- 4.1
- 4.2
- 4.3
- [ ]
一个大的程序往往会分成多个源程序文件来编写, 因而需要对各个不同源程序文件分别进行编译或汇编, 以生成多个不同的目标代码文件, 这些目标代码文件中包含指令、数据和其他说明信息。此外, 在程序中还会调用一些标准库函数。为了生成一个可执行文件, 需要将所有关联到的目标代码文件, 包括用到的标准库函数目标文件, 按照某种形式组合在一起, 形成一个具有统一地址空间的可被加载到存储器直接执行的程序。
链接
这种将一个程序的所有关联模块对应的目标代码文件结合在一起, 以形成一个可执行文件的: 过程称为链接。 现在由专门的链接程序 (linker, 也称为链接器) 来实现。
4.1 编译、汇编和静态链接
链接概念早在高级编程语言出现之前就已存在。例如,在汇编语言代码中,可以用一个标号表示某个转移目标指令的地址 (即给定了一个标号的定义), 而在另一条转移指令中引用该标号:也可以用一个标号表示某个操作数的地址,而在某条使用该操作数的指令中引用该标号。因而,在对汇编语言源程序进行汇编的过程中,对每个标号的引用,需要找到该标号对应的定义,建立每个标号的引用和其定义之间的关联关系,从而在引用标号的指令中正确地填入对应的地址码字段,以保证能访问到所引用的符号定义处的的信息。在高级编程语言出现之后,程序功能越来越复杂,规模越来越大,需要多人开发不同的程序模块。
符号定义与符号引用
在每个程序模块中,包含一些变量和子程序 (函数) 的定义。这些被定义的变量和子程序的起始地址就是符号定义,子程序 (函数或过程) 的调用或者在表达中使用变量进行计算就是符号引用。某一个模块中定义的符号可以被另一个模块引用,因而最终必须通过链接将程序包含的所有模块合并起来,合并时须在符号引用处处填入定义处的地址。
4.1.1 编译和汇编
将高级语言源程序文件转换为可执行目标文件通常分为预处理、编译、汇编和链接四个步骤。前面三个步骤用来对每个模块 (即源程序文件) 生成可重定位目标文件 (relocatable object file)。最后一个步骤为链接,用来将若干可重定位目标文件 (可能包括若干标准库函数目标模块) 组合起来, 生成一个可执行目标文件 (executable object file)。有时将可重定位目标文件和可执行目标文件分别简称可重定位文件和可执行文件。
下面以 GCC (GNU Compiler Collection) 处理 C 语言程序为例来说明处理过程
假设我们有一个简单的 C 语言源文件 hello.c:
#include <stdio.h>
#define PI 3.14159
int main() {
printf("Hello, World! PI is %.5f\n", PI);
return 0;
}cpp, cc1, as, ld 是 GCC (GNU Compiler Collection) 在将 C/C++ 源代码转换为可执行程序的过程中,背后调用的核心工具。它们分别对应编译流程的四个主要阶段:预处理、编译、汇编和链接。
虽然我们通常直接使用 gcc 或 g++ 命令,但这些命令实际上是驱动程序 (driver),它们会根据需要自动调用这些底层工具来完成具体任务。使用 gcc 时可以用 -v 查看每一步的处理过程。如果想要得到每一步的结果,也可以分别调用处理。
1. 预处理 (Preprocessing)
cpp - C/C++ 预处理器 (C/C++ Preprocessor)
作用:预处理阶段主要处理源代码中以 # 开头的预处理指令(如 #include, #define, #ifdef 等)。具体任务包括:
- 包含头文件:将
#include <stdio.h>这样的指令替换为实际的头文件内容。 - 宏展开:将宏定义(如
PI)替换成其定义的值。 - 条件编译:根据
#ifdef,#ifndef等指令决定是否包含某段代码。 - 删除注释:移除源代码中的注释。
- 处理
#pragma指令。
GCC 命令:
gcc -E hello.c -o hello.i
