LIST "Megatron Repository"
FROM ""
WHERE file.folder = this.file.folder OR startswith(file.folder, this.file.folder + "/")
SORT file.pathreference: Megatron-LM | DeepWiki
Overview
Purpose and Scope
This document provides a comprehensive overview of the Megatron-LM framework, a GPU-optimized system for training large-scale transformer models. Megatron-LM combines cutting-edge research implementations with production-ready training infrastructure, enabling efficient training of models with hundreds of billions of parameters across thousands of GPUs.
The framework consists of two main components:
- Megatron-LM (research-oriented training scripts and model implementations) and
- Megatron-Core (production-ready library of GPU-optimized techniques).
This documentation covers the entire system architecture, from core transformer implementations to distributed training orchestration and inference deployment.
For detailed information about specific subsystems, see: Core Architecture, Parallelism Strategies, Training System, Data Processing, Inference System, Fine-tuning and Evaluation, and CD and Testing.
System Architecture Overview
Megatron-LM implements a layered architecture centered around Megatron-Core as the foundational library, with training orchestration, model implementations, and infrastructure components built on top. The system separates core GPU-optimized techniques from research implementations and production workflows.
Overall System Architecture
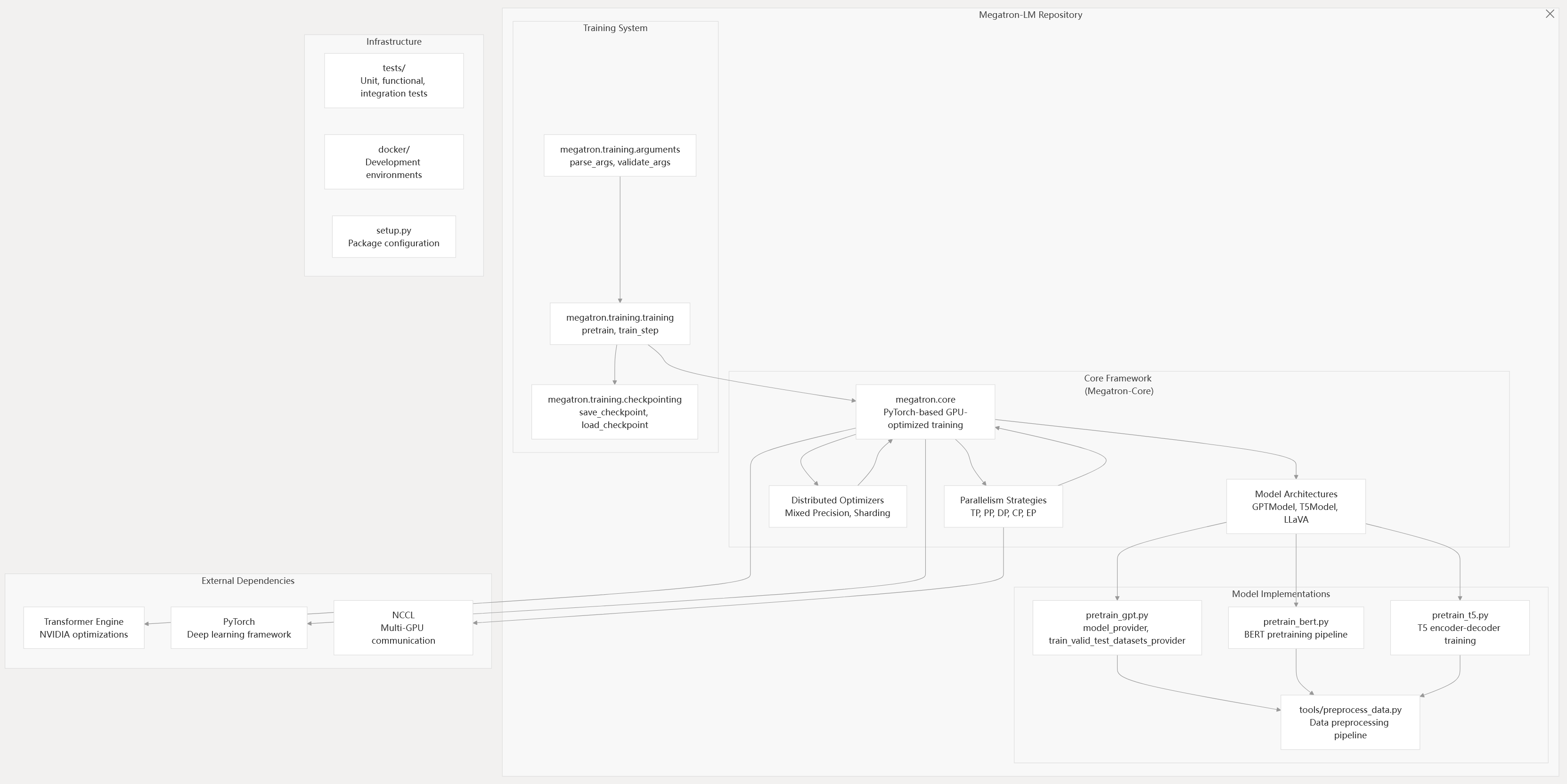
Sources: README.md71-86 arguments.py45-82 transformer_config.py32-38 training.py1-4
Core Components
Megatron-LM Vs Megatron-Core
The framework separates research implementations from production-ready infrastructure:
- Megatron-LM: Training scripts (
pretrain_gpt.py,pretrain_bert.py), tools, examples, and experimental features - Megatron-Core: Production library under
megatron.corewith versioned APIs, optimized implementations, and formal support
Training Pipeline and Model Architecture Flow
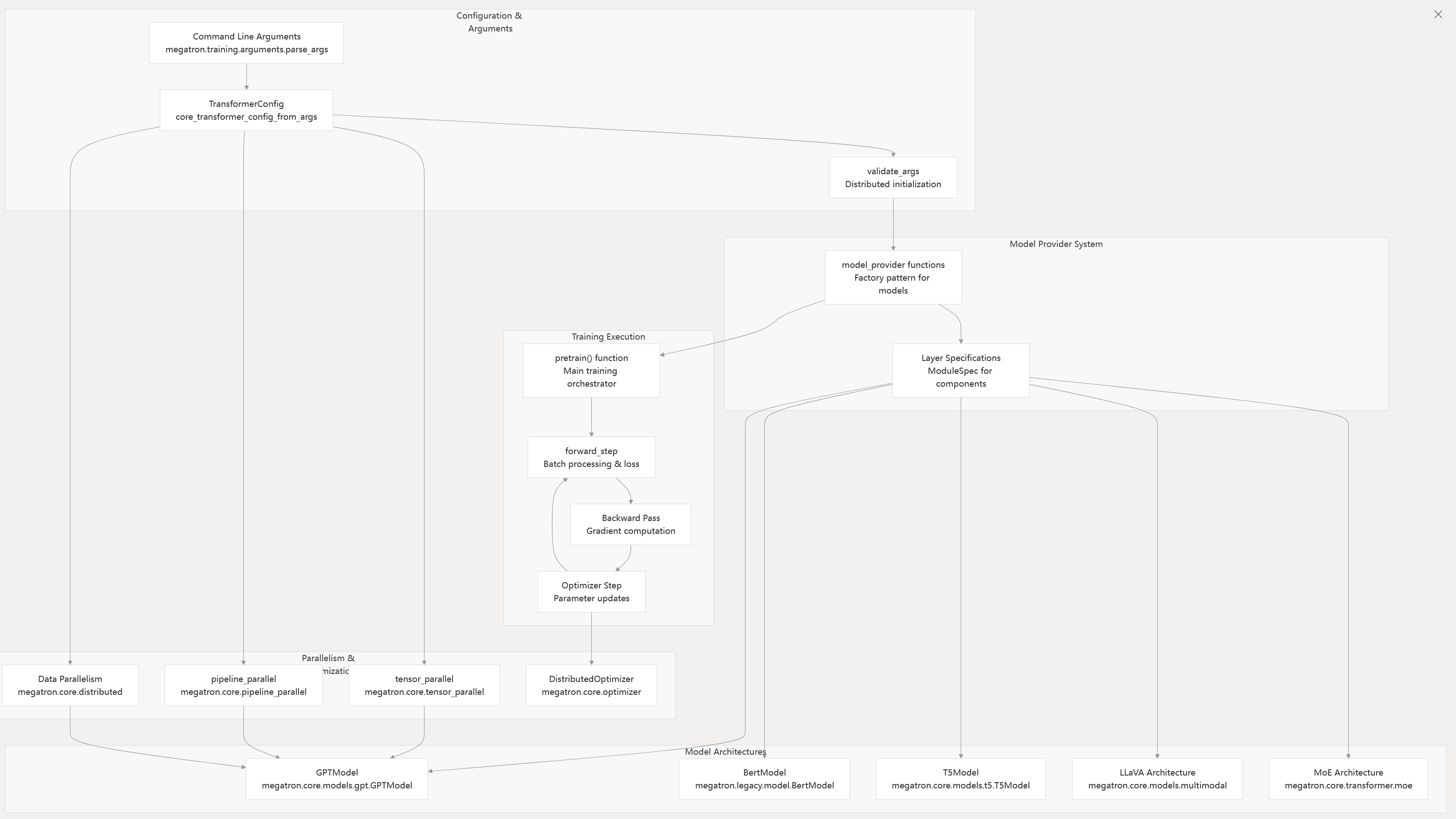
Sources: README.md75-85 arguments.py84-119 pretrain_gpt.py95-108 gpt_model.py34-75 training.py1-4
Supported Model Architectures
Megatron supports multiple transformer-based architectures through the TransformerConfig system:
| Architecture | Implementation | Key Classes | Use Case |
|---|---|---|---|
| GPT | megatron.core.models.gpt.GPTModel | GPTModel, LanguageModule | Autoregressive language modeling |
| BERT | megatron.legacy.model.BertModel | BertModel, MegatronModule | Bidirectional language understanding |
| T5 | megatron.core.models.t5.T5Model | T5Model, encoder-decoder | Text-to-text generation |
| Retro | megatron.core.models.retro | RetroModel | Retrieval-augmented generation |
| MoE | megatron.core.transformer.moe | MoELayer, expert routing | Mixture of experts scaling |
