This document provides an overview of Megatron-LM’s core architectural components and design patterns. It covers the foundational abstractions, configuration system, and modular design that enables flexible transformer model construction and distributed training.
For specific model implementations, see Model Implementations. For parallelism strategies, see Parallelism Strategies. For training system details, see [Training System](Training System | NVIDIA/Megatron-LM | DeepWiki).
Design Philosophy
Megatron-LM follows a configuration-driven, modular architecture that separates concerns between model definition, parallelism strategies, and training orchestration. The core design principles include:
Configuration-Driven Design: All model and training parameters flow through structured configuration objects, primarily TransformerConfig, which inherits from ModelParallelConfig. This ensures consistent parameter propagation across distributed components.
Modular Component System: Models are constructed using specification objects (ModuleSpec) that define component hierarchies. This enables flexible architecture composition while maintaining type safety and consistent initialization patterns.
Separation of Concerns: Core model implementations in megatron.core are independent of training logic, enabling reuse across different training scenarios and external integrations.
Distributed-First Design: All components are designed with distributed training in mind, with parallelism strategies integrated at the architectural level rather than as an afterthought.
Sources: transformer_config.py33-646 model_parallel_config.py9-15 spec_utils.py1-150
Core Abstractions
The architecture is built around several key abstractions that provide structure and extensibility:
Core Abstractions Hierarchy
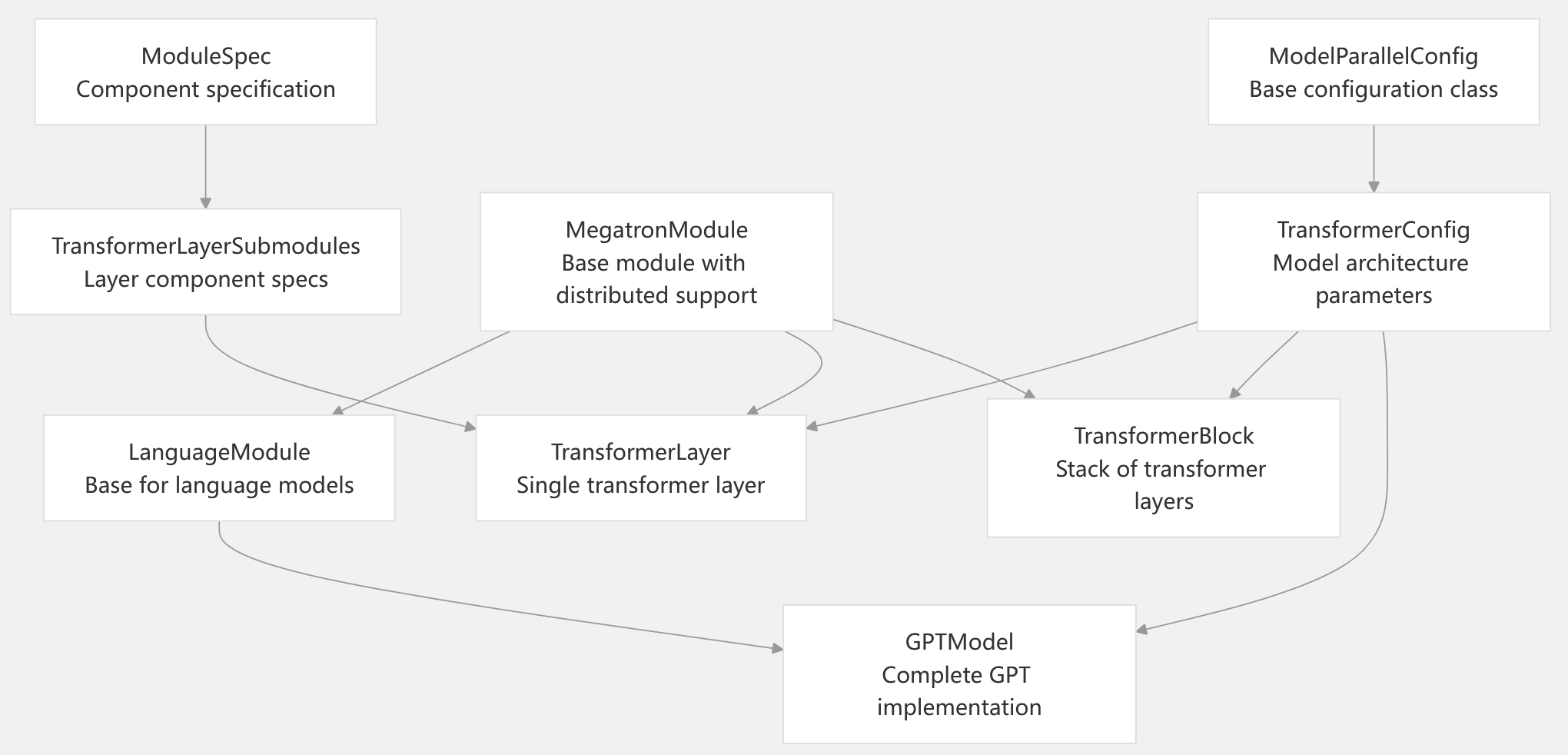
Base Classes
MegatronModule: All model components inherit from this base class, which extends torch.nn.Module with distributed training support, parameter sharing utilities, and standardized state dictionary management.
LanguageModule: Specialized base class for language models that adds model communication process groups and language model-specific utilities.
TransformerConfig: Central configuration object containing all transformer model parameters, including architecture dimensions, parallelism settings, optimization flags, and backend selections.
Sources: module.py27-80 language_module.py1-50 transformer_config.py33-646
Configuration Flow
The configuration system ensures consistent parameter propagation from command-line arguments through to individual model components:
Configuration System Architecture

Configuration Processing
Argument Parsing: The parse_args() function in arguments.py processes command-line arguments and performs validation, including compatibility checks between different parallelism settings and model configurations.
Config Construction: The core_transformer_config_from_args() function converts the parsed arguments into a TransformerConfig object, applying defaults and resolving interdependent parameters.
Model Factory: The model_provider() function serves as a factory that takes the configuration and constructs the appropriate model architecture, handling legacy model compatibility and different backend selections.
