深度学习中的分布式训练算法
https://zhuanlan.zhihu.com/p/2043936367
分布式计算
第一个公式:深度学习训练耗时
公式为(训练耗时 = 训练数据规模\times 单步计算量\div 计算速率)。
- 从模型角度看,训练数据规模和单步计算量是与模型相关的参数。一旦模型结构确定,比如选定了某类神经网络架构,要处理的数据量以及每一步训练需要进行的计算操作(像矩阵乘法等)就相对固定了。
- 而计算速率是可以改变的因素,它会直接影响训练所花费的时间。如果计算速率提高,在训练数据规模和单步计算量不变的情况下,训练耗时就会减少;反之则增加。
第二个公式:计算速率
公式为(计算速率 = 单设备计算速率\times 设备数\times 并行效率)。
-
单设备计算速率受摩尔定律(Moore 定律,即集成电路上可容纳的晶体管数目约每隔两年便会增加一倍,性能也随之提升)影响,但随着技术发展,单设备性能提升逐渐遇到瓶颈,所以单设备计算速率的提升相对有限。
-
设备数和并行效率是可变因素,也是工作重点。增加设备数,能让更多设备同时参与计算;提升并行效率,可使多设备协同计算时的资源利用更高效,这两者都能有效提高整体计算速率,进而减少深度学习训练耗时。
-
分布式算法:“Distributed algorithms are algorithms designed to run on multiple