Purpose and Scope
This document provides an overview of NCCL (NVIDIA Collective Communications Library), a high-performance library designed for optimized inter-GPU communication in distributed computing environments. NCCL implements standard collective communication primitives and point-to-point operations, supporting both single-node and multi-node GPU clusters across various interconnect technologies.
For detailed information about specific architectural components, see Architecture. For building and packaging details, see [Building and Packaging](CUDA Integration | NVIDIA/nccl | DeepWiki). For plugin system integration, see [Plugin System](Device-Side Operations | NVIDIA/nccl | DeepWiki).
What is NCCL
NCCL (pronounced “Nickel”) is a stand-alone library that provides optimized communication primitives for GPU-to-GPU data exchange. The library implements a comprehensive set of collective operations including:
| Operation | Description |
|---|---|
ncclAllReduce | Combines data from all GPUs using a reduction operation |
ncclAllGather | Gathers data from all GPUs to all GPUs |
ncclReduce | Combines data from all GPUs to a single GPU |
ncclBroadcast | Distributes data from one GPU to all GPUs |
ncclReduceScatter | Combines and distributes data across GPUs |
ncclSend/ncclRecv | Point-to-point communication patterns |
The library is optimized for various interconnect technologies including PCIe, NVLink, NVswitch, InfiniBand Verbs, and TCP/IP sockets, supporting arbitrary numbers of GPUs in single-process or multi-process (MPI) applications.
Sources: README.md3-7
High-Level Architecture
NCCL follows a layered architecture that abstracts hardware complexity while maximizing performance across different interconnect technologies.