Sources: arguments.py84-119 arguments.py329-835 pretrain_gpt.py95-180
Module Specification System
Megatron uses a specification-based system to define model architectures, enabling flexible component composition while maintaining consistent interfaces:
Component Specification Pattern
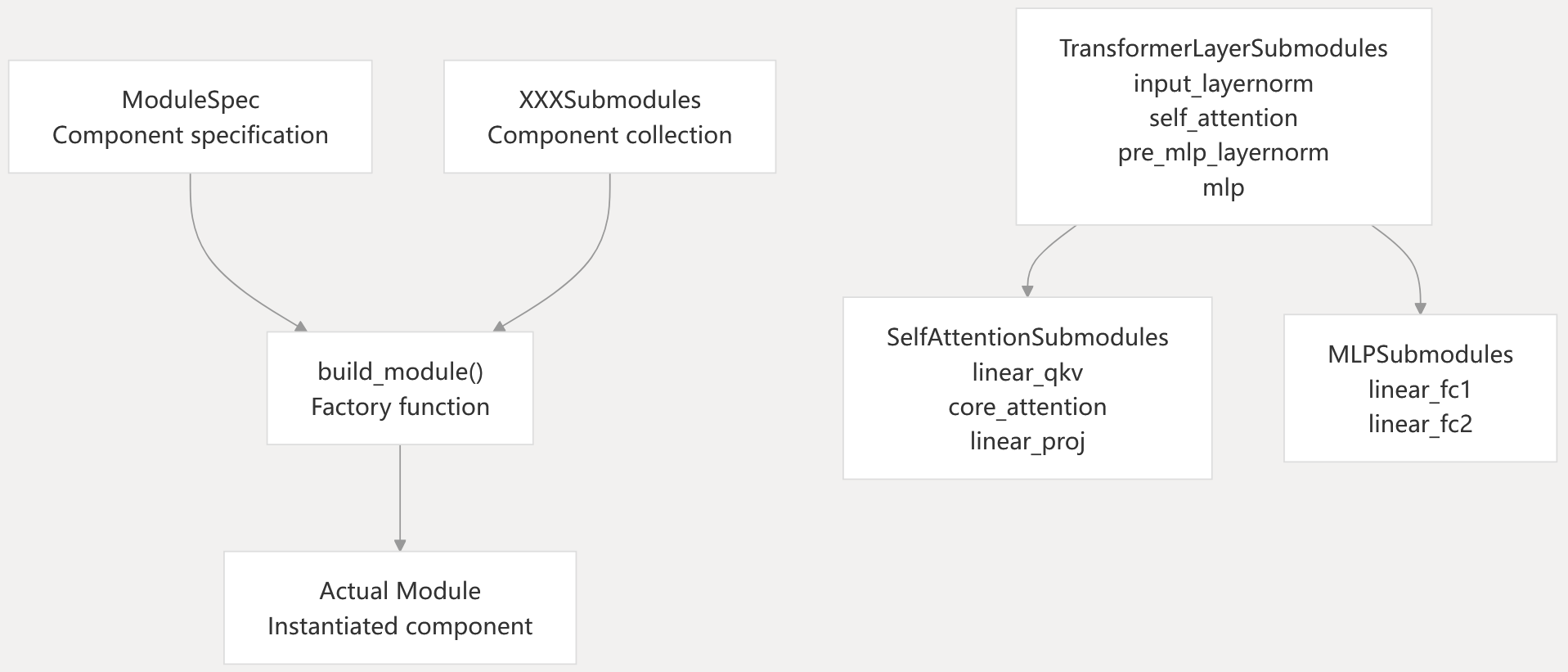
Specification Classes
ModuleSpec: Defines a component with its class, initialization arguments, and submodule specifications. Enables lazy instantiation and parameter injection.
Submodule Collections: Dataclasses like TransformerLayerSubmodules, SelfAttentionSubmodules, and MLPSubmodules define the structure of composite components.
Backend Integration
The specification system enables seamless backend switching:
- Transformer Engine Backend:
get_gpt_layer_with_transformer_engine_spec()creates specifications using TE-optimized components - Local Backend:
get_gpt_layer_local_spec()uses PyTorch-native implementations - Kitchen Backend: Quantization-aware specifications when Kitchen extensions are available
Sources: spec_utils.py20-150 transformer_layer.py196-238 gpt_layer_specs.py72-200
Model Construction Pipeline
The model construction follows a hierarchical pattern from high-level model down to individual components:
Construction Hierarchy
| Level | Component | Responsibility |
|---|---|---|
| Model | GPTModel | Complete model with embeddings, decoder, output layer |
| Block | TransformerBlock | Stack of transformer layers with layer norm |
| Layer | TransformerLayer | Single transformer layer with attention and MLP |
| Attention | SelfAttention | Multi-head attention mechanism |
| MLP | MLP | Feed-forward network |