processors, without tight centralized control.” — (MIT 6.8521/18.437)
-
分布式系统:“A distributed system is a collection of independent computers that appears to its users as a single coherent system.” — Distributed Systems: Principles and Paradigms
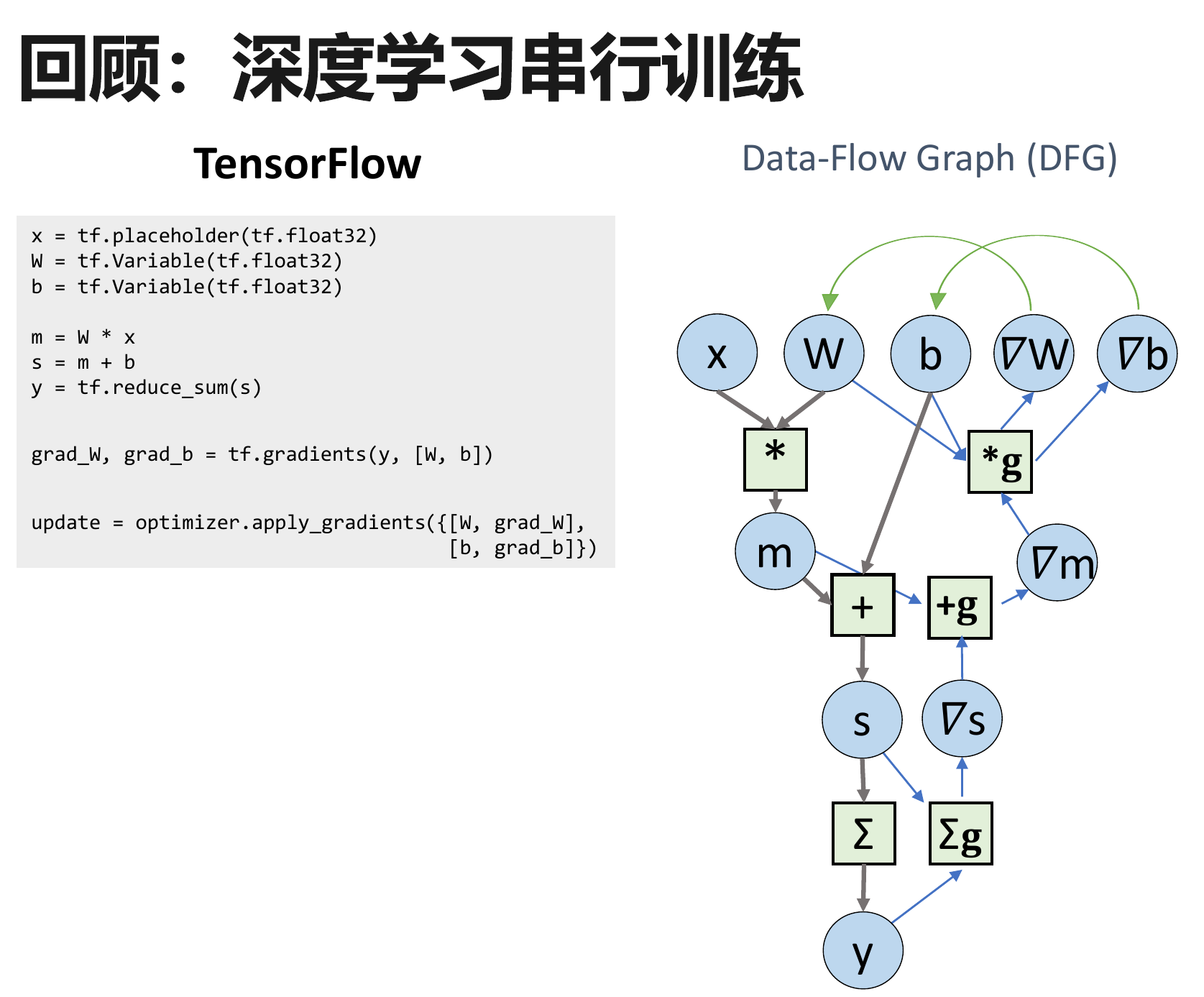
多个样本、多个操作、张量计算都可以有并行潜力。
算子内并行:
并行单个张量计算算子内的计算(GPU 多处理单元执行)

算子间并行:
数据并行:多个样本并行
模型并行:多个算子并行
组合并行:多种并行
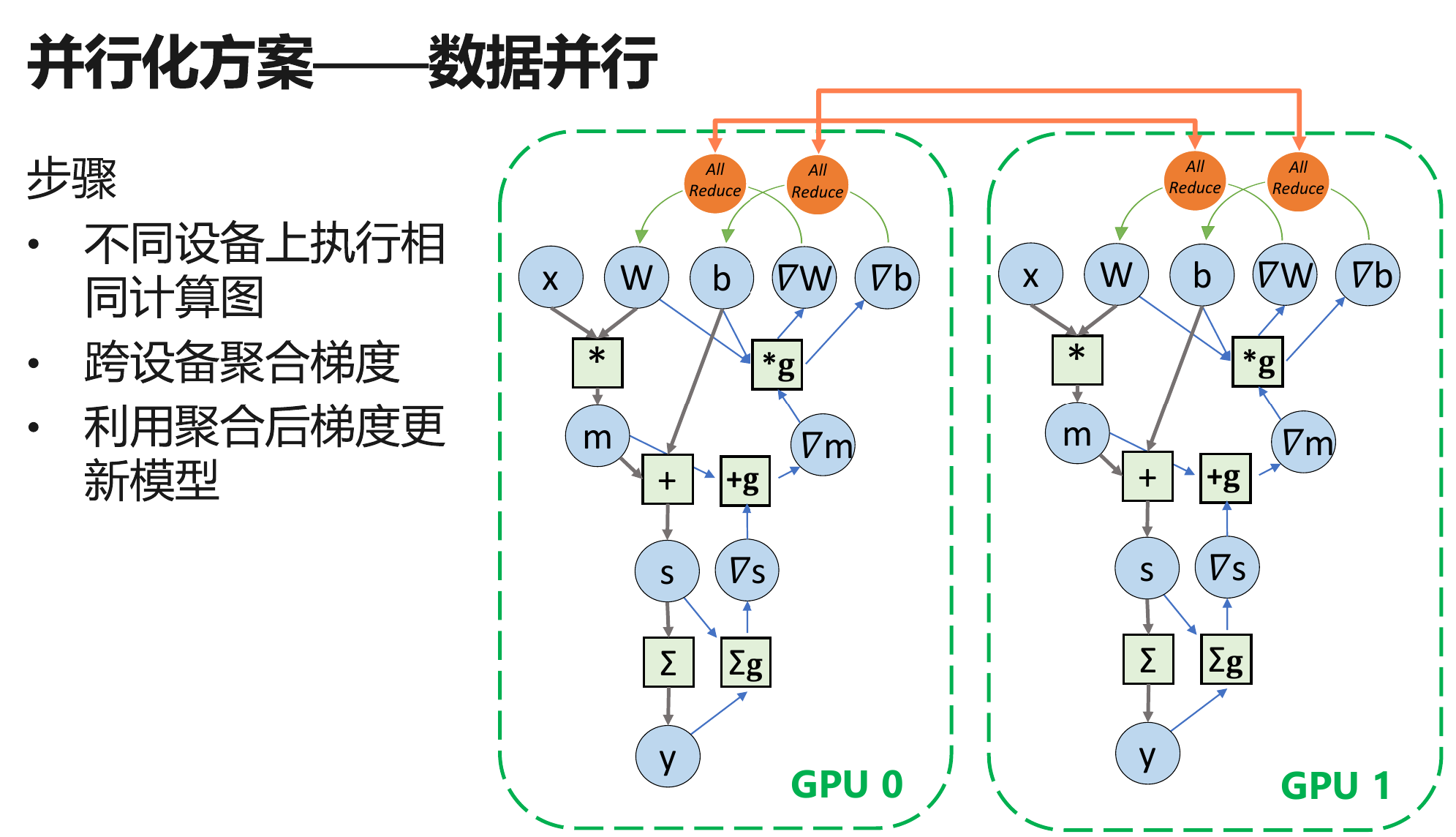
