来实现比 CPU 更高的性能。
CUDA:通用并行计算平台和程序模型
CUDA(Compute Unified Device Architecture)是 NVIDIA 推出的通用并行计算平台和程序模型,它利用 NVIDIA GPU 中的并行计算引擎以比 CPU 更有效的方式加速计算密集型任务(如图形处理、深度学习、科学计算)。
The CUDA platform is accessible through CUDA-accelerated libraries, compiler directives, application programming interfaces, and extensions to industry-standard programming languages, including C, C++, Fortran, and Python (as illustrated by Figure 1-12).
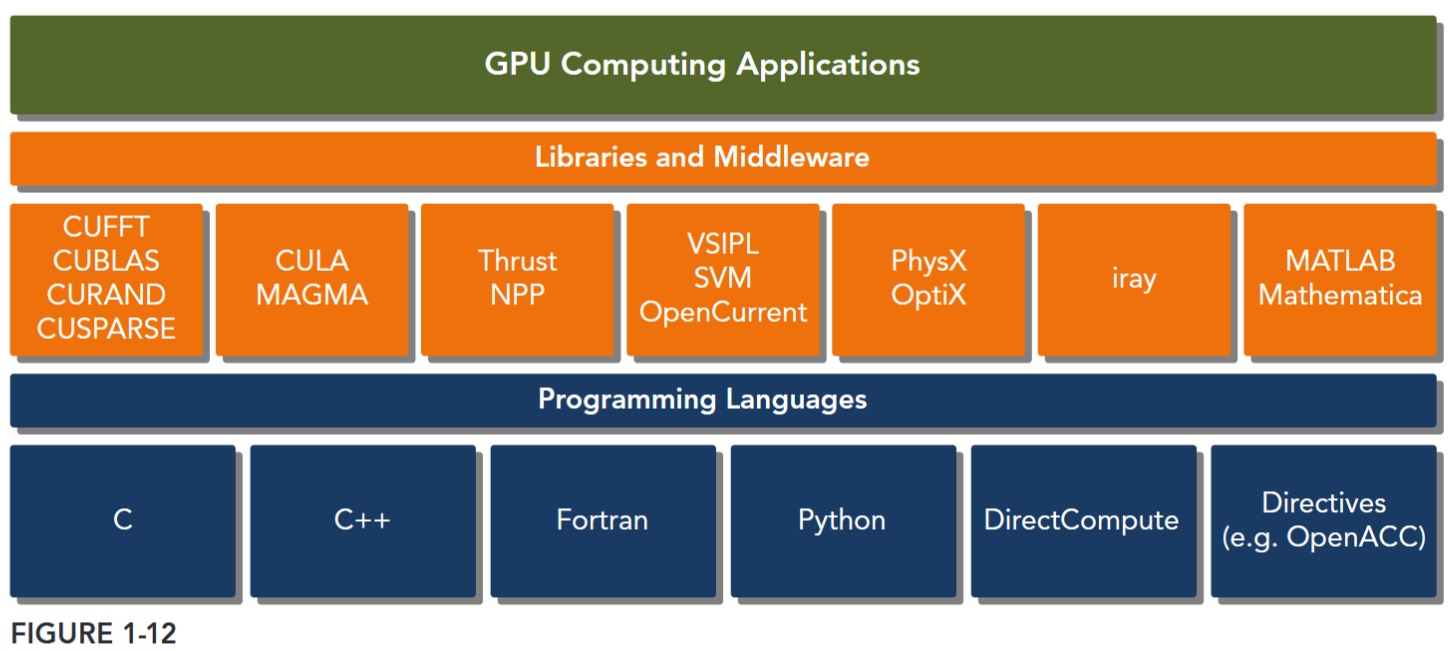
CUDA C is an extension of standard ANSI C with a handful of language extensions to enable heterogeneous programming, and also straightforward APIs to manage devices, memory, and other tasks. CUDA is also a scalable programming model that enables programs to transparently scale their parallelism to GPUs with varying numbers of cores, while maintaining a shallow learning curve for programmers familiar with the C programming language.
