This document provides a high-level overview of NCCL’s system architecture, showing how kernel planning, transport management, and topology optimization work together to orchestrate GPU communication operations. It covers the core flow from user API calls through task preparation to kernel execution.
For specific transport implementations, see Transport Layer. For detailed topology management, see Topology Management. For device-side execution details, see Device-Side Operations.
System Overview
NCCL’s core architecture revolves around transforming user-submitted collective and point-to-point operations into optimized GPU kernel execution plans. The system consists of several interconnected subsystems that handle task preparation, transport selection, topology optimization, and execution orchestration.
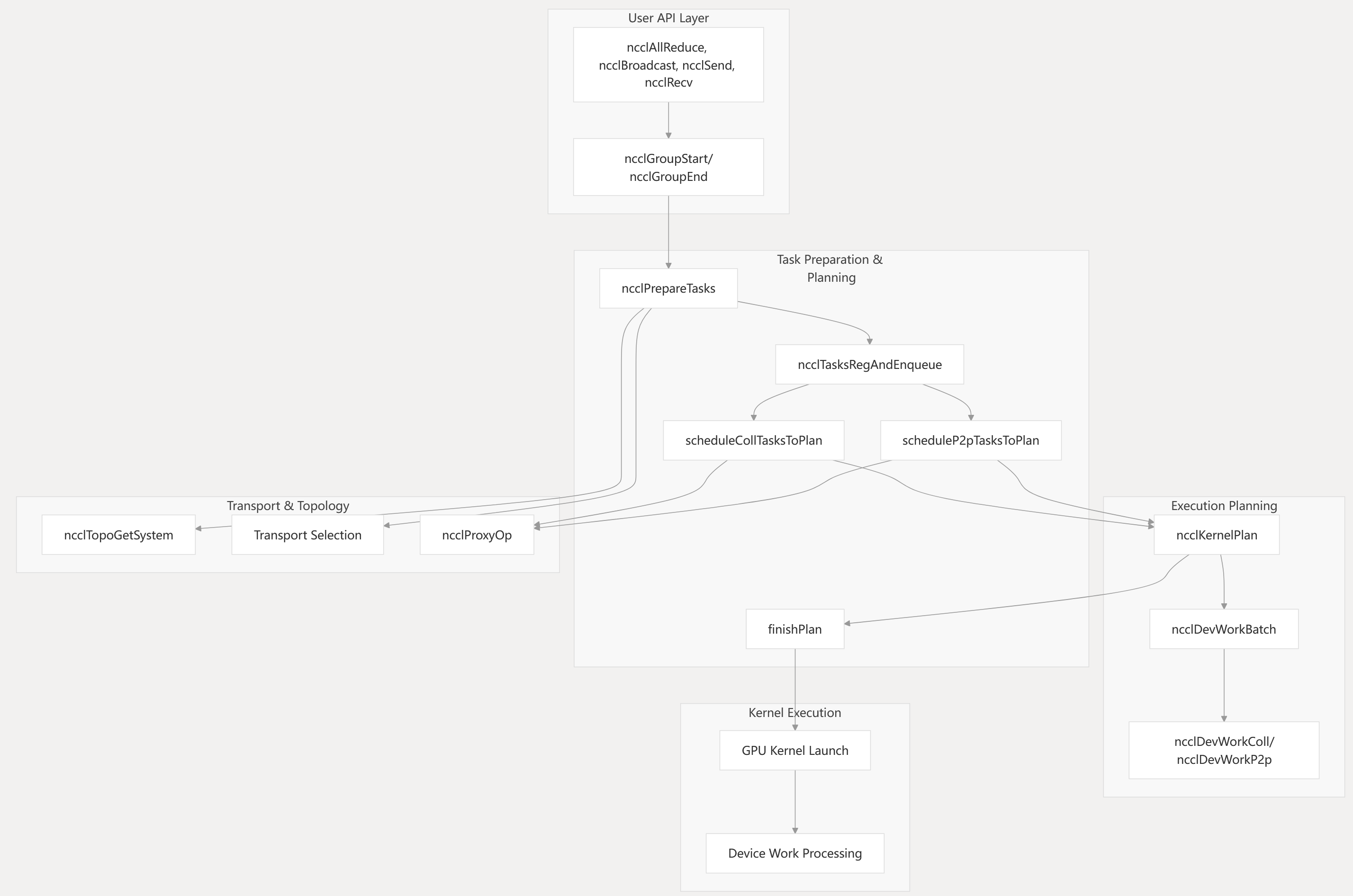
Core Architecture Flow Sources: src/enqueue.cc331-519
Task Preparation System
The task preparation system transforms user operations into internal task representations and determines optimal algorithms and protocols.