cpp hello.c -o hello.i-E选项告诉 GCC 只进行预处理。-o hello.i指定输出文件名为hello.i(通常为.i后缀)。
结果:
生成的 hello.i 文件是一个经过预处理的 C 语言源代码文件。它包含了 stdio.h 的所有内容,并且 PI 已被替换为 3.14159,注释也被删除。这个文件仍然是人类可读的 C 代码。
2. 编译 (Compilation)
cc1 - C 编译器 (C Compiler) / cc1plus - C++ 编译器
作用:将预处理后的 C 语言源代码(.i 文件)解析、分析(词法、语法、语义),进行优化,最终翻译成特定目标架构的汇编语言代码(.s 文件)。这个过程包括:
- 词法分析、语法分析、语义分析。
- 根据分析结构优化代码(可选,取决于优化选项)和存储分配。
- 生成与目标处理器架构(如 x86_64)对应的汇编指令。
- 这个过程可能会分多次扫描,每次完成不同的任务。 特点:
cc1/cc1plus通常是内部工具,不直接提供给用户在命令行调用。普通用户通过gcc/g++命令并使用-S选项来触发编译阶段。- 你可以通过
gcc -v(verbose)选项查看gcc内部是如何调用cc1的。
GCC 命令:
gcc -S hello.i -o hello.s
ccl hello.i -o hello.s-S选项告诉 GCC 只进行到编译阶段,生成汇编代码。-o hello.s指定输出文件名为hello.s(通常为.s后缀)。
注意:你也可以直接从
.c文件开始编译,GCC 会自动先进行预处理再编译:gcc -S hello.c -o hello.s
结果:
生成的 hello.s 文件是汇编语言源代码文件。它包含的是人类可读的、但与机器指令一一对应的汇编指令(如 mov, call, push 等),针对特定的 CPU 架构。
3. 汇编 (Assembly)
as - 汇编器 (Assembler)。as 是 GNU Binutils (Binary Utilities) 包的一部分,通常称为 GNU Assembler。
作用:汇编阶段将汇编语言源代码 (hello.s) 翻译成机器可以直接执行的目标代码(Object Code)。目标代码是二进制格式的机器指令,但它还不是可以直接运行的完整程序。
- 汇编器 (
as) 将每条汇编指令转换成对应的机器码(二进制)。 - 生成的目标文件(
.o或.obj)包含了机器码、数据、符号表(函数名、变量名等)以及重定位信息。
GCC 命令:
gcc -c hello.s -o hello.o
as hello.s -o hello.o-c选项告诉 GCC 进行到汇编阶段,生成目标文件,但不进行链接。-o hello.o指定输出文件名为hello.o(通常为.o后缀)。
注意:你也可以直接从
.c或.i文件开始汇编,GCC 会自动完成前面的步骤:gcc -c hello.c -o hello.o
结果:
生成的 hello.o 文件是一个目标文件(Object File)。它是二进制文件,包含了 main 函数的机器码,但其中对 printf 函数的调用只是一个未解析的符号引用(因为 printf 的定义在标准库中,不在这个文件里)。目标文件还包含了重定位信息,告诉链接器将来如何调整地址。
汇编的功能是将编译生成的汇编语言代码转换为机器语言代码。因为通常最终的可执行目标文件由多个不同模块对应的机器语言目标代码组合而形成,所以,在生成单个模块的机器语言目标代码时,不可能确定每条指令或每个数据最终的地址,也即,单个模块的机器语言目标代码需要重新定位, 因此, 通常把汇编生成的机器语言目标代码文件称为可重定位目标文件。
4.1.2 可执行目标文件的生成
链接 (Linking)
ld - 链接器 (Linker),更准确地说,它是 GNU 工具链中的静态链接器(static linker)。ld 也是 GNU Binutils 包的核心组件,称为 GNU Linker。
注意:
hello的例子用到了动态库动态链接,见后,本节分析静态链接。
作用:
链接阶段(静态和动态)将一个或多个可重定位目标文件(.o)以及所需的库文件(如标准 C 库 libc.a 或 libc.so)组合起来,形成一个单一的、完整的可执行文件。主要任务包括:
