-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12 + 扩展其他算法,这里不整理
-
https://openmlsys.github.io/chapter_preface/index.html 注重应用在联邦学习、推荐系统、强化学习、可解释AI和机器人中的相关核心系统进行讲解。
加州大学伯克利分校的AI Systems(人工智能系统)课程较为知名。这门课描述了机器学习系统的不同研究方向,内容以研读论文为主。可惜的是,许多论文已经过时。这门课缺乏对于知识的整体梳理,未能形成完整的知识体系架构。 华盛顿大学曾短期开过Deep Learning Systems(深度学习系统)课程,这门课程讲述了机器学习程序的编译过程。而由于这门课程以讲述Apache TVM深度学习编译器为主要目的,对于机器学习系统缺乏完整的教学。 斯坦福大学的课程Machine Learning Systems Design(机器学习系统设计)因为课程设计人的研究领域以数据库为主,因此该课程专注于数据清洗、数据管理、数据标注等主题。 微软亚洲研究院的AI Systems课程。这门课程讲述了机器学习系统背后的设计理念。这门课对于机器学习系统核心设计理念讲解得很浅
上述的课程共同问题是:其课程结构都以研读相关论文为主,因此教授的内容都是高深和零散的,而不是通俗易懂,知识脉络清晰的教科书,这给学习机器学习系统造成了极大的困难。
2. 导论
本章将会介绍机器学习应用,梳理出机器学习系统的设计目标,总结出机器学习系统的基本组成原理,让读者对机器学习系统有自顶而下的全面了解。
2.1. 机器学习应用
通俗来讲,机器学习是指从数据中学习出有用知识的技术。以学习模式分类,机器学习可以分为监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)和强化学习(Reinforcement Learning)等。
- 监督学习是已知输入和输出的对应关系下的机器学习场景。比如给定输入图像和它对应的离散标签。
- 无监督学习是只有输入数据但不知道输出标签下的机器学习场景。比如给定一堆猫和狗的图像,自主学会猫和狗的分类,这种无监督分类也称为聚类(Clustering)。
- 强化学习则是给定一个学习环境和任务目标,算法自主地去不断改进自己以实现任务目标。比如 AlphaGo围棋就是用强化学习实现的,给定的环境是围棋的规则,而目标则是胜利得分。
不同的机器学习应用底层会应用不同的机器学习算法,如支持向量机(Support Vector Machine,SVM)、逻辑回归(Logistic Regression)、朴素贝叶斯(Naive Bayes)算法等。近年来,得益于海量数据的普及,神经网络(Neural Networks)算法的进步和硬件加速器的成熟,深度学习(Deep Learning)开始蓬勃发展。
2.2. 机器学习框架的设计目标
为了支持在不同应用中高效开发机器学习算法,人们设计和实现了机器学习框架(如TensorFlow、PyTorch、MindSpore等)。广义来说,这些框架实现了以下共性的设计目标:
- 神经网络编程: 深度学习的巨大成功使得神经网络成为了许多机器学习应用的核心。根据应用的需求,人们需要定制不同的神经网络,如卷积神经网络(Convolutional Neural Networks)和自注意力神经网络(Self-Attention Neural Networks)等。这些神经网络需要一个共同的系统软件进行开发、训练和部署。
- 自动微分: 训练神经网络会具有模型参数。这些参数需要通过持续计算梯度(Gradients)迭代改进。梯度的计算往往需要结合训练数据、数据标注和损失函数(Loss Function)。考虑到大多数开发人员并不具备手工计算梯度的知识,机器学习框架需要根据开发人员给出的神经网络程序,全自动地计算梯度。这一过程被称之为自动微分。
- 数据管理和处理: 机器学习的核心是数据。这些数据包括训练、验证、测试数据集和模型参数。因此,需要系统本身支持数据读取、存储和预处理(例如数据增强和数据清洗)。
- 模型训练和部署: 为了让机器学习模型达到最佳的性能,需要使用优化方法(例如Mini-Batch SGD)来通过多步迭代反复计算梯度,这一过程称之为训练。训练完成后,需要将训练好的模型部署到推理设备。
- 硬件加速器: 神经网络的相关计算往往通过矩阵计算实现。这一类计算可以被硬件加速器(例如,通用图形处理器-GPU)加速。因此,机器学习系统需要高效利用多种硬件加速器。
- 分布式执行: 随着训练数据量和神经网络参数量的上升,机器学习系统的内存用量远远超过了单个机器可以提供的内存。因此,机器学习框架需要天然具备分布式执行的能力。