Task Collection and Sorting
Task Collection and Algorithm Selection Sources: src/enqueue.cc335-385
The ncclPrepareTasks function processes tasks in size-descending order from ncclTaskCollSorter, then bins them by (func, op, type) tuples. For each bin, it aggregates operations within 4X size of each other and computes optimal algorithms using getAlgoInfo. Tasks are then categorized by scheduling constraints (collnet vs nvls) for proper channel assignment.
Buffer Registration and Work Creation
The system registers buffers and creates device work structures for efficient GPU execution:
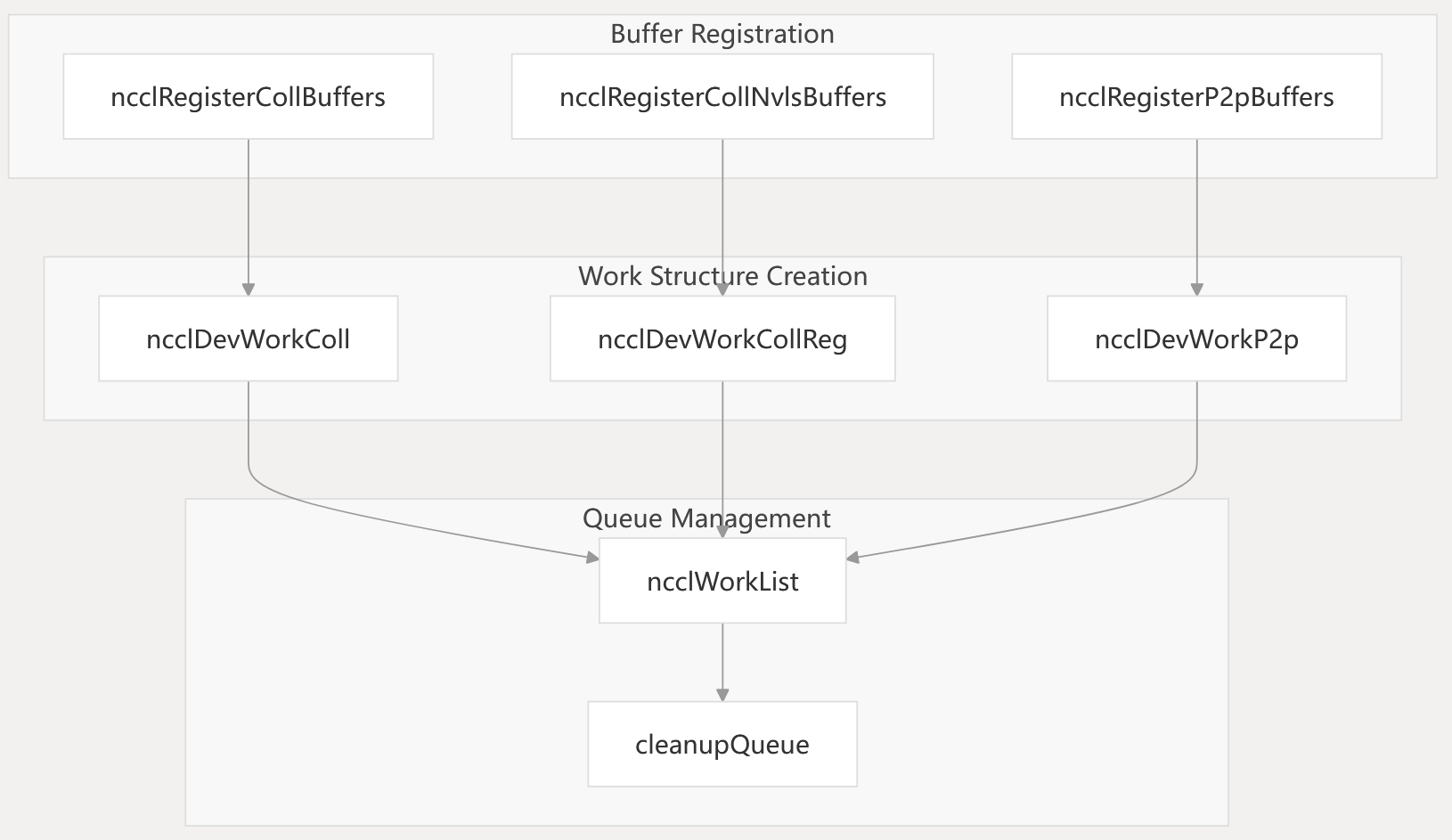
Buffer Registration and Work Creation Sources: src/enqueue.cc267-327
Kernel Planning System
The kernel planning system organizes tasks into executable batches and manages GPU kernel arguments.