| LLaVA | megatron.core.models.multimodal | Multimodal fusion | Vision-language models |
| Mamba | examples/mamba/ | State space models | Sequence modeling with linear complexity |
Sources: README.md210-380 gpt_model.py34-75 transformer_config.py32-38
Parallelism Strategies
The framework implements comprehensive parallelism support through megatron.core.parallel_state and specialized modules:
- Tensor Parallelism (
--tensor-model-parallel-size):megatron.core.tensor_parallelsplits layers across GPUs - Pipeline Parallelism (
--pipeline-model-parallel-size):megatron.core.pipeline_parallel.schedulesdistributes transformer blocks - Data Parallelism:
megatron.core.distributed.DistributedDataParallelreplicates models with gradient sync - Sequence Parallelism (
--sequence-parallel): Distributes sequence dimension in layer norms and dropouts - Expert Parallelism (
--expert-model-parallel-size):megatron.core.transformer.moedistributes MoE experts - Context Parallelism (
--context-parallel-size): Handles long sequences via_CONTEXT_PARALLEL_GROUP
Sources: README.md292-306 layers.py1-4 schedules.py1-4 parallel_state.py22-106
Performance and Scalability
Training Performance
Megatron-LM demonstrates exceptional scaling characteristics across model sizes and hardware configurations:
- Model Scale: Supports models from 345M to 462B parameters
- Hardware Scale: Tested up to 6,144 H100 GPUs
- Efficiency: Achieves 41-48% Model FLOPs Utilization (MFU)