2.3. 机器学习框架的基本组成原理
一个完整的机器学习框架一般具有如图2.3.1 所示的基本架构。
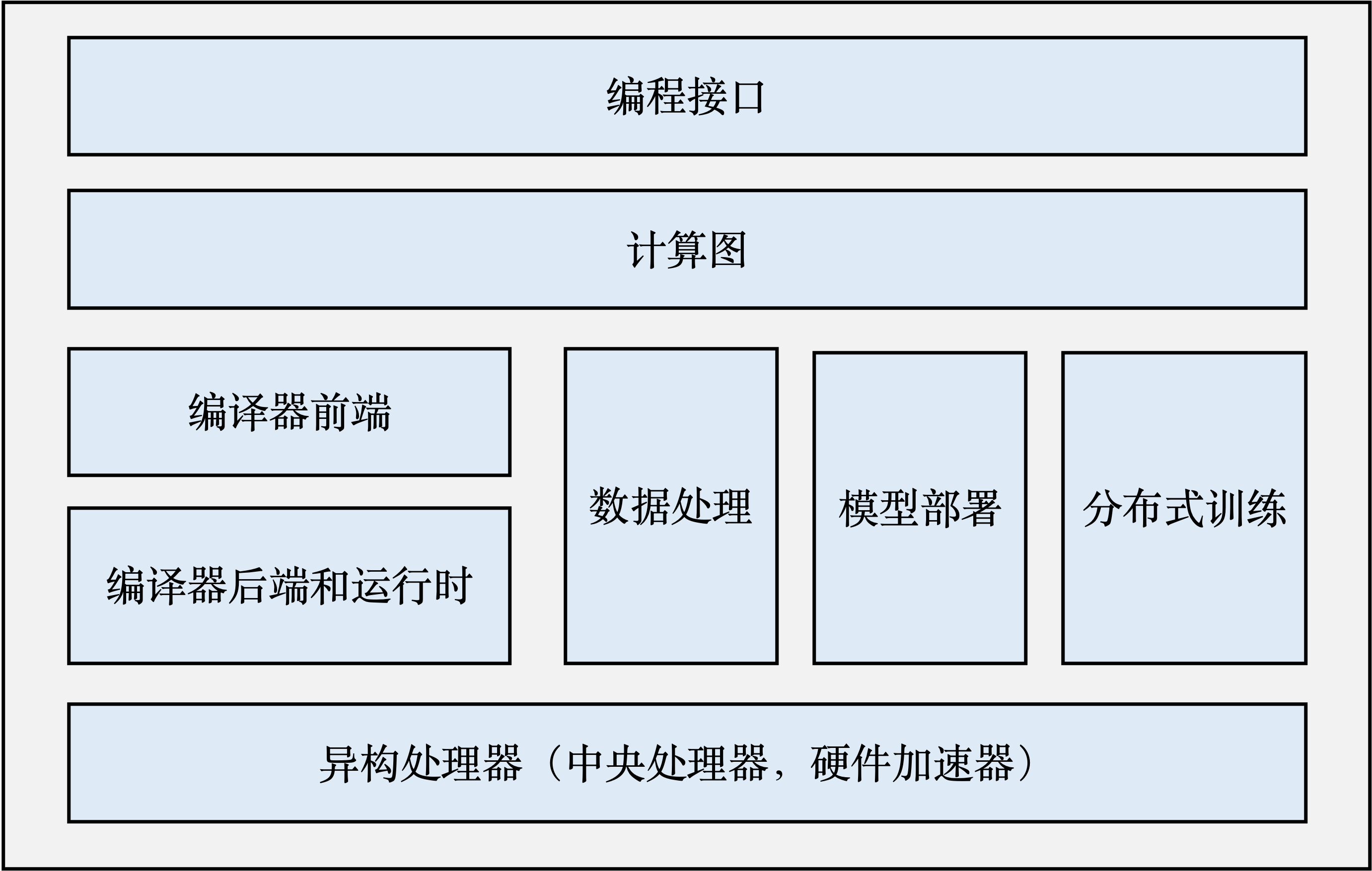
- 编程接口: 机器学习框架首先需要提供以高层次编程语言(如Python)为主的编程接口。同时,机器学习框架为了优化运行性能,需要支持以低层次编程语言(如C和C++)为主的系统实现,从而实现操作系统(如线程管理和网络通讯等)和各类型硬件加速器的高效使用。
- 计算图: 利用不同编程接口实现的机器学习程序需要共享一个运行后端。实现这一后端的关键技术是计算图技术。计算图定义了用户的机器学习程序,其包含大量表达计算操作的算子节点(Operator Node),以及表达算子之间计算依赖的边(Edge)。
- 编译器前端: 机器学习框架往往具有AI编译器来构建计算图,并将计算图转换为硬件可以执行的程序。这个编译器首先会利用一系列编译器前端技术实现对程序的分析和优化。编译器前端的关键功能包括实现中间表示、自动微分、类型推导和静态分析等。
- 编译器后端和运行时: 完成计算图的分析和优化后,机器学习框架进一步利用编译器后端和运行时实现针对不同底层硬件的优化。常见的优化技术包括分析硬件的L2/L3缓存大小和指令流水线长度,优化算子的选择或者调度顺序。
- 异构处理器: 机器学习应用的执行由中央处理器(Central Processing Unit,CPU)和硬件加速器(如英伟达GPU、华为Ascend和谷歌TPU)共同完成。其中,非矩阵操作(如复杂的数据预处理和计算图的调度执行)由中央处理器完成。矩阵操作和部分频繁使用的机器学习算子(如Transformer算子和Convolution算子)由硬件加速器完成。
- 数据处理: 机器学习应用需要对原始数据进行复杂预处理,同时也需要管理大量的训练数据集、验证数据集和测试数据集。这一系列以数据为核心的操作由数据处理模块(例如TensorFlow的tf.data和PyTorch的DataLoader)完成。
- 模型部署: 在完成模型训练后,机器学习框架下一个需要支持的关键功能是模型部署。为了确保模型可以在内存有限的硬件上执行,会使用模型转换、量化、蒸馏等模型压缩技术。同时,也需要实现针对推理硬件平台(例如英伟达Orin)的模型算子优化。最后,为了保证模型的安全(如拒绝未经授权的用户读取),还会对模型进行混淆设计。
- 分布式训练: 机器学习模型的训练往往需要分布式的计算节点并行完成。其中,常见的并行训练方法包括数据并行、模型并行、混合并行和流水线并行。这些并行训练方法通常由远端程序调用(Remote Procedure Call, RPC)、集合通信(Collective Communication)或者参数服务器(Parameter Server)实现。
3. 编程接口
现代机器学习框架包含大量的组件,辅助用户高效开发机器学习算法、处理数据、部署模型、性能调优和调用硬件加速器。在设计这些组件的应用编程接口(Application Programming Interface,API)时,一个核心的诉求是:如何平衡框架性能和易用性?为了达到最优的性能,开发者需要利用硬件亲和的编程语言如:C和C++来进行开发。这是因为C和C++可以帮助机器学习框架高效地调用硬件底层API,从而最大限度发挥硬件性能。同时,现代操作系统(如Linux和Windows)提供丰富的基于C和C++的API接口(如文件系统、网络编程、多线程管理等),通过直接调用操作系统API,可以降低框架运行的开销。
从易用性的角度分析,机器学习框架的使用者往往具有丰富的行业背景(如数据科学家、生物学家、化学家、物理学家等)。他们常用的编程语言是高层次脚本语言:Python、Matlab、R和Julia。相比于C和C++,这些语言在提供编程易用性的同时,丧失了C和C++对底层硬件和操作系统进行深度优化的能力。因此,机器学习框架的核心设计目标是:具有易用的编程接口来支持用户使用高层次语言,如Python实现机器学习算法;同时也要具备以C和C++为核心的低层次编程接口来帮助框架开发者用C和C++实现大量高性能组件,从而在硬件上高效执行。在本章中,将讲述如何达到这个设计目标。
本章的学习目标包括:
- 理解机器学习系统的工作流和以Python为核心的编程接口设计。
- 理解机器学习系统以神经网络模块为核心的接口设计原理和实现。
- 理解机器学习系统的底层C/C++执行算子的实现和与上层Python接口的调用实现。
- 了解机器学习系统编程接口的演进方向。
3.1. 机器学习系统编程模型的演进