Work Batch Organization

Work Batch Management Sources:
The addWorkBatchToPlan function manages work batch creation with strict constraints. New batches are created when work types or function IDs differ, or when size limits are exceeded. Extension batches handle non-contiguous work offsets, using a 63-item offset limit and bitset encoding for efficient device-side processing.
Plan Finalization
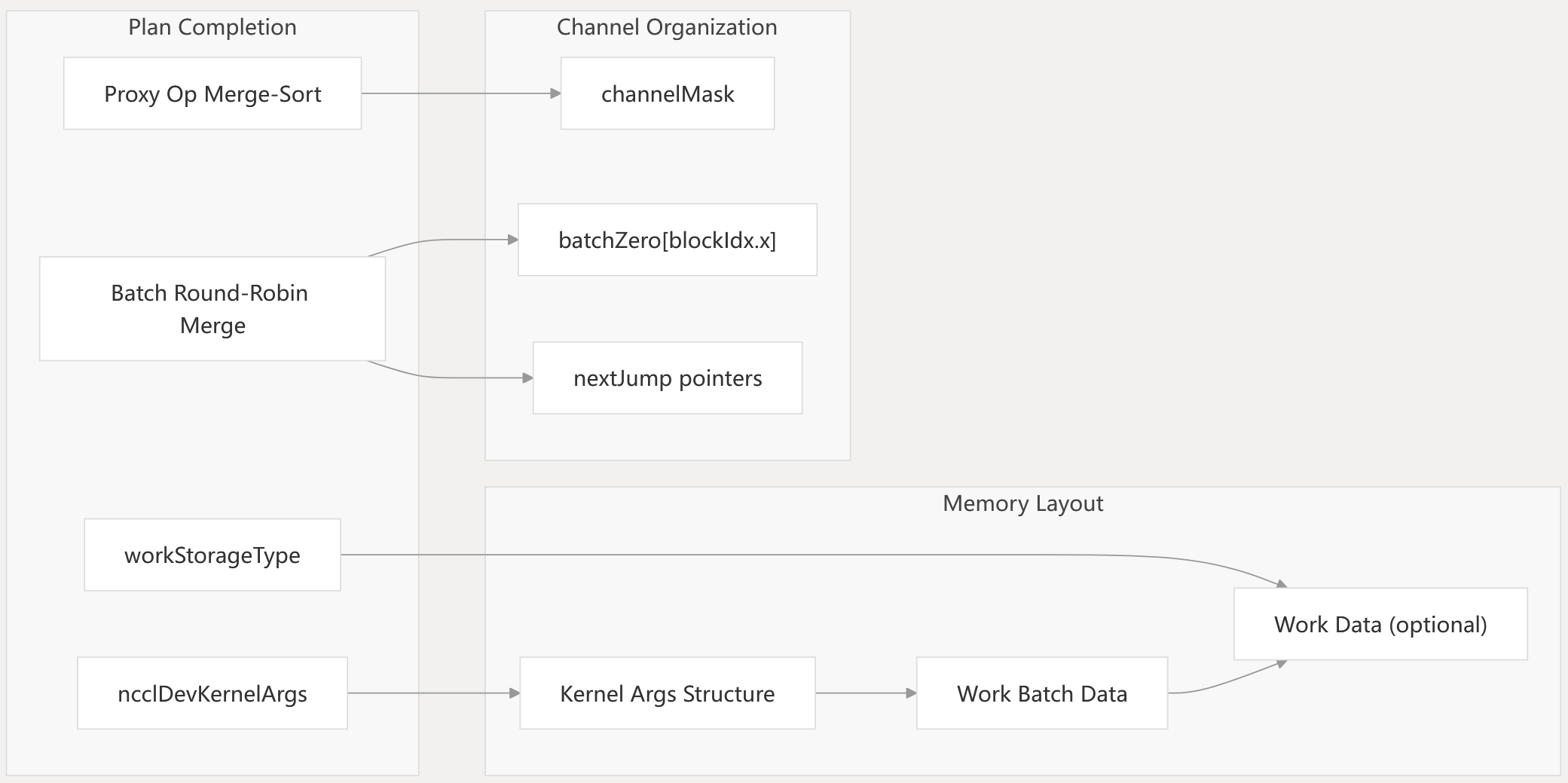
Plan Finalization Process Sources:
The finishPlan function finalizes kernel execution plans by organizing batches in round-robin order across channels and merge-sorting proxy operations by opCount. It determines optimal memory storage (in kernel args vs external) and sets up device-side navigation structures with nextJump pointers for batch traversal.