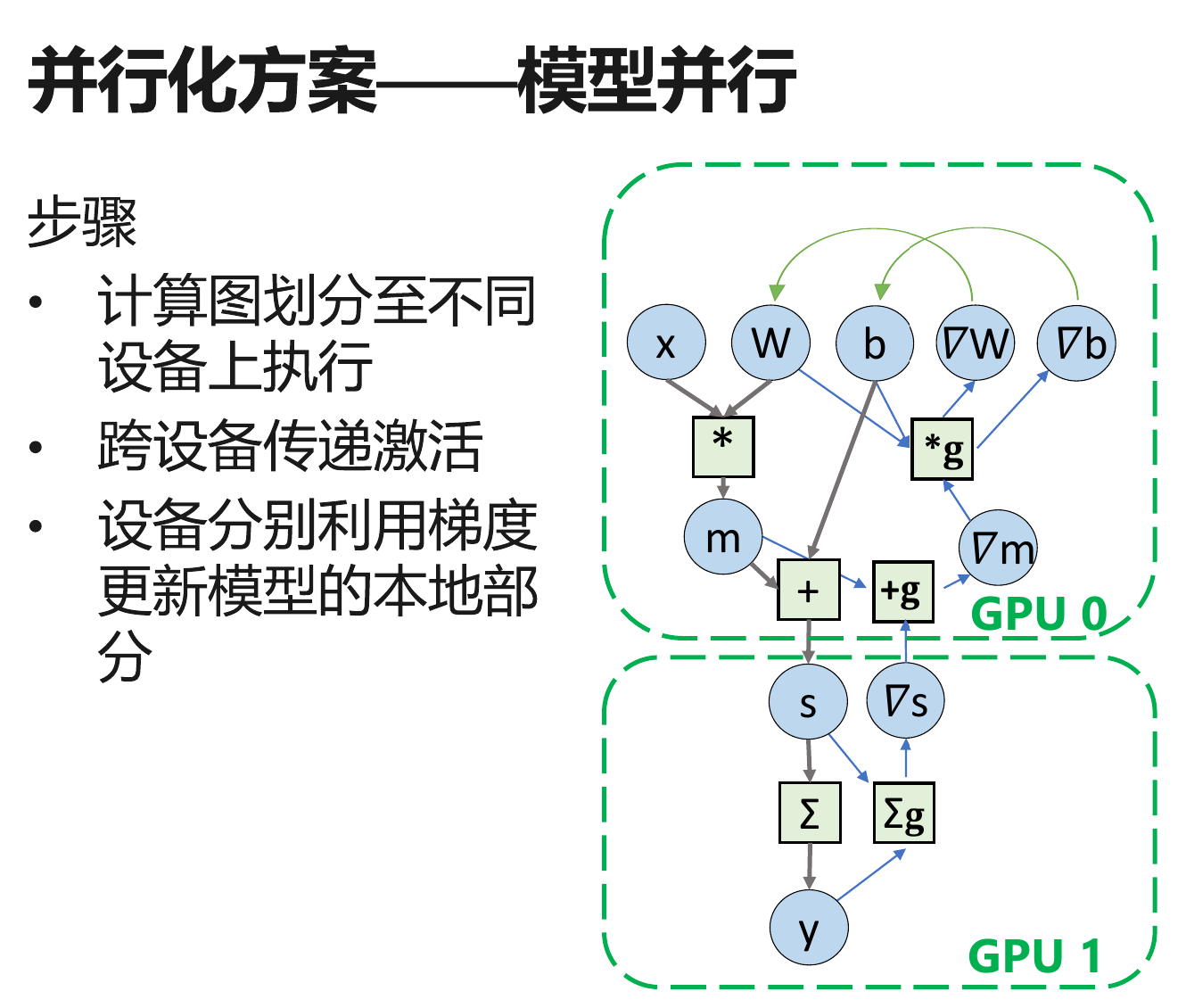
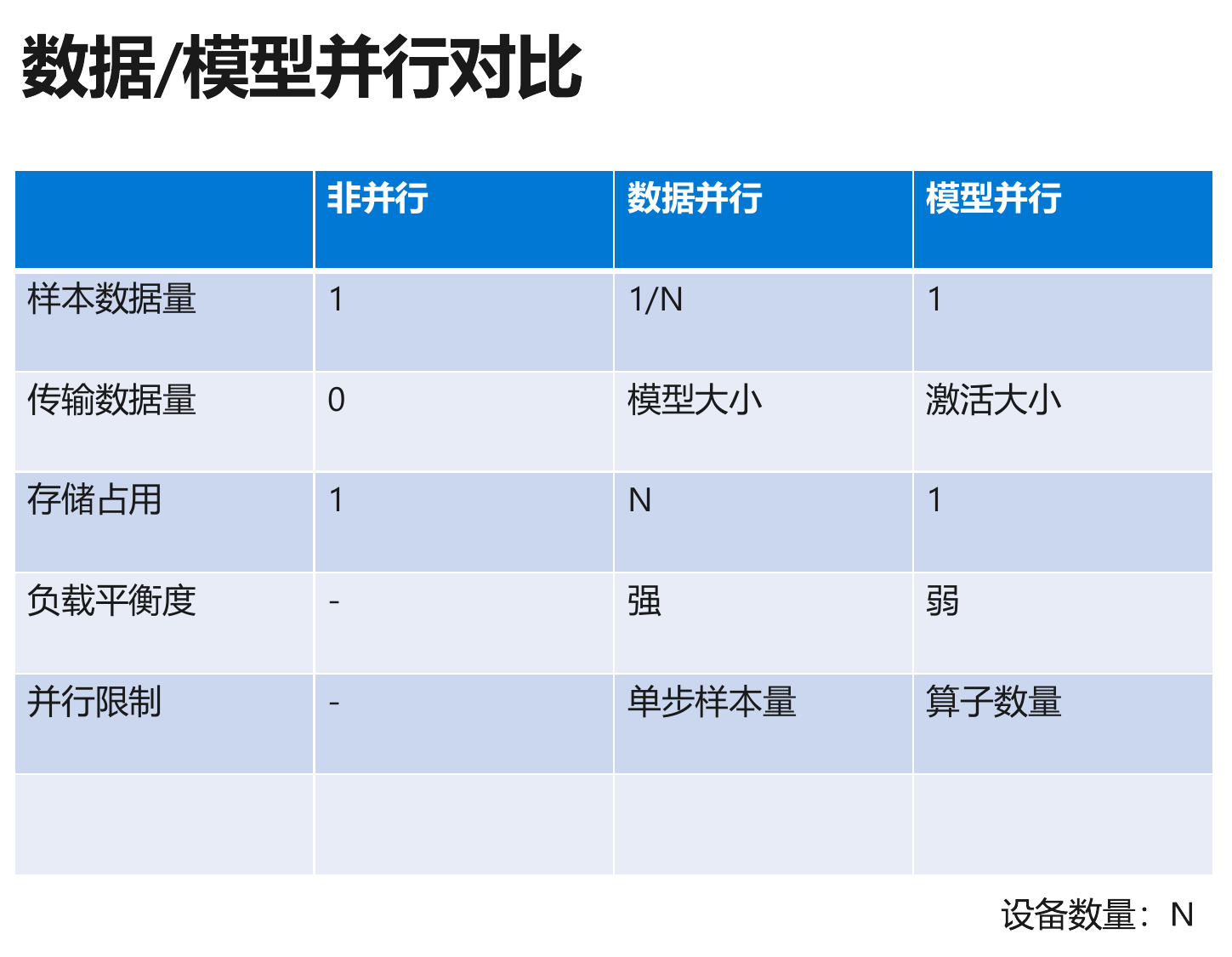
深度学习并行训练
并行算法通信类型
同步并行:采用具有同步屏障的通信协调并行
异步并行:采用不含同步屏障的通信协调并行
半同步并行:采用具有限定的宽松同步屏障的通信协调并行
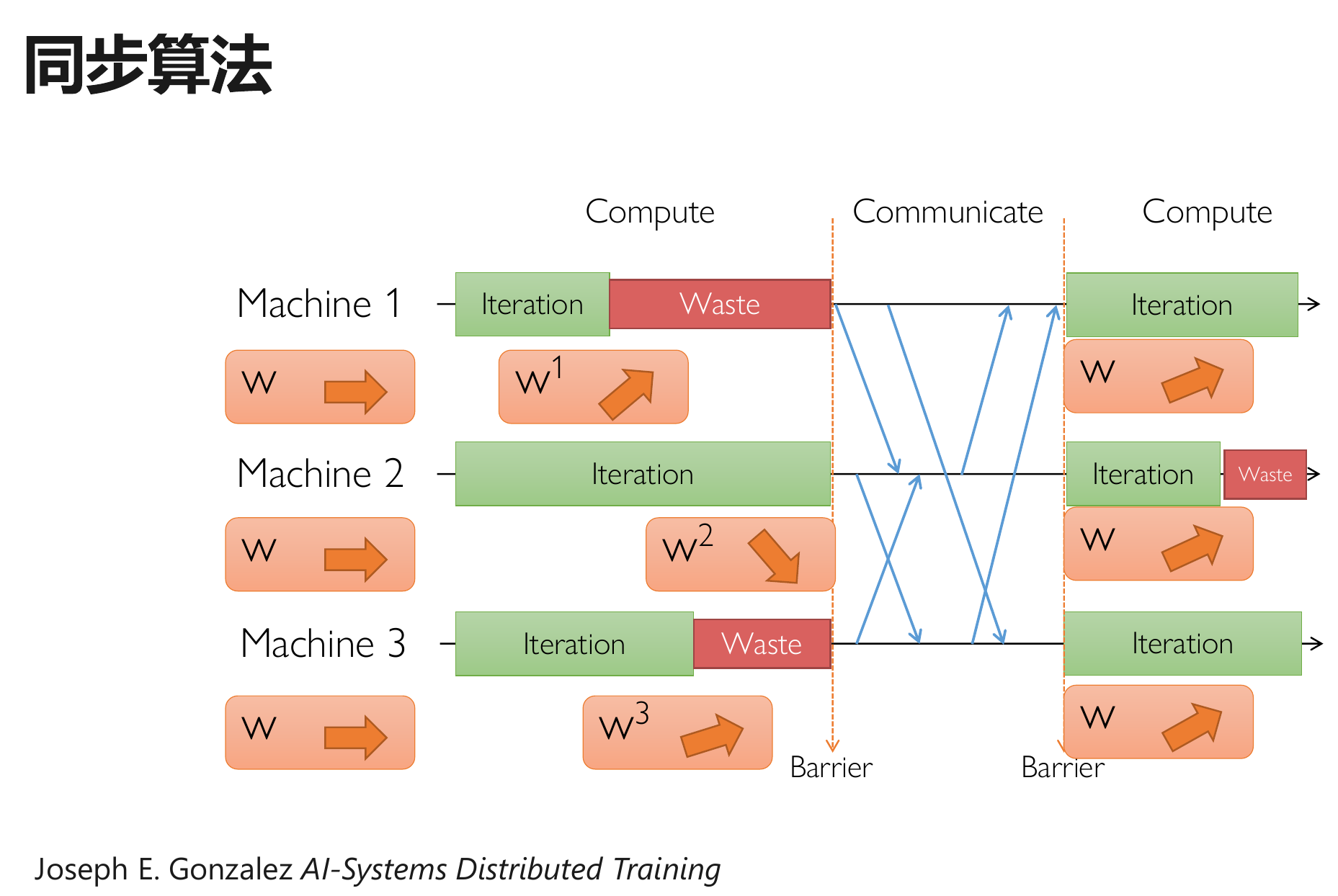