- Scaling Pattern: Shows superlinear weak scaling due to improved arithmetic intensity
Benchmark Results
| Model Size | GPUs | Global Batch Size | MFU | Throughput |
|---|---|---|---|---|
| 2B | 96 | 1152 | 41% | - |
| 175B | 1024 | 1536 | 47% | 138 TFLOP/GPU |
| 462B | 6144 | - | 48% | - |
Sources: README.md87-100
Getting Started
Entry Points
The framework provides multiple entry points for different use cases:
Training Scripts:
pretrain_gpt.py: GPT model pretrainingpretrain_bert.py: BERT model pretrainingpretrain_t5.py: T5 model pretraining
Data Processing:
tools/preprocess_data.py: Convert raw text to training format
Inference:
tools/run_text_generation_server.py: REST API server for text generationtools/text_generation_cli.py: Command-line interface for inference
Evaluation:
tasks/main.py: Downstream task evaluation
Basic Usage Pattern
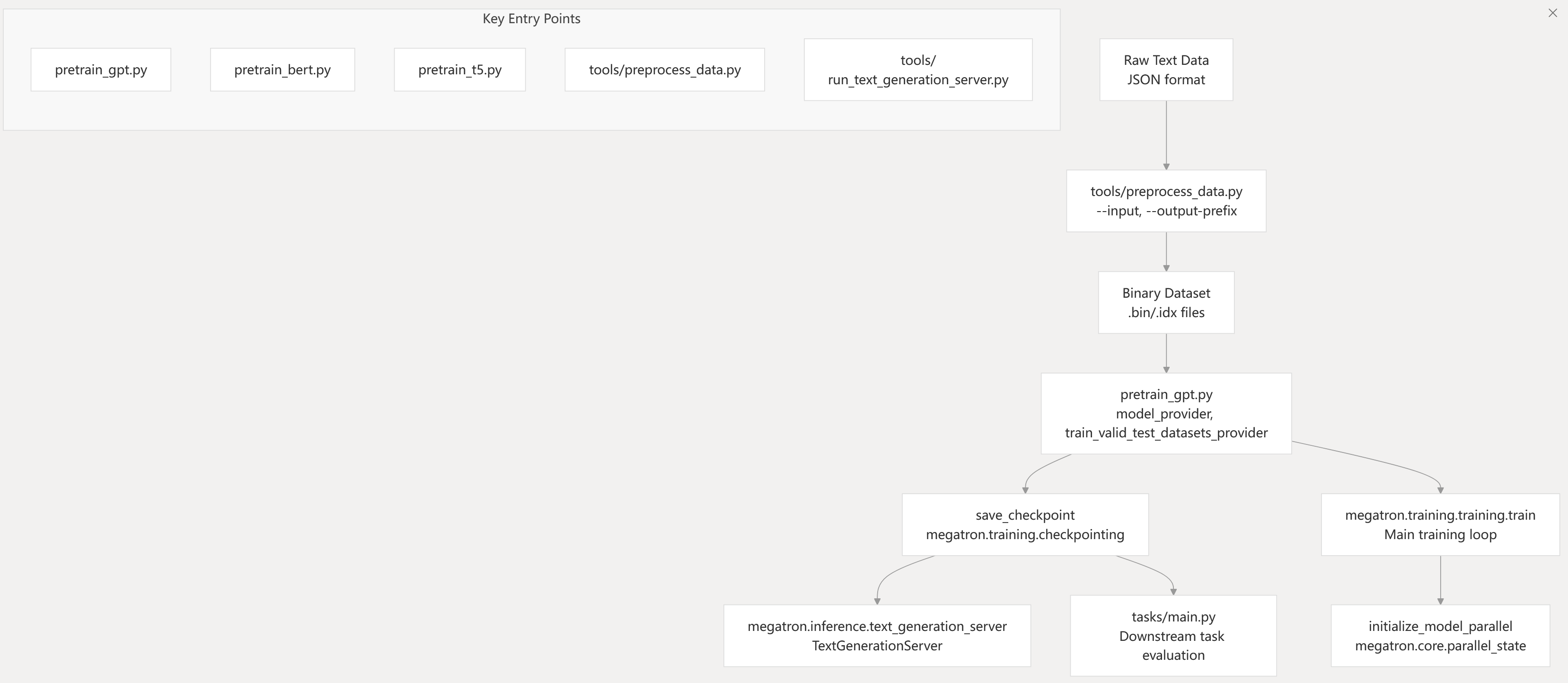
Sources: README.md199-212 README.md492-509 pretrain_gpt.py1-10 checkpointing.py1-4
Installation and Prerequisites
Dependencies
- PyTorch: Latest stable version
- CUDA/cuDNN/NCCL: Latest stable versions
- Hardware: NVIDIA Turing generation GPUs or later for best performance
- FP8 Support: Available on Hopper, Ada, and Blackwell architectures
Installation Options
- PyPI:
pip install megatron-core[dev]for latest features - Docker: NVIDIA PyTorch NGC Container (recommended)
- Source: Git clone with environment setup via
docker/common/install.sh
Sources: README.md101-184