Scheduling Systems
NCCL implements separate scheduling systems for collective and point-to-point operations, each optimized for different communication patterns.
Collective Operation Scheduling

Collective Scheduling Logic Sources: src/enqueue.cc529-784
The scheduleCollTasksToPlan function implements sophisticated traffic distribution for collective operations. For CollNet operations, it uses calcCollChunking to determine optimal chunk sizes. For standard operations, it employs cell-based partitioning with minimum traffic thresholds (16KB) and distributes work across channels using count-based distribution (CBD) with countLo, countMid, and countHi values.
Point-to-Point Operation Scheduling
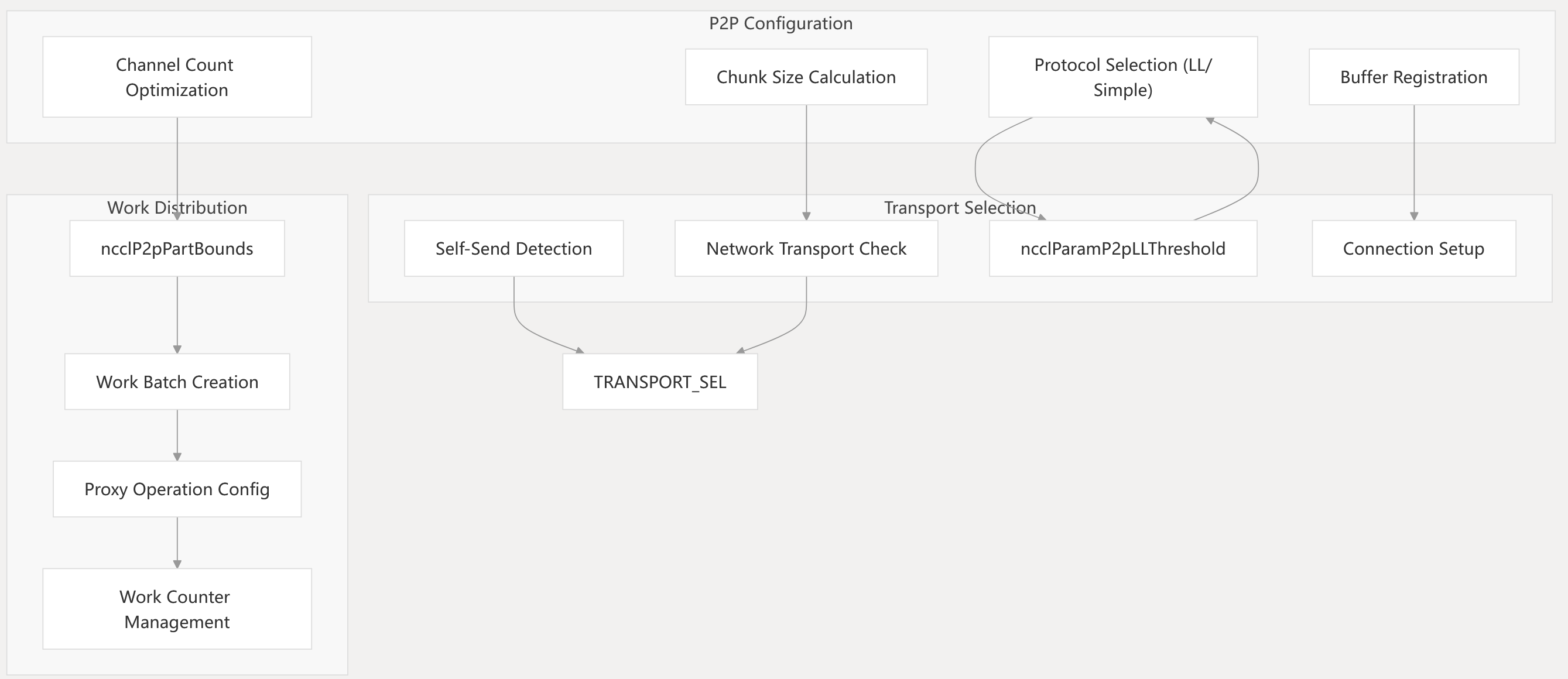
Point-to-Point Scheduling Sources: src/enqueue.cc793-1016
The addP2pToPlan function handles P2P operation scheduling with protocol selection based on size thresholds and transport capabilities. It optimizes chunk sizes for network operations, manages buffer registration for both network and IPC transports, and distributes work across multiple channels using ncclP2pPartBounds for optimal bandwidth utilization.