随着机器学习系统的诞生,如何设计易用且高性能的API接口就一直成为了系统设计者首要解决的问题。在早期的机器学习框架中,人们选择用Lua(Torch)和Python(Theano)等高层次编程语言来编写机器学习程序。这些早期的机器学习框架提供了机器学习必须的模型定义,自动微分等功能,其适用于编写小型和科研为导向的机器学习应用。
深度神经网络在2011年来快速崛起,很快在各个AI应用领域(计算机视觉、语音识别、自然语言处理等)取得了突破性的成绩。训练深度神经网络需要消耗大量的算力,而以Lua和Python为主导开发的Torch和Theano无法发挥这些算力的最大性能。与此同时,计算加速卡(如英伟达GPU)的通用API接口(例如CUDA C)日趋成熟,且构建于CPU多核技术之上的多线程库(POSIX Threads)也被广大开发者所接受。因此,许多的机器学习用户希望基于C和C++来开发高性能的深度学习应用。这一类需求被Caffe等一系列以C和C++作为核心API的框架所满足。
然而,机器学习模型往往需要针对部署场景、数据类型、识别任务等需求进行深度定制,而这类定制任务需要被广大的AI应用领域开发者所实现。这类开发者的背景多样,往往不能熟练使用C和C++。因此Caffe这一类与C和C++深度绑定的编程框架,成为了制约框架快速推广的巨大瓶颈。
在2015年底,谷歌率先推出了TensorFlow。相比于传统的Torch,TensorFlow提出前后端分离相对独立的设计,利用高层次编程语言Python作为面向用户的主要前端语言,而利用C和C++实现高性能后端。大量基于Python的前端API确保了TensorFlow可以被大量的数据科学家和机器学习科学家接受,同时帮助TensorFlow能够快速融入Python为主导的大数据生态(大量的大数据开发库如Numpy、Pandas、SciPy、Matplotlib和PySpark)。同时,Python具有出色的和C/C++语言的互操作性,这种互操作性已经在多个Python库中得到验证。因此,TensorFlow兼有Python的灵活性和生态,同时也通过C/C++后端得以实现高性能。这种设计在日后崛起的PyTorch、MindSpore和PaddlePaddle等机器学习框架得到传承。
随着各国大型企业开源机器学习框架的出现,为了更高效地开发机器学习应用,基于开源机器学习框架为后端的高层次库Keras和TensorLayerX应运而生,它们提供Python API 可以快速导入已有的模型,这些高层次API进一步屏蔽了机器学习框架的实现细节,因此Keras和TensorLayerX可以运行在不同的机器学习框架之上。
随着深度神经网络的进一步发展,对于机器学习框架编程接口的挑战也日益增长。因此在2020年前后,新型的机器学习框架如MindSpore和JAX进一步出现。其中,MindSpore在继承了TensorFlow、PyTorch的Python和C/C++的混合接口的基础上,进一步拓展了机器学习编程模型从而可以高效支持多种AI后端芯片(如华为Ascend、英伟达GPU和ARM芯片),实现了机器学习应用在海量异构设备上的快速部署。
同时,超大型数据集和超大型深度神经网络崛起让分布式执行成为了机器学习编程框架的核心设计需求。为了实现分布式执行,TensorFlow和PyTorch的使用者需要花费大量代码来将数据集和神经网络分配到分布式节点上,而大量的AI开发人员并不具有分布式编程的能力。因此MindSpore进一步完善了机器学习框架的分布式编程模型的能力,从而让单节点的MindSpore程序可以无缝地运行在海量节点上。
3.2-3.4 省略
3.5. 机器学习框架的编程范式
3.5.1. 机器学习框架编程需求
机器学习的训练是其任务中最为关键的一步,训练依赖于优化器算法来描述。目前大部分机器学习任务都使用一阶优化器,因为一阶方法简单易用。随着机器学习的高速发展,软硬件也随之升级,越来越多的研究者开始探索收敛性能更好的高阶优化器。常见的二阶优化器如牛顿法、拟牛顿法、AdaHessians,均需要计算含有二阶导数信息的Hessian矩阵,Hessian矩阵的计算带来两方面的问题,一方面是计算量巨大如何才能高效计算,另一方面是高阶导数的编程表达。
同时,近年来,工业界发布了非常多的大模型,从2020年OpenAI GTP-3 175B参数开始,到2021年盘古大模型100B、鹏程盘古-200B、谷歌switch transformer 1.6T、智源悟道 1.75T参数,再到2022年百度ERNIE3.0 280M、Facebook NLLB-200 54B,越来越多的超大规模模型训练需求使得单纯的数据并行难以满足,而模型并行需要靠人工来模型切分耗时耗力,如何自动并行成为未来机器学习框架所面临的挑战。最后,构建机器学习模型本质上是数学模型的表示,如何简洁表示机器学习模型也成为机器学习框架编程范式的设计的重点。