Core System Architecture
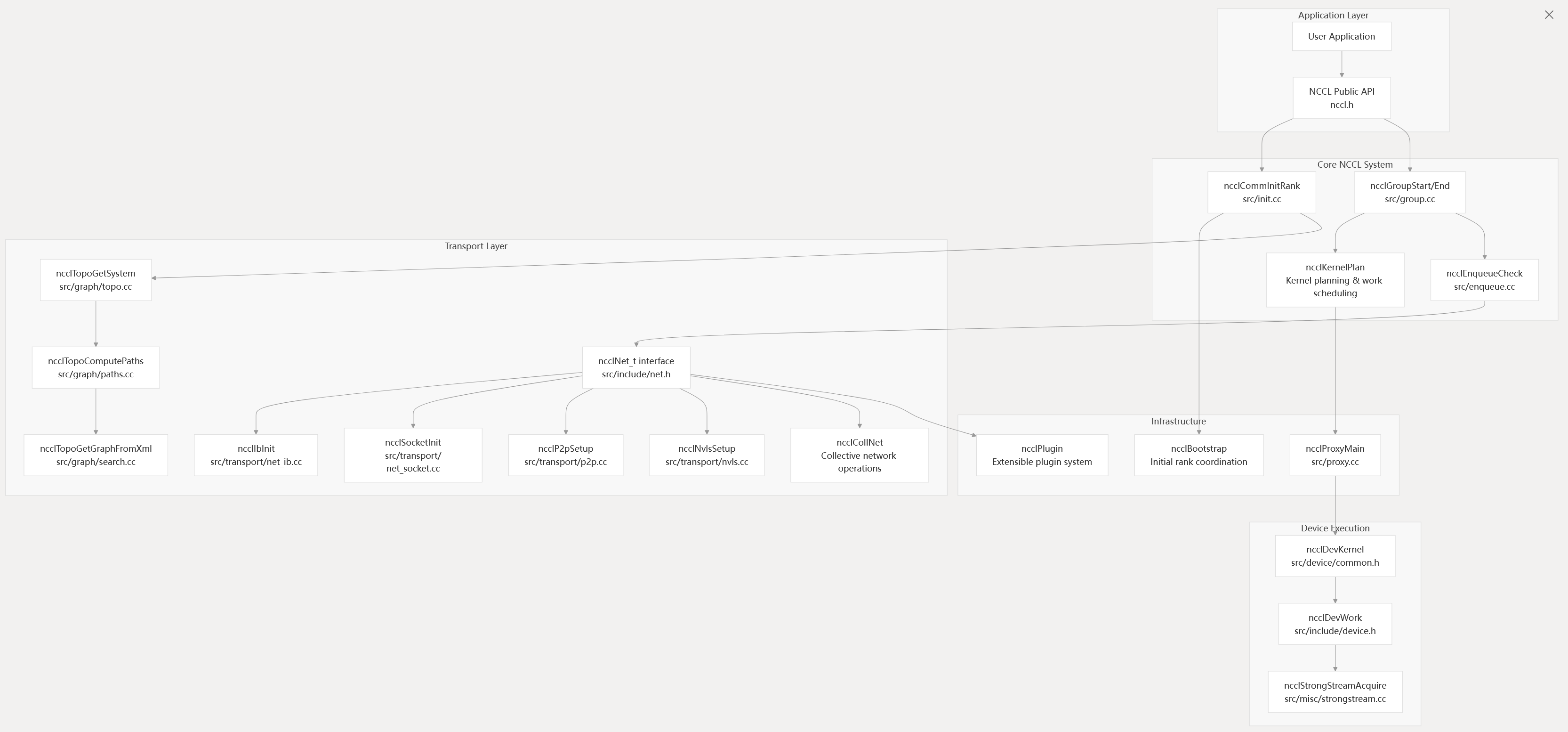
Sources: init.cc group.cc enqueue.cc topo.cc net_ib.cc proxy.cc
Core Component Interactions
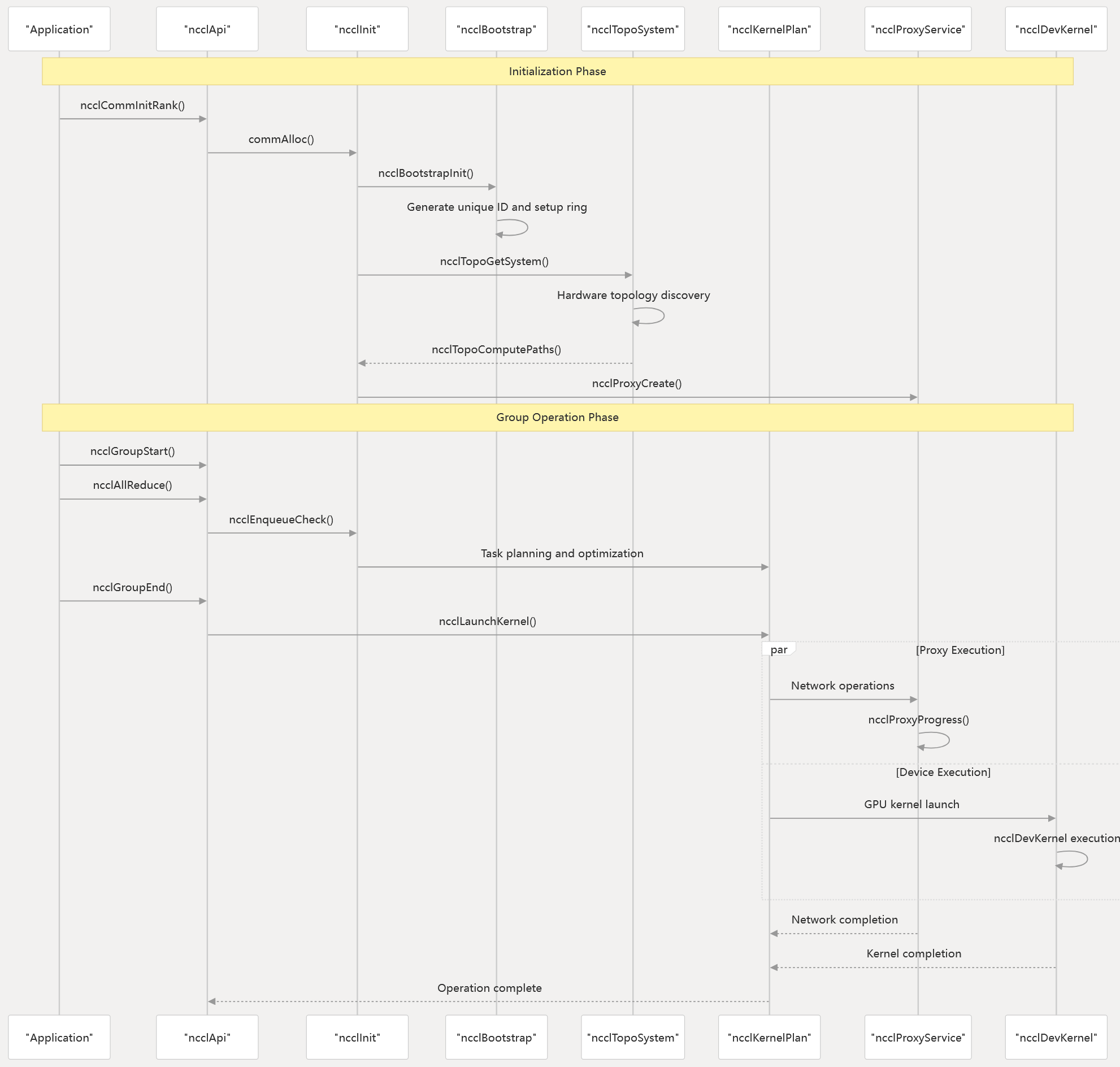
The following diagram illustrates how NCCL’s major components interact during a typical collective operation lifecycle:
Operation Flow and Component Coordination
Sources: init.cc group.cc enqueue.cc proxy.cc common.h
Key System Capabilities
NCCL provides several critical capabilities that enable high-performance distributed GPU computing:
Hardware Abstraction and Optimization
- Topology Discovery: Automatic detection of GPU and network hardware topology through
ncclTopoGetSystemin topo.cc - Path Optimization: Intelligent routing computation via
ncclTopoComputePathsfor optimal bandwidth utilization - Algorithm Selection: Dynamic selection of communication algorithms (ring, tree, NVLS, CollNet) based on hardware capabilities
Transport Layer Flexibility
- Multi-transport Support: Unified interface supporting InfiniBand (
ncclIbInit), TCP sockets (ncclSocketInit), and GPU-direct P2P (ncclP2pSetup) - Plugin Architecture: Extensible network plugin system through
ncclNet_tinterface in net.h - Proxy Service: Asynchronous network operation handling via
ncclProxyMainfor CPU offload
Performance Optimization Features
- Strong Stream Management: CUDA Graph capture support through
ncclStrongStreamAcquirein strongstream.cc - Memory Management: Optimized GPU memory registration and IPC mechanisms
- Kernel Fusion: Device-side operation batching through
ncclDevKernelstructures
Sources: topo.cc paths.cc net.h strongstream.cc src/device/common.h