Transport Integration
The core architecture integrates with multiple transport layers through a unified interface system.
Transport Selection and Configuration
![]()
Transport System Integration Sources: src/transport/net.cc154-268
src/transport/coll_net.cc141-209
Memory and Resource Management
The architecture implements sophisticated memory management for optimal GPU communication performance.
Buffer Management Strategy
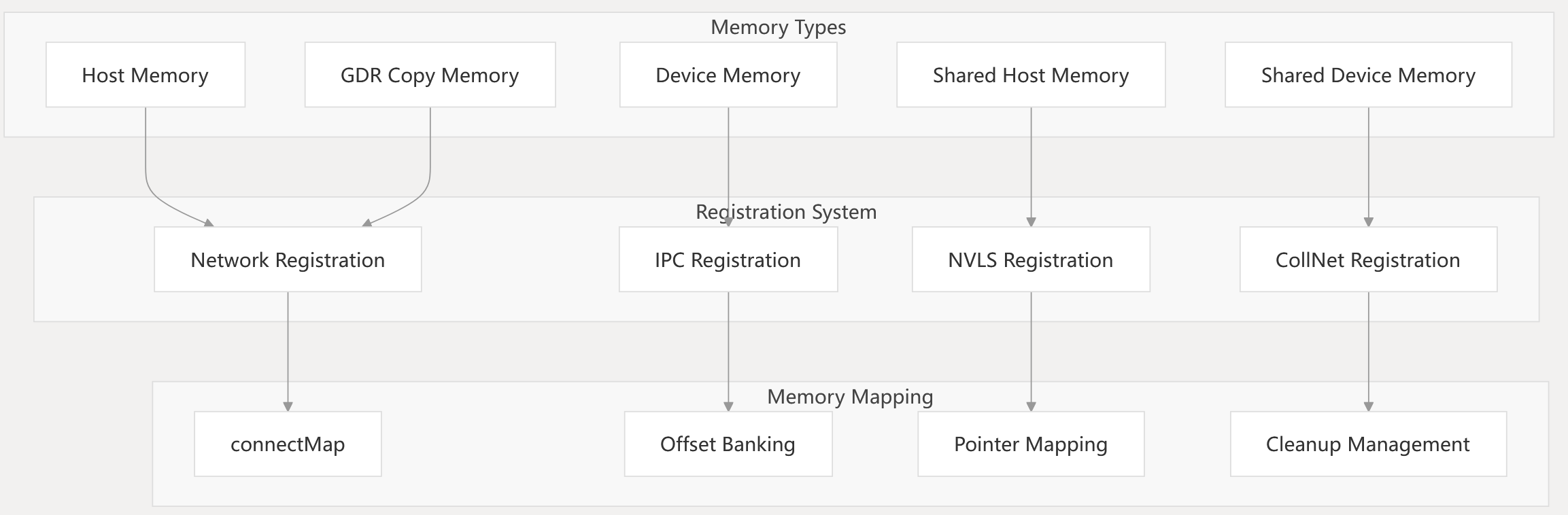
Memory Management Architecture Sources: src/transport/net.cc63-91
The system uses a sophisticated memory mapping strategy with connectMap structures that bank different memory types using offset encoding. The upper 3 bits of offsets indicate memory bank types, enabling efficient pointer resolution across different memory spaces while supporting both same-process and cross-process scenarios.
This architecture provides the foundation for NCCL’s high-performance GPU communication by efficiently orchestrating task preparation, transport selection, and execution planning while maintaining optimal memory utilization patterns.