为了解决机器学习框架在实际应用中的一些困难,研究人员发现函数式编程能很好地提供解决方案。在计算机科学中,函数式编程是一种编程范式,它将计算视为数学函数的求值,并避免状态变化和数据可变,这是一种更接近于数学思维的编程模式。神经网络由连接的节点组成,每个节点执行简单的数学运算。通过使用函数式编程语言,开发人员能够用一种更接近运算本身的语言来描述这些数学运算,使得程序的读取和维护更加容易。同时,函数式语言的函数都是相互隔离的,使得并发性和并行性更容易管理。
因此,机器学习框架使用函数式编程设计具有以下优势: - 支持高效的科学计算和机器学习场景。 - 易于开发并行。 - 简洁的代码表示能力。
3.5.2. 机器学习框架编程范式现状
本小节将从目前主流机器学习框架发展历程来看机器学习框架对函数式编程的支持现状。谷歌在2015年发布了TensorFlow1.0其代表的编程特点包括计算图(Computational Graphs)、会话(Session)、张量(Tensor)它是一种声明式编程风格。2017年Facebook发布了PyTorch其编程特点为即时执行,它是一种命令式编程风格。2018年谷歌发布了JAX它不是存粹为了机器学习而编写的框架,而是针对GPU和TPU做高性能数据并行计算的框架;与传统的机器学习框架相比其核心能力是神经网络计算和数值计算的融合,在接口上兼容了NumPy、Scipy等Python原生的数据科学接口,而且在此基础上扩展分布式、向量化、高阶求导、硬件加速,其编程风格是函数式,主要体现在无副作用、Lambda闭包等。2020年华为发布了MindSpore,其函数式可微分编程架构可以让用户聚焦机器学习模型数学的原生表达。2022年PyTorch推出functorch,受到谷歌JAX的极大启发,functorch是一个向PyTorch添加可组合函数转换的库,包括可组合的vmap(向量化)和autodiff转换,可与PyTorch模块和PyTorch autograd一起使用,并具有良好的渴望模式(Eager-Mode)性能,functorch可以说是弥补了PyTorch静态图的分布式并行需求。
从主流的机器学习框架发展历程来看,未来机器学习框架函数式编程风格将会日益得到应用,因为函数式编程能更直观地表达机器学习模型,同时对于自动微分、高阶求导、分布式实现也更加方便。另一方面,未来的机器学习框架在前端接口层次也趋向于分层解耦,其设计不直接为了机器学习场景,而是只提供高性能的科学计算和自动微分算子,更高层次的应用如机器学习模型开发则是通过封装这些高性能算子实现。
3.5.3. 函数式编程案例
在上一小节介绍了机器学习框架编程范式的现状,不管是JAX、MindSpore还是functorch都提到了函数式编程,其在科学计算、分布式方面有着独特的优势。然而在实际应用中纯函数式编程几乎没有能够成为主流开发范式,而现代编程语言几乎不约而同的选择了接纳函数式编程特性。以MindSpore为例,MindSpore选择将函数式和面向对象编程融合,兼顾用户习惯,提供易用性最好,编程体验最佳的混合编程范式。MindSpore采用混合编程范式道理也很简单,纯函数式会让学习曲线陡增,易用性变差;面向对象构造神经网络的编程范式深入人心。
3.6. 总结
- 现代机器学习系统需要兼有易用性和高性能,因此其一般选择Python作为前端编程语言,而使用C和C++作为后端编程语言。
- 一个机器学习框架需要对一个完整的机器学习应用工作流进行编程支持。这些编程支持一般通过提供高层次Python API来实现。
- 数据处理编程接口允许用户下载,导入和预处理数据集。
- 模型定义编程接口允许用户定义和导入机器学习模型。
- 损失函数接口允许用户定义损失函数来评估当前模型性能。同时,优化器接口允许用户定义和导入优化算法来基于损失函数计算梯度。
- 机器学习框架同时兼有高层次Python API来对训练过程,模型测试和调试进行支持。
- 复杂的深度神经网络可以通过叠加神经网络层来完成。
- 用户可以通过Python API定义神经网络层,并指定神经网络层之间的拓扑来定义深度神经网络。
- Python和C之间的互操作性一般通过CType等技术实现。
- 机器学习框架一般具有多种C和C++接口允许用户定义和注册C++实现的算子。这些算子使得用户可以开发高性能模型,数据处理函数,优化器等一系列框架拓展。
3.7. 扩展阅读
- Python和C/C++混合编程:Pybind11
4. 计算图