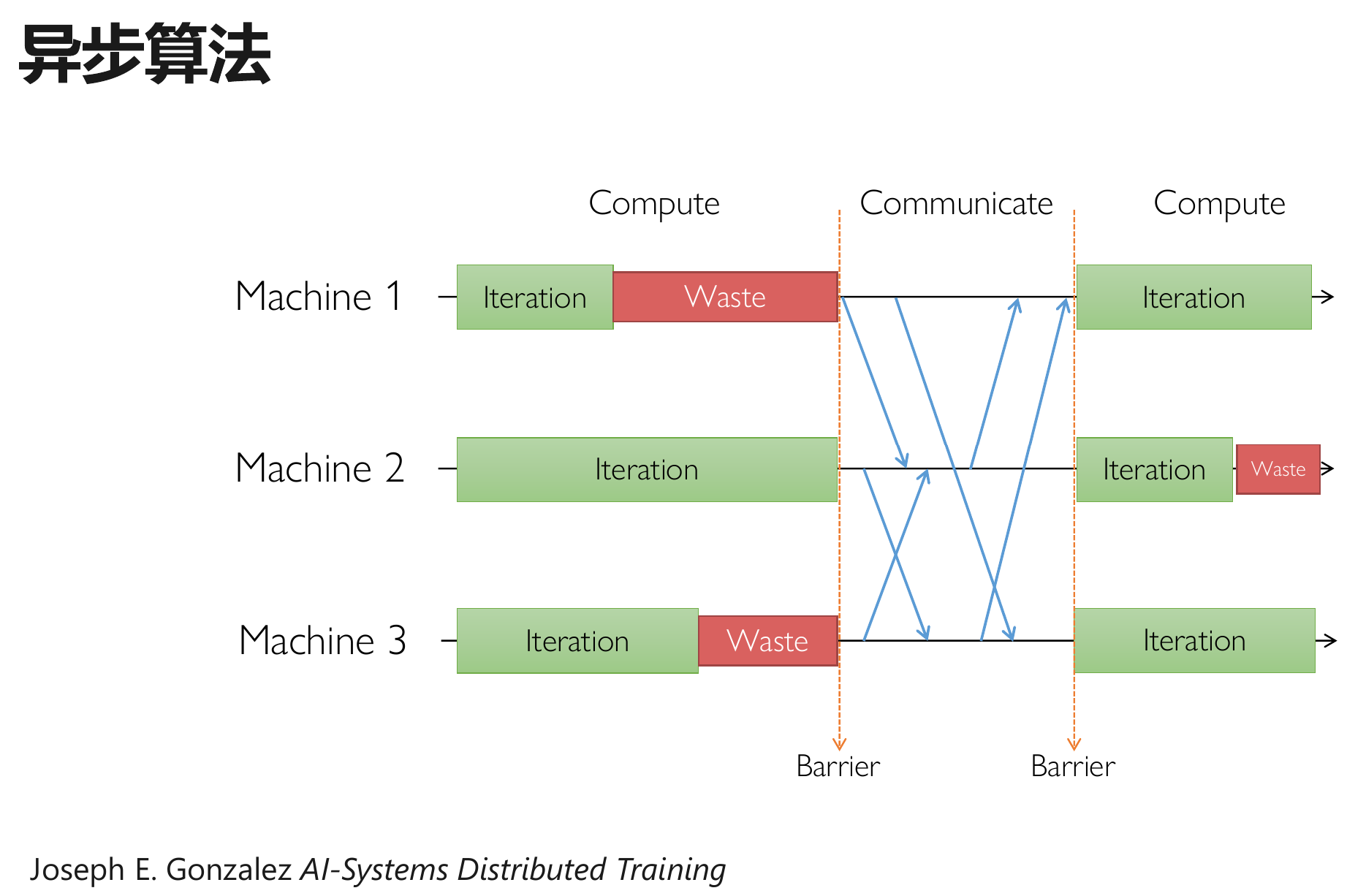
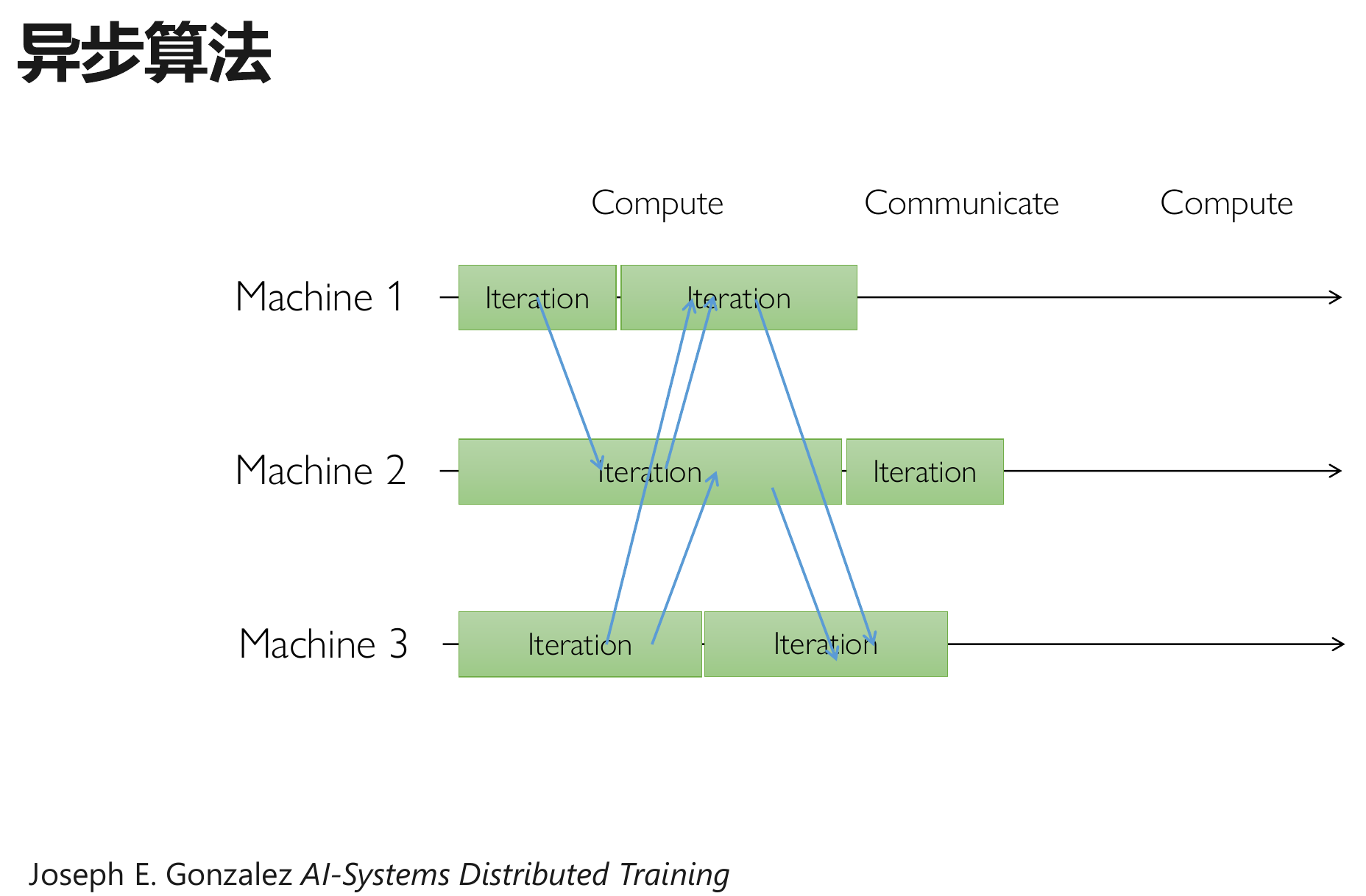
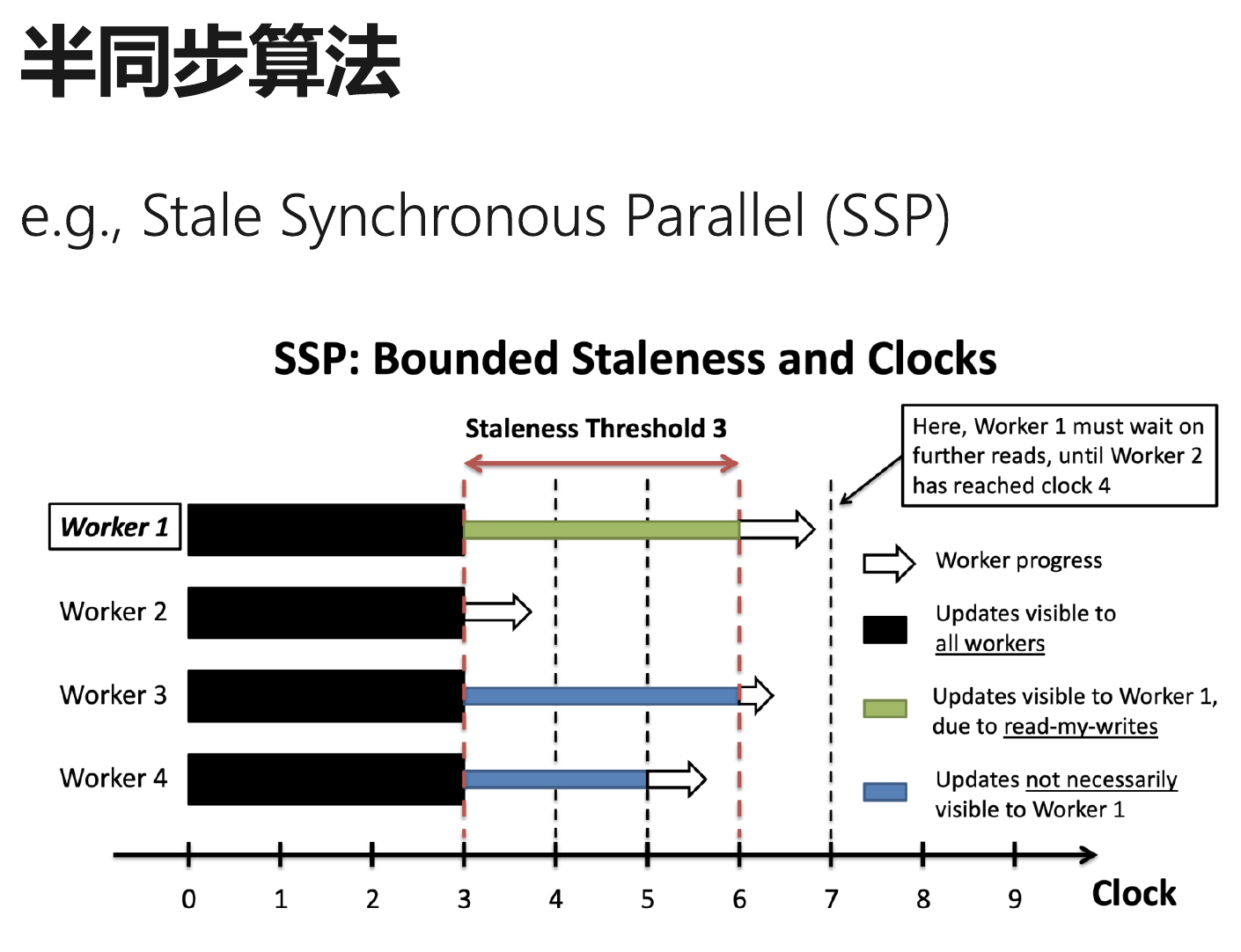
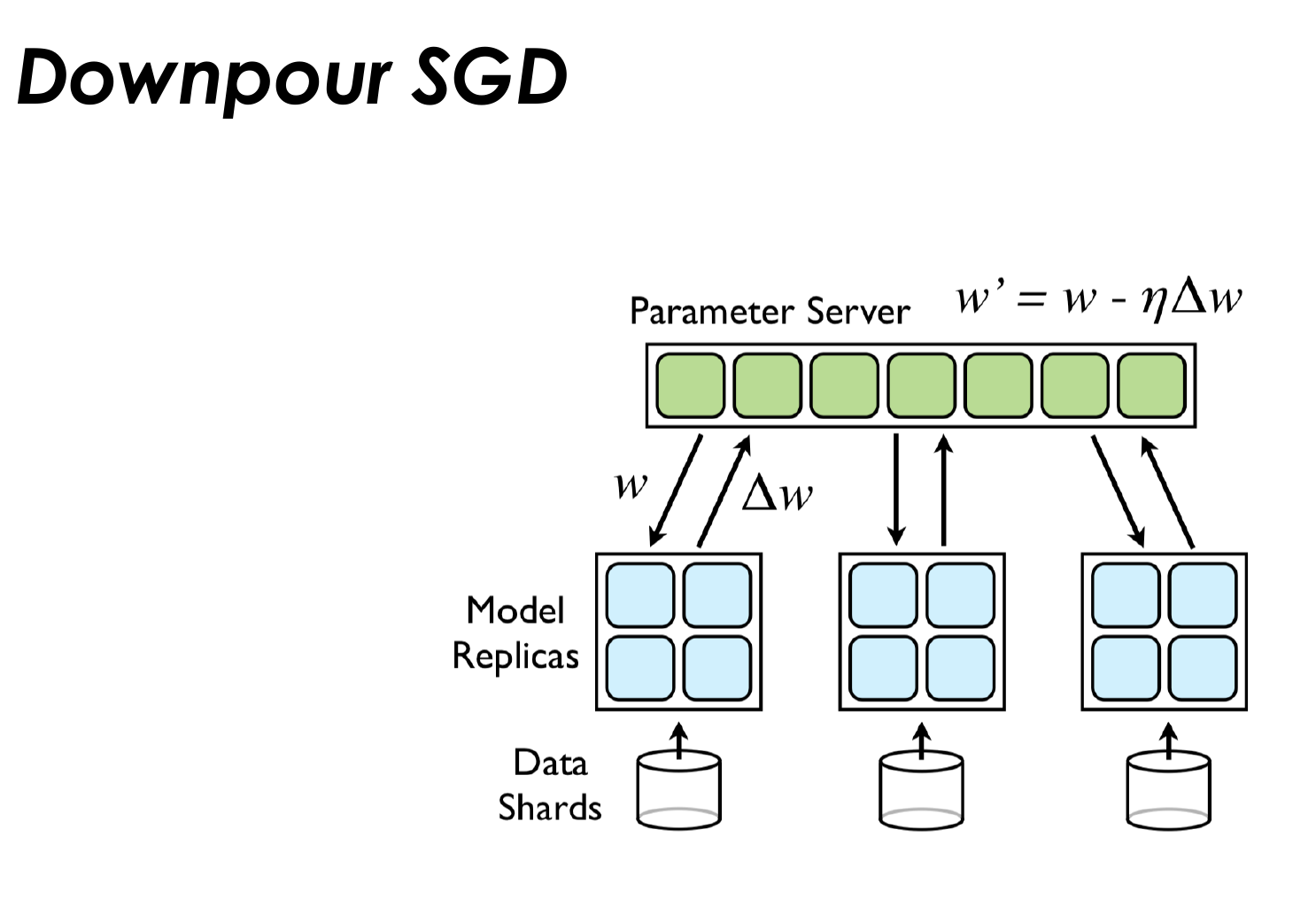
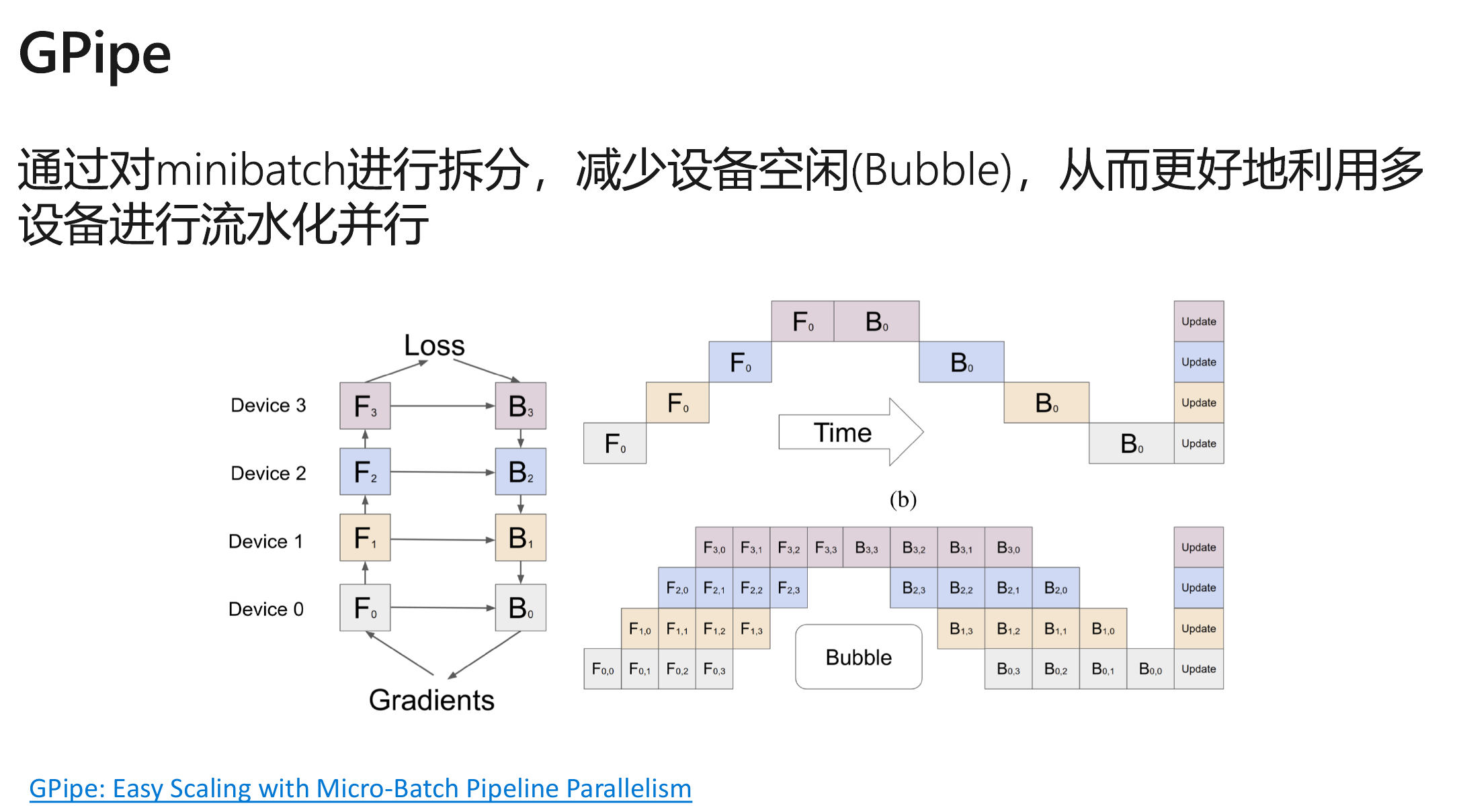