| Primitives | ColumnParallelLinear, RowParallelLinear | Distributed linear layers |
Initialization Flow
- Configuration Validation:
TransformerConfig.__post_init__()validates parameter consistency and applies defaults - Spec Resolution: Backend-specific layer specifications are created based on configuration flags
- Hierarchical Construction: Models are built top-down, with each level instantiating its subcomponents
- Parameter Initialization: Weights are initialized according to the specified initialization methods, with distributed-aware parameter allocation
Sources: gpt_model.py77-235 transformer_block.py258-340 transformer_layer.py263-400
Integration with Training System
The core architecture integrates with the training system through well-defined interfaces that maintain separation of concerns:
Training Integration Points
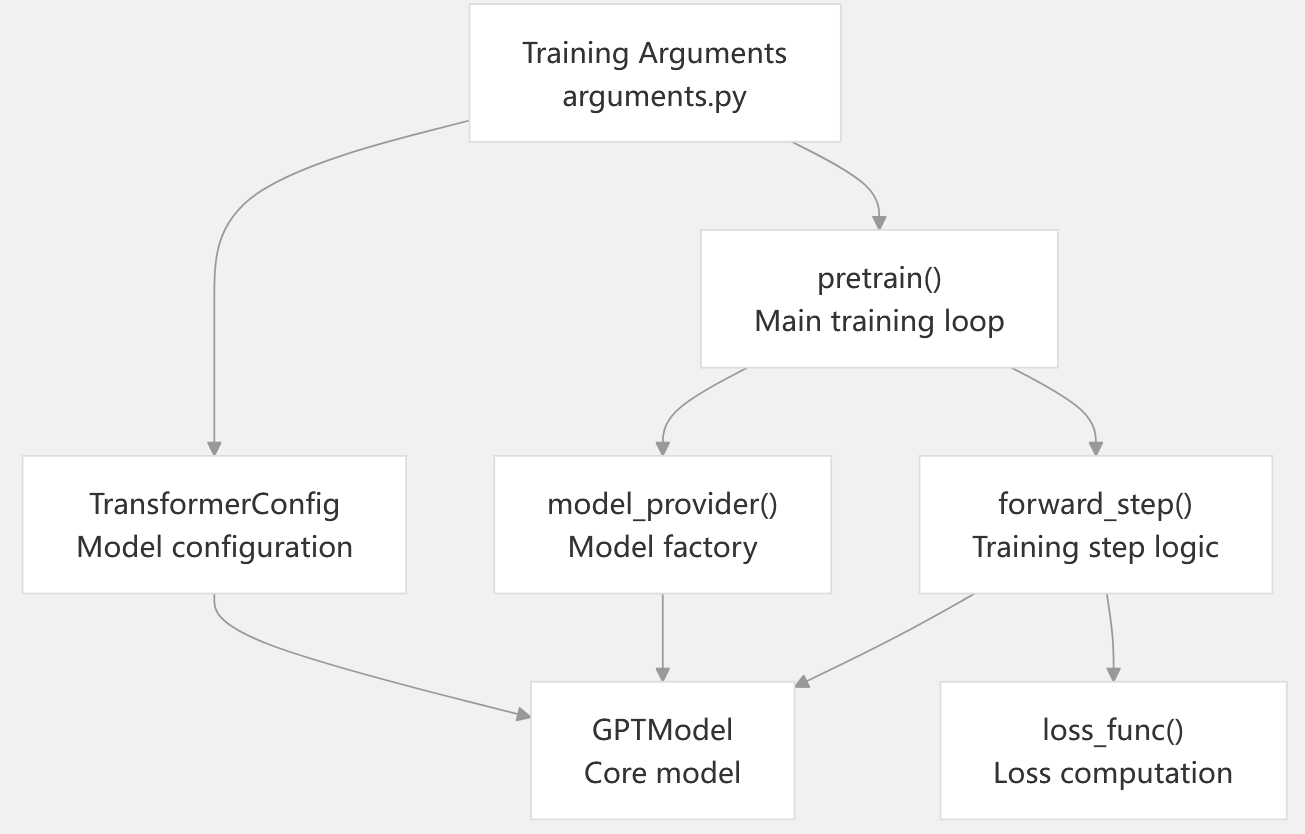
Interface Contracts
Model Provider Pattern: Training scripts implement a model_provider() function that returns model instances. This function is called by the training framework with appropriate parallelism context.
Forward Step Interface: Models implement a standard forward pass interface that accepts input tensors and returns output tensors and loss functions.
Configuration Contract: All model-specific parameters are encapsulated in TransformerConfig, while training-specific parameters remain in the arguments namespace.
Distributed Context: Models receive parallelism context through ModelCommProcessGroups, enabling communication-aware initialization without tight coupling to the training system.
Sources: training.py600-800 pretrain_gpt.py200-400 gpt_model.py100-410