上一章节展示了如何高效编写机器学习程序,那么下一个问题就是:机器学习系统如何高效地在硬件上执行这些程序呢?这一核心问题又能被进一步拆解为:如何对机器学习程序描述的模型调度执行?如何使得模型调度执行更加高效?如何自动计算更新模型所需的梯度?解决这些问题的关键是计算图(Computational Graph)技术。
本章的学习目标包括:
- 掌握计算图的基本构成。
- 掌握计算图静态生成和动态生成方法。
- 掌握计算图的常用执行方法。
4.1. 计算图的设计背景和作用
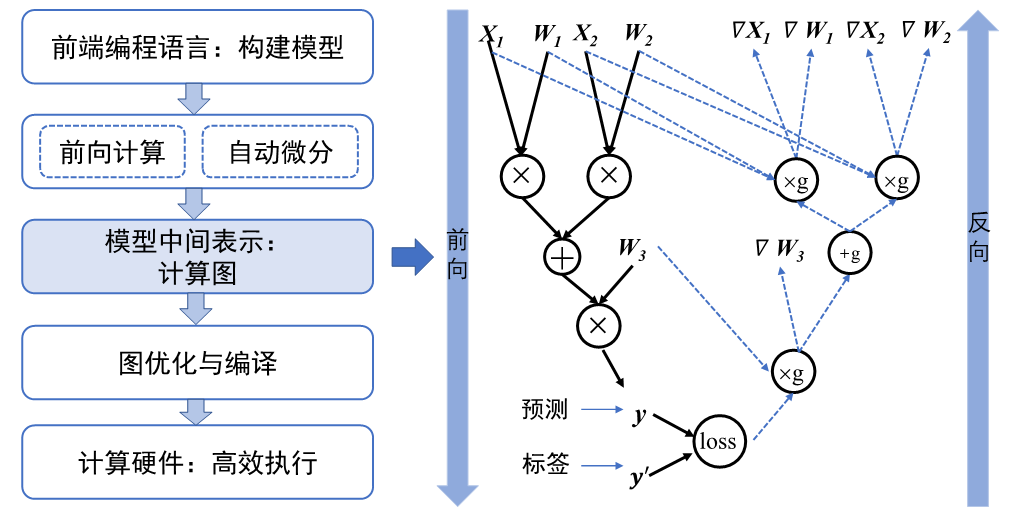
早期机器学习框架主要针对全连接和卷积神经网络设计,这些神经网络的拓扑结构简单,神经网络层之间通过串行连接。因此,它们的拓扑结构可以用简易的配置文件表达(例如Caffe基于Protocol Buffer格式的模型定义)。
现代机器学习模型的拓扑结构日益复杂,显著的例子包括混合专家模型、生成对抗网络、注意力模型等。复杂的模型结构(例如带有分支的循环结构等)需要机器学习框架能够对模型算子的执行依赖关系、梯度计算以及训练参数进行快速高效的分析,便于优化模型结构、制定调度执行策略以及实现自动化梯度计算,从而提高机器学习框架训练复杂模型的效率。因此,机器学习系统设计者需要一个通用的数据结构来理解、表达和执行机器学习模型。为了应对这个需求,如 图4.1.1所示基于计算图的机器学习框架应运而生,框架延续前端语言与后端语言分离的设计。从高层次来看,计算图实现了以下关键功能:
-
统一的计算过程表达。 在编写机器学习模型程序的过程中,用户希望使用高层次编程语言(如Python、Julia和C++)。然而,硬件加速器等设备往往只提供了C和C++编程接口,因此机器学习系统的实现通常需要基于C和C++。用不同的高层次语言编写的程序因此需要被表达为一个统一的数据结构,从而被底层共享的C和C++系统模块执行。这个数据结构(即计算图)可以表述用户的输入数据、模型中的计算逻辑(通常称为算子)以及算子之间的执行顺序。
-
自动化计算梯度。 用户的模型训练程序接收训练数据集的数据样本,通过神经网络前向计算,最终计算出损失值。根据损失值,机器学习系统为每个模型参数计算出梯度来更新模型参数。考虑到用户可以写出任意的模型拓扑和损失值计算方法,计算梯度的方法必须通用并且能实现自动运行。计算图可以辅助机器学习系统快速分析参数之间的梯度传递关系,实现自动化计算梯度的目标。
-
分析模型变量生命周期。 在用户训练模型的过程中,系统会通过计算产生临时的中间变量,如前向计算中的激活值和反向计算中的梯度。前向计算的中间变量可能与梯度共同参与到模型的参数更新过程中。通过计算图,系统可以准确分析出中间变量的生命周期(一个中间变量生成以及销毁时机),从而帮助框架优化内存管理。
-
优化程序执行。 用户给定的模型程序具备不同的网络拓扑结构。机器学习框架利用计算图来分析模型结构和算子执行依赖关系,并自动寻找算子并行计算的策略,从而提高模型的执行效率。
4.2. 计算图的基本构成
计算图由基本数据结构张量(Tensor)和基本运算单元算子构成。在计算图中通常使用节点来表示算子,节点间的有向边(Directed Edge)来表示张量状态,同时也描述了计算间的依赖关系。
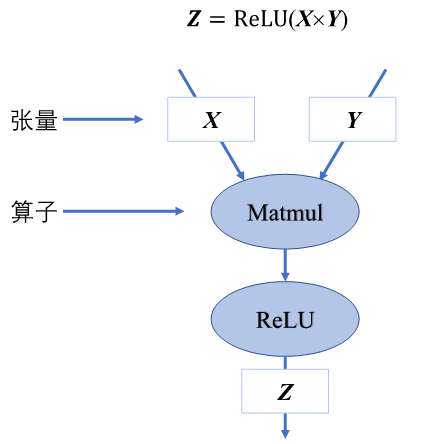
4.2.1. 张量和算子
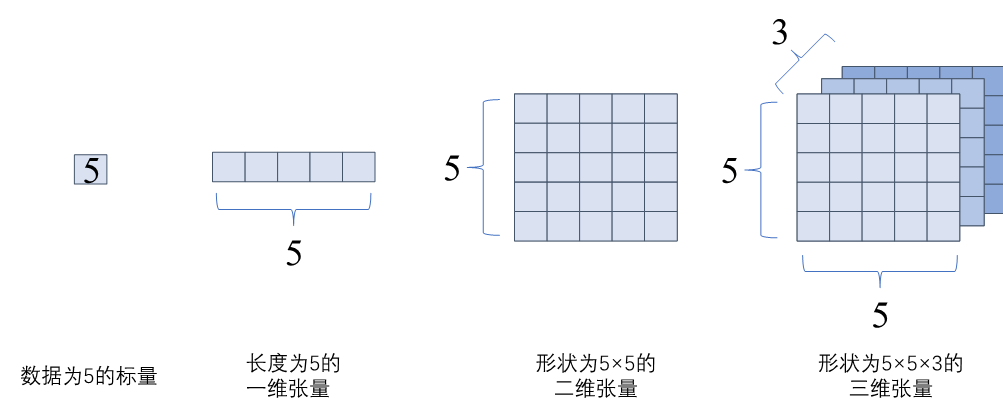
在数学中定义张量是基于标量与向量的推广。在机器学习领域内将多维数据称为张量,使用秩来表示张量的轴数或维度。如 图4.2.2所示,标量为零秩张量,包含单个数值,没有轴;向量为一秩张量,拥有一个轴;拥有RGB三个通道的彩色图像即为三秩张量,包含三个轴。
在机器学习框架中张量不仅存储数据,还需要存储张量的数据类型、数据形状、秩以及梯度传递状态等多个属性,如 表4.2.1所示,列举了主要的属性和功能。
表4.2.1 张量属性
| 张量属性 | 功能 |
|---|---|
| 形状(shape) | 存储张量的每个维度的长度,如[3,3,3] |
| 秩或维数(dim) | 表示张量的轴数或者维数,标量为0,向量为1。 |
| 数据类型(dtype) | 表示存储的数 据类型,如bool、uint8、int16、float32、float64等 |
| 存储位置(device) | 创建张量时可以指定存储的设备位置,如CPU、GPU等 |
| 名字(name) | 张量的标识符 |