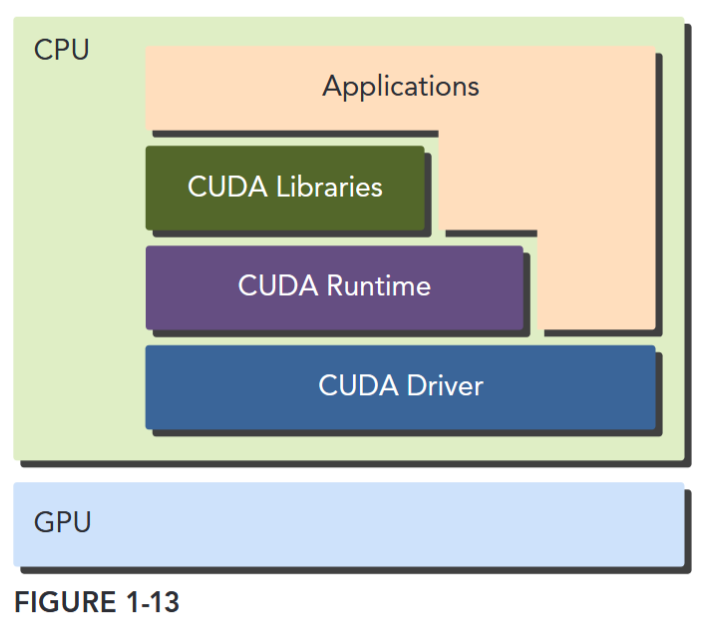
CUDA provides two API levels for managing the GPU device and organizing threads, as shown in Figure 1-13.
- CUDA Driver API
- CUDA Runtime API The driver API is a low-level API and is relatively hard to program, but it provides more control over how the GPU device is used. The runtime API is a higher-level API implemented on top of the driver API. Each function of the runtime API is broken down into more basic operations issued to the driver API.
A CUDA program consists of a mixture of the following two parts:
- The host code runs on CPU.
- The device code runs on GPU.
NVIDIA’s CUDA
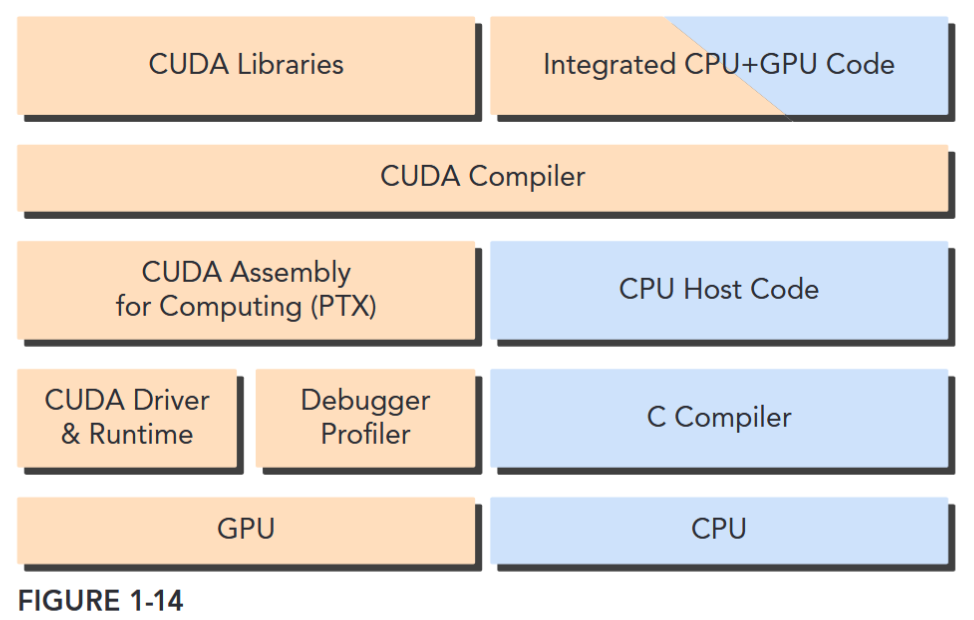
nvcccompiler separates the device code from the host code during the compilation process. As shown in Figure 1-14, the host code is standard C code and is further compiled with C compilers. The device code is written using CUDA C extended with keywords for labeling data-parallel functions, called kernels. The device code is further compiled bynvcc. During the link stage, CUDA runtime libraries are added for kernel procedure calls and explicit GPU device manipulation.