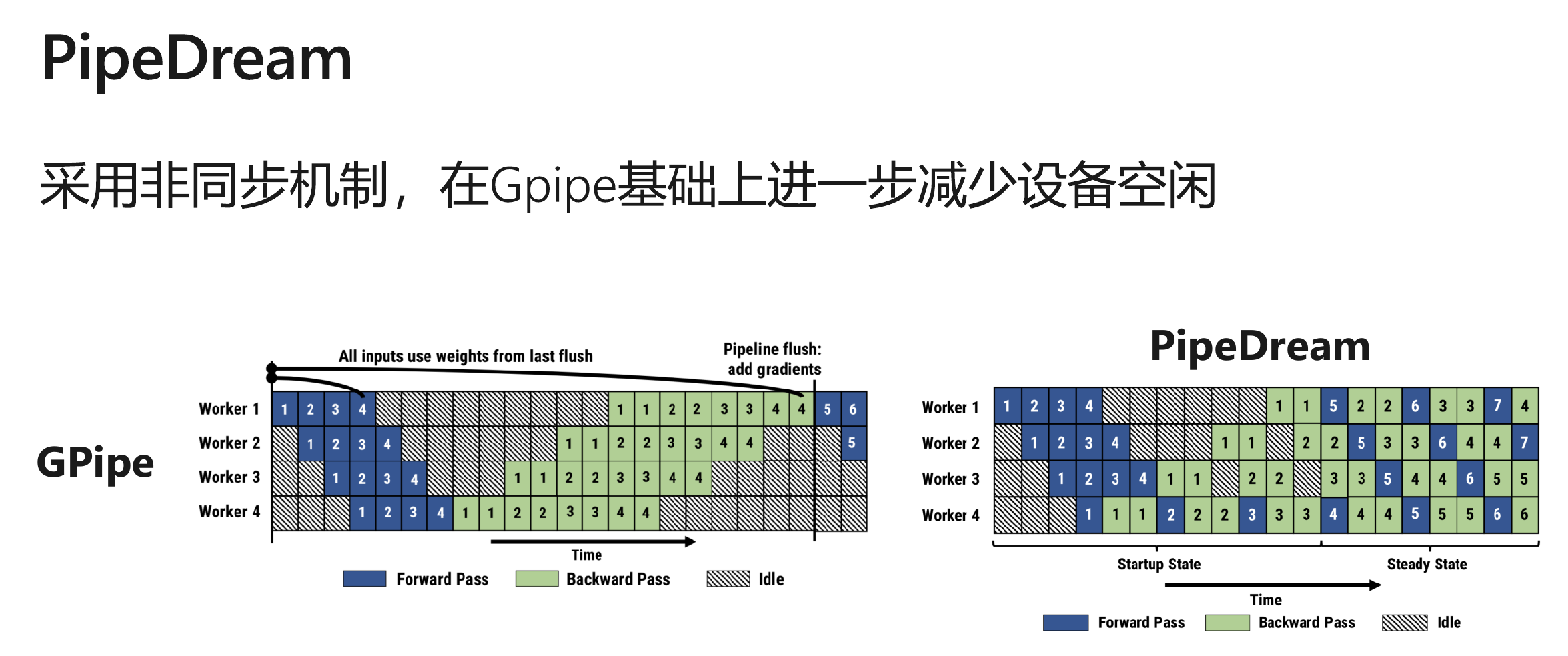
分布式训练算法
实例
分布式系统 Pytorch
点对点 + 集合通信
https://pytorch.org/tutorials/intermediate/dist_tuto.html
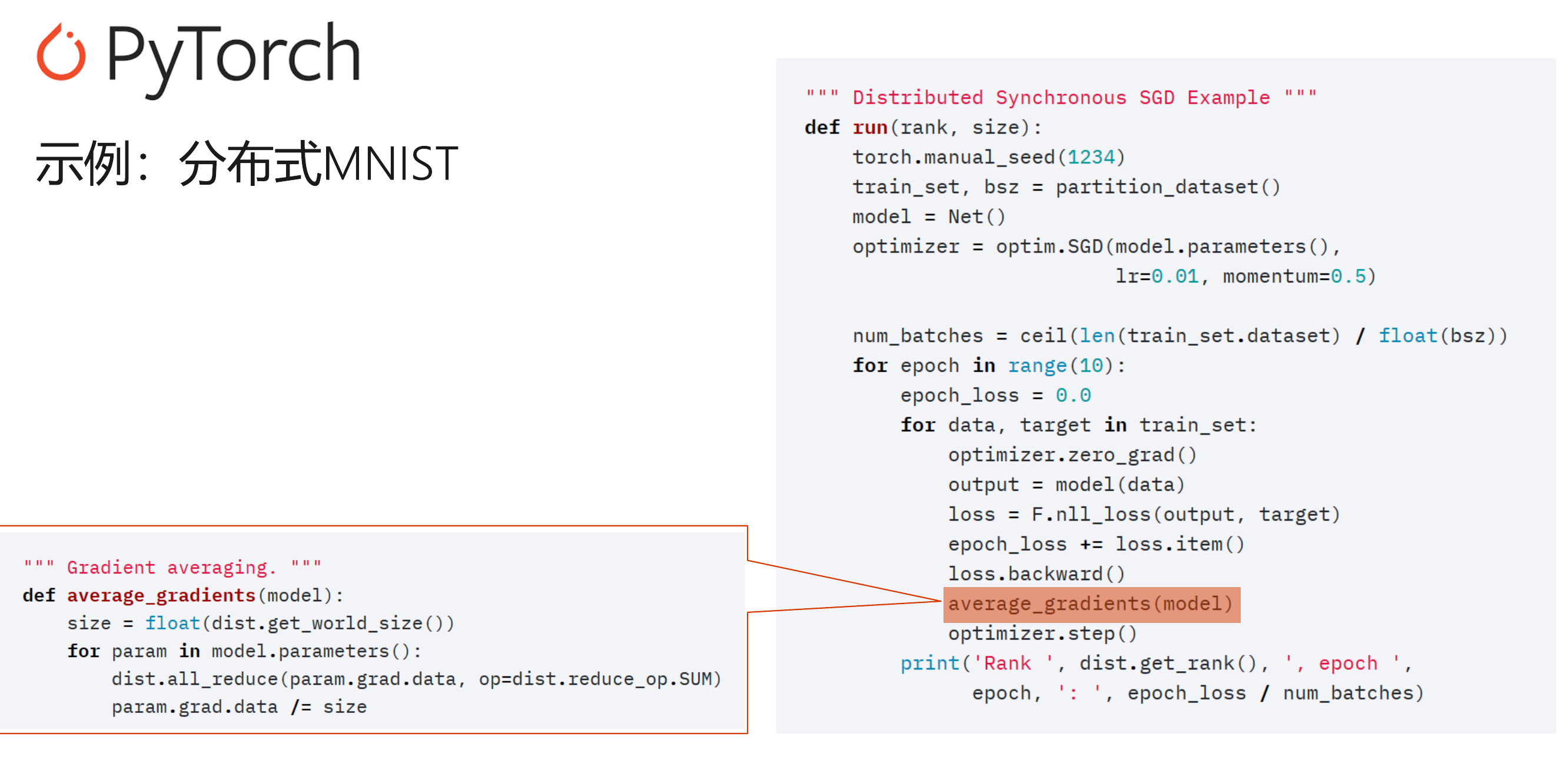
MPI/NCCL/GLOO