以图像数据为例来具体说明张量属性的作用。当机器学习框架读取一张高为96像素、宽为96像素的RGB三通道图像,并将图像数据转换为张量存储时。该张量的形状属性则为[96,96,3]分别代表高、宽、通道的数量,秩即为3。原始RGB图像每个像素上的数据以0-255的无符号整数来表示色彩,因此图像张量存储时会将数据类型属性设置为uint8格式。将图像数据传输给卷积网络模型进行网络训练前,会对图像数据进行归一化处理,此时数据类型属性会重新设置为float32格式,因为通常机器学习框架在训练模型时默认采用float32格式。
机器学习框架在训练时需要确定在CPU、GPU或其他硬件上执行计算,数据和权重参数也应当存放在对应的硬件内存中才能正确被调用,张量存储位置属性则用来指明存储的设备位置。存储位置属性通常由机器学习框架根据硬件环境自动赋予张量。在模型训练过程中,张量数据的存储状态可以分为可变和不可变两种,可变张量存储神经网络模型权重参数,根据梯度信息更新自身数据,如参与卷积运算的卷积核张量;不可变张量用于用户初始化的数据或者输入模型的数据,如上文提到的图像数据张量。
那么在机器学习场景下的张量一般长什么样子呢?上文提到的图像数据张量以及卷积核张量,形状一般是“整齐”的。即每个轴上的具有相同的元素个数,就像一个“矩形”或者“立方体”。在特定的环境中,也会使用特殊类型的张量,比如不规则张量和稀疏张量。如 图4.2.3中所示,不规则张量在某个轴上可能具有不同的元素个数,它们支持存储和处理包含非均匀形状的数据,如在自然语言处理领域中不同长度文本的信息;稀疏张量则通常应用于图数据与图神经网络中,采用特殊的存储格式如坐标表格式(Coordinate List,COO),可以高效存储稀疏数据节省存储空间。

算子是构成神经网络的基本计算单元,对张量数据进行加工处理,实现了多种机器学习中常用的计算逻辑,包括数据转换、条件控制、数学运算等。为了便于梳理算子类别,按照功能将算子分类为张量操作算子、神经网络算子、数据流算子和控制流算子等。
-
张量操作算子:包括张量的结构操作和数学运算。张量的结构操作通常用于张量的形状、维度调整以及张量合并等,比如在卷积神经网络中可以选择图像数据以通道在前或者通道在后的格式来进行计算,调整图像张量的通道顺序就需要结构操作。张量相关的数学运算算子,例如矩阵乘法、计算范数、行列式和特征值计算,在机器学习模型的梯度计算中经常被使用到。
-
神经网络算子:包括特征提取、激活函数、损失函数、优化算法等,是构建神经网络模型频繁使用的核心算子。常见的卷积操作就是特征提取算子,用来提取比原输入更具代表性的特征张量。激活函数能够增加神经网络模型非线性能力,帮助模型表达更加复杂的数据特征关系。损失函数和优化算法则与模型参数训练更新息息相关。
-
数据流算子:包含数据的预处理与数据载入相关算子,数据预处理算子主要是针对图像数据和文本数据的裁剪填充、归一化、数据增强等操作。数据载入算子通常会对数据集进行随机乱序(Shuffle)、分批次载入(Batch)以及预载入(Pre-fetch)等操作。数据流操作主要功能是对原始数据进行处理后,转换为机器学习框架本身支持的数据格式,并且按照迭代次数输入给网络进行训练或者推理,提升数据载入速度,减少内存占用空间,降低网络训练数据等待时间。
-
控制流算子:可以控制计算图中的数据流向,当表示灵活复杂的模型时需要控制流。使用频率比较高的控制流算子有条件运算符和循环运算符。控制流操作一般分为两类,机器学习框架本身提供的控制流操作符和前端语言控制流操作符。控制流操作不仅会影响神经网络模型前向运算的数据流向,也会影响反向梯度运算的数据流向。
4.2.2. 计算依赖
在计算图中,算子之间存在依赖关系,而这种依赖关系影响了算子的执行顺序与并行情况。机器学习算法模型中,计算图是一个有向无环图,即在计算图中造成循环依赖(Circular Dependency)的数据流向是不被允许的。循环依赖会形成计算逻辑上的死循环,模型的训练程序将无法正常结束,而流动在循环依赖闭环上的数据将会趋向于无穷大或者零成为无效数据。为了分析计算执行顺序和模型拓扑设计思路,下面将对计算图中的计算节点依赖关系进行讲解。
如 图4.2.4中所示,在此计算图中,若将Matmul1算子移除则该节点无输出,导致后续的激活函数无法得到输入,从而计算图中的数据流动中断,这表明计算图中的算子间具有依赖关系并且存在传递性。

将依赖关系进行区分如下:
-
直接依赖:节点ReLU1直接依赖于节点Matmul1,即如果节点ReLU1要执行运算,必须接受直接来自节点Matmul1的输出数据;
-
间接依赖:节点Add间接依赖于节点Matmul1,即节点Matmul1的数据并未直接传输给节点Add,而是经过了某个或者某些中间节点进行处理后再传输给节点Add,而这些中间节点可能是节点Add的直接依赖节点,也可能是间接依赖节点;
-
相互独立:在计算图中节点Matmul1与节点Matmul2之间并无数据输入输出依赖关系,所以这两个节点间相互独立。