The CUDA nvcc compiler is based on the widely used LLVM open source compiler infrastructure. You can create or extend programming languages with support for GPU acceleration using the CUDA Compiler SDK, as shown in Figure 1-15.
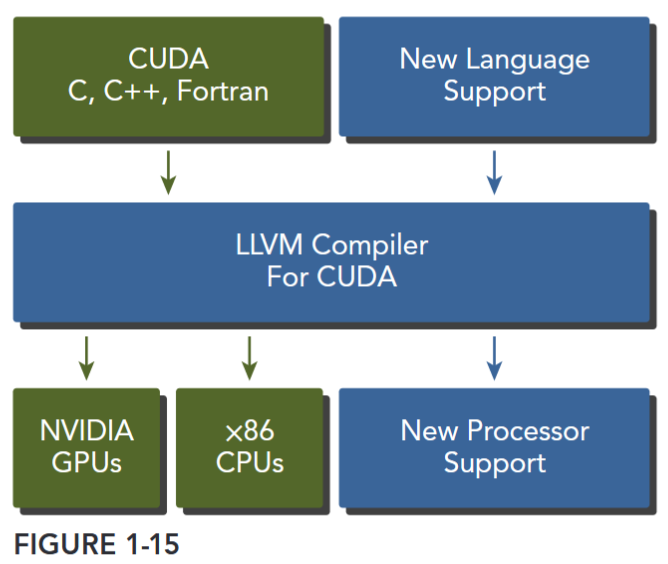
The CUDA Toolkit includes a compiler, math libraries, and tools for debugging and optimizing the performance of your applications.
A Scalable Programming Model
多核 CPU 和超多核 (manycore) GPU 的出现,意味着主流处理器进入并行时代。当下开发应用程序的挑战在于能够利用不断增加的处理器核数实现对于程序并行性透明地扩展,例如 3D 图像应用可以透明地拓展其并行性来适应内核数量不同的 GPUs 硬件。
CUDA 并行程序模型主要为克服这一挑战而设计,其对于程序员具有较小的学习难度,因为其使用了标准编程语言如 C。其核心是三个关键抽象——线程组的层次结构、共享内存和屏障同步——它们只是作为最小的语言扩展集向程序员公开。
这些抽象提供了细粒度的数据并行性和线程并行性,并将嵌套在粗粒度的数据并行和任务并行中。它们指导程序员将主问题拆解为可以线程块独立并行解决的粗粒度子问题,同时每个子问题可以被进一步细分为更小的组成部分,其可以被每个线程块中的线程通过并行合作的方式解决。
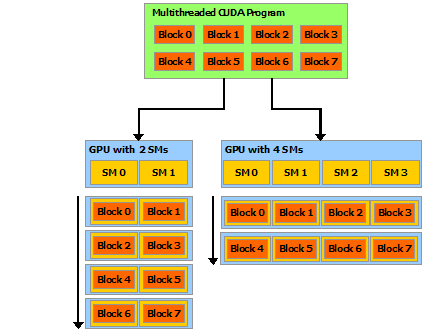
这种分解通过允许线程在求解每个子问题时进行协作,保留了语言的表达能力,同时实现了自动可扩展性。实际上,每个线程块可被调度到 GPU 内任何可用的多处理器上,调度顺序、方式(并发或串行)均不受限制。因此,如图 3 所示,已编译的 CUDA 程序能够在任意数量的多处理器上执行,且仅需运行时系统知晓物理多处理器的数量。
这种可扩展的编程模型使得 GPU 架构能够通过简单调整多处理器和内存分区的数量来覆盖广泛的市场范围。
SM
注意:GPU 是围绕一系列流式多处理器 (SM: Streaming Multiprocessors) 构建的(有关详细信息,请参 阅硬件实现)。多线程程序被划分为彼此独立执行的线程块,因此具有更多多处理器的 GPU 将比具有更少多处理器的 GPU 在更短的时间内完成程序执行。