掌握依赖关系后,分析 图4.2.5可以得出节点Add间接依赖于节点Matmul,而节点Matmul直接依赖于节点Add,此时两个节点互相等待对方计算完成输出数据,将无法执行计算任务。若我们手动同时给两个节点赋予输入,计算将持续不间断进行,模型训练将无法停止造成死循环。循环依赖产生正反馈数据流,被传递的数值可能在正方向上无限放大,导致数值上溢,或者负方向上放大导致数值下溢,也可能导致数值无限逼近于0,这些情况都会致使模型训练无法得到预期结果。在构建深度学习模型时,应避免算子间产生循环依赖。

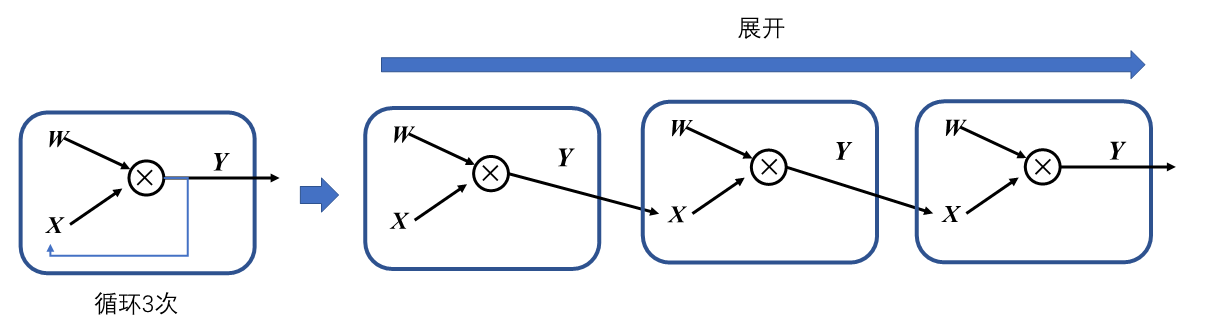
在机器学习框架中,表示循环关系(Loop Iteration)通常是以展开机制(Unrolling)来实现。循环三次的计算图进行展开如 图4.2.6,循环体的计算子图按照迭代次数进行复制3次,将代表相邻迭代轮次的子图进行串联,相邻迭代轮次的计算子图之间是直接依赖关系。在计算图中,每一个张量和运算符都具有独特的标识符,即使是相同的操作运算,在参与循环不同迭代中的计算任务时具有不同的标识符。区分循环关系和循环依赖的关键在于,具有两个独特标识符的计算节点之间是否存在相互依赖关系。循环关系在展开复制计算子图的时候会给复制的所有张量和运算符赋予新的标识符,区分被复制的原始子图,以避免形成循环依赖。
5. 第二部分:进阶篇
下面本书将重点讲解 AI 编译器的基本构成,以及 AI 编译器前端、后端和运行时中的关键技术。本书也将对于硬件加速器、数据处理、模型部署和分布式训练分别进行深入解读,从而为开发者提供从 0 到 1 构建机器学习框架所需的核心知识和实践经验。
6. AI编译器和前端技术
编译器作为计算机系统的核心组件,在机器学习框架设计中也扮演着重要的角色,并衍生出了一个专门的编译器种类:AI编译器。AI编译器既要对上承接模型算法的变化,满足算法开发者不断探索的研究诉求,又要对下在最终的二进制输出上满足多样性硬件的诉求,满足不同部署环境的资源要求。既要满足框架的通用普适性,又要满足易用性的灵活性要求,还要满足性能的不断优化诉求。AI编译器保证了机器学习算法的便捷表达和高效执行,日渐成为了机器学习框架设计的重要一环。
本章将先从AI编译器的整体框架入手, 介绍AI编译器的基础结构。接下来,本章会详细讨论编译器前端的设计,并将重点放在中间表示以及自动微分两个部分。有关AI编译器后端的详细知识, 将会在后续的第五章进行讨论。
本章的学习目标包括:
-
理解AI编译器的基本设计原理
-
理解中间表示的基础概念,特点和实现方法
-
理解自动微分的基础概念,特点和实现方法
-
了解类型系统和静态推导的基本原理
-
了解编译器优化的主要手段和常见优化方法
7. 编译器后端和运行时
在上一章节,详细讲述了一个AI编译器前端的主要功能,重点介绍了中间表示以及自动微分。在得到中间表示后,如何充分利用硬件资源高效地执行,是编译器后端和运行时要解决的问题。
在本章节中, 将会介绍AI编译器后端的一些基本概念,详细描述后端的计算图优化、算子选择等流程。通过对编译器前端提供的中间表示进行优化,充分发挥硬件能力,从而提高程序的执行效率。在此基础上,介绍运行时是如何对计算任务进行内存分配以及高效地调度执行。
本章的学习目标包括:
-
了解编译器后端和运行时的作用
-
掌握计算图优化的常用方法
-
掌握算子选择的常用方法
-
掌握内存分配的常用方法
-
掌握计算图调度和执行的常用方法
-
了解目前算子编译器的基本特点以及其尚未收敛的几个问题
11. 分布式训练
随着机器学习的进一步发展,科学家们设计出更大型、更多功能的机器学习模型(例如GPT-3)。这种模型含有大量参数和复杂的结构。他们因此需要海量的计算和内存资源。单个机器上有限的资源无法满足训练大型机器学习模型的需求。因此,需要设计分布式训练系统,从而将一个机器学习模型任务拆分成多个子任务,并将子任务分发给多个计算节点,解决资源瓶颈。
本章引入分布式机器学习系统的相关概念、设计挑战、系统实现和实例研究。首先讨论分布式训练系统的定义、设计动机和好处。然后进一步讨论常见的分布式训练方法:数据并行、模型并行和流水线并行。在实际中,这些分布式训练方法会被集合通信(Collective Communication)或者参数服务器(Parameter Servers)实现。不同的系统实现具有各自的优势和劣势。
本章的学习目标包括:
- 掌握分布式训练相关系统组件的设计。
- 掌握常见的分布式训练方法:数据并行、模型并行和流水线并行。
- 掌握常见的分布式训练框架实现:集合通信和参数服务器。
11.1. 系统概述
11.1.1. 设计动机
分布式训练系统主要为了解决单节点的算力和内存不足的问题。
11.1.1.1. 算力不足
单处理器的算力不足是促使人们设计分布式训练系统的一个主要原因。一个处理器的算力可以用每秒钟浮点数操作(Floating Point Operations Per Second,FLOPS)来衡量。图11.1.1分析了机器学习模型对于算力的需求以及同期处理器所提供算力在过去数年中变化。其中,用千万亿运算次数/秒—天(Petaflop/s—day )这一指标来衡量算力。这个指标等价于每秒
次神经网络操作执行一天,也就是总共大约次计算操作。如图所示,根据摩尔定律(Moore’s Law),中央处理器的算力每18个月增长2倍。虽然计算加速卡(如GPU和TPU)针对机器学习计算提供了大量的算力。这些加速卡的发展最终也受限于摩尔定律,增长速度停留在每18个月2倍。而与此同时,机器学习模型正在快速发展。短短数年,机器学习模型从仅能识别有限物体的AlexNet,一路发展到在复杂任务中打败人类的AlphaStar。这期间,模型对于算力需求每18个月增长了56倍。解决处理器性能和算力需求之间鸿沟的关键就在于利用分布式计算。通过大型数据中心和云计算设施,可以快速获取大量的处理器。通过分布式训练系统有效管理这些处理器,可以实现算力的快速增长,从而持续满足模型的需求。
11.1.1.2. 内存不足
训练机器学习模型需要大量内存。假设一个大型神经网络模型具有1000亿的参数,每个参数都由一个32位浮点数(4个字节)表达,存储模型参数就需要400GB的内存。在实际中,我们需要更多内存来存储激活值和梯度。假设激活值和梯度也用32位浮点数表达,那么其各自至少需要400GB内存,总的内存需求就会超过1200GB(即1.2TB)。而如今的硬件加速卡(如NVIDIA A100)仅能提供最高80GB的内存。单卡内存空间的增长受到硬件规格、散热和成本等诸多因素的影响,难以进一步快速增长。因此,我们需要分布式训练系统来同时使用数百个训练加速卡,从而为千亿级别的模型提供所需的TB级别的内存。
11.1.2. 系统架构
为了方便获得大量用于分布式训练的服务器,人们往往依靠云计算数据中心。一个数据中心管理着数百个集群,每个集群可能有几百到数千个服务器。通过申请其中的数十台服务器,这些服务器进一步通过分布式训练系统进行管理,并行完成机器学习模型的训练任务。
为了确保分布式训练系统的高效运行,需要首先估计系统计算任务的计算和内存用量。假如某个任务成为了瓶颈,系统会切分输入数据,从而将一个任务拆分成多个子任务。子任务进一步分发给多个计算节点并行完成。图11.1.2描述了这一过程。一个模型训练任务(Model Training Job)往往会有一组数据(如训练样本)或者任务(如算子)作为输入,利用一个计算节点(如GPU)生成一组输出(如梯度)。分布式执行一般具有三个步骤:第一步将输入进行切分;第二步将每个输入部分会分发给不同的计算节点,实现并行计算;第三步将每个计算节点的输出进行合并,最终得到和单节点等价的计算结果。这种首先切分,然后并行,最后合并的模式,本质上实现了分而治之(Divide-and-Conquer)的方法:由于每个计算节点只需要负责更小的子任务,因此其可以更快速地完成计算,最终实现对整个计算过程的加速。
11.1.3. 用户益处
通过使用分布式训练系统可以获得以下几个优点:
-
提升系统性能:使用分布式训练,往往可以带来训练性能的巨大提升。一个分布式训练系统一般用“到达目标精度所需的时间”(Time-to-Accuracy)这个指标来衡量系统性能。这个指标由两个参数决定: (1)完成一个数据周期的时间,和(2)完成一个数据周期后模型所提升的精度。通过持续增加并行处理节点,可以将数据周期的完成时间不断变短,最终显著减少到达目标精度所需的时间。
-
减少成本,体现经济性:使用分布式训练也可以进一步减少模型训练的成本。受限于单节点散热的上限,单节点的算力越高,其所需的散热硬件成本也更高。因此,在提供同等算力的条件下,组合多个计算节点是一个更加经济高效的方式。这促使云服务商(如亚马逊和微软等)更加注重给用户提供成本高效的分布式机器学习系统。
-
防范硬件故障:分布式训练系统同时能有效提升防范硬件故障的能力。机器学习训练集群往往由商用硬件(Commodity Hardware)组成,这类硬件(例如磁盘和网卡)运行一定时间就会产生故障。而仅使用单个机器进行训练,一个机器的故障就会造成模型训练任务的失败。通过将该模型训练任务交由多个机器共同完成,即使一个机器出故障,也可以通过将该机器上相应的计算子任务转移给其余机器,继续完成训练,从而避免训练任务的失败。
11.2. 实现方法
下面讨论分布式训练系统实现的常用并行方法。首先给出并行方法的设计目标以及分类。然后详细描述各个并行方法。