- 符号解析:找到所有未定义符号(如
printf)的实际定义。 - 重定位:将各个目标文件中的代码和数据段合并,并为所有符号(函数、变量)分配最终的内存地址。
- 处理库函数:将程序中用到的库函数(如
printf)的代码链接进来(静态链接)或建立动态链接信息(动态链接)。
ld 手动调用非常复杂,需要手动指定启动代码(crt*.o)、C 标准库(-lc)和动态链接器路径。例如,对于图 4.1 所示的两个模块 main.c 和 test.c,假定通过预处处理、编译和汇编,分别生成了可重定位目标文件 main.o 和 test.o。

GCC 命令:
gcc -o test main.o test.o
ld -o test main.o test.o- 这是最常见的链接命令。
gcc会自动调用链接器 (ld)。 test.o main.o是输入的目标文件。-o test指定最终的可执行文件名为test(在 Windows 上通常是test.exe)。
注意:GCC 通常允许你一步到位:
gcc test.c main.c -o main这条命令会依次执行预处理、编译、汇编和链接四个步骤,直接生成可执行文件main。
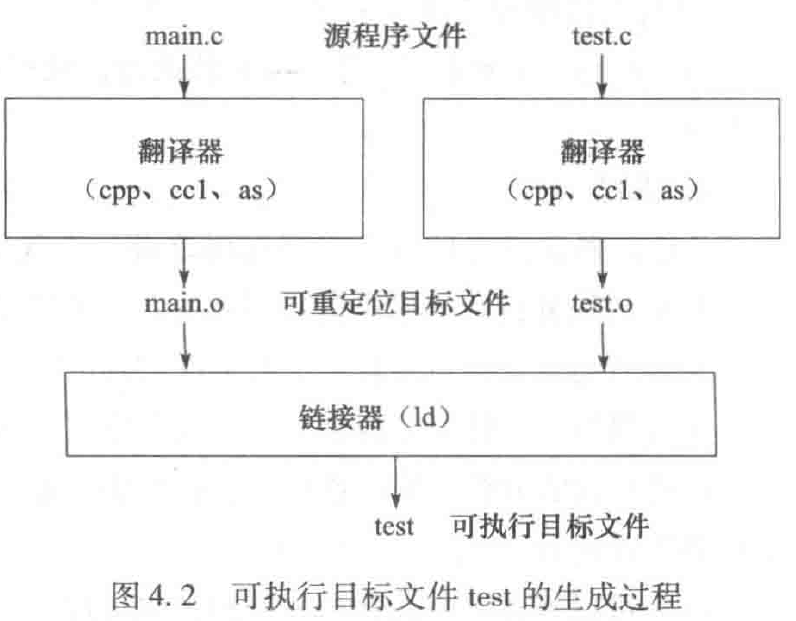
结果:生成的 test 文件就是一个可执行目标文件。它包含了程序运行所需的所有机器代码,并且已经完成了地址分配,操作系统可以直接加载并运行它。
编译流程总结
| 工具 | 阶段 | 主要功能 | 输入文件 | 输出文件 | 所属包/说明 |
|---|---|---|---|---|---|
cpp | 预处理 | 处理 #include, #define, 宏展开等 | .c, .cpp | .i, .ii | GCC (预处理器) |
cc1 | 编译 (C) | C 源码 → 汇编代码 | .i | .s | GCC (内部编译器, C 专用) |
cc1plus | 编译 (C++) | C++ 源码 → 汇编代码 | .ii | .s | GCC (内部编译器, C++ 专用) |
as | 汇编 | 汇编代码 → 目标代码 (机器码) | .s | .o | GNU Binutils (汇编器) |
ld | 链接 | 目标文件 + 库 → 可执行文件 | .o, .a, .so | 可执行文件, .so, .a | GNU Binutils (链接器) |
总结流程图:
hello.c (源代码)
|
| 预处理 (gcc -E)
V
hello.i (预处理后的C代码)
|
| 编译 (gcc -S)
V
hello.s (汇编代码)
|
| 汇编 (gcc -c)
V
hello.o (目标文件/二进制代码)
|
| 链接 (gcc)
V
hello (可执行文件)
当你运行 gcc hello.c -o hello 时,GCC 驱动程序会按顺序调用这些工具(cpp → cc1 → as → ld),最终生成可执行文件 hello。通过这四个步骤,
GCC 成功地将人类可读的高级 C 语言源代码转换成了计算机可以执行的二进制程序。
可重定位目标文件和可执行目标文件
可重定位目标文件(Relocatable Object File)和可执行目标文件(Executable Object File)都是机器语言目标你文件,不同的是:
- 可重定位目标文件是单个模块生成的,它是编译后生成的
.o或.obj文件,包含机器代码和数据,但地址尚未最终确定,可参与链接。 - 可执行目标文件是多个模块组合成的,它是链接后生成的可运行程序(如 Linux 的 ELF、Windows 的 PE),可直接被操作系统加载执行。
| 维度 | 可重定位目标文件(Relocatable) | 可执行目标文件(Executable) |
|---|---|---|
| 生成方式 | gcc -c main.c → main.o | gcc main.o -o main(链接后) |
| 文件格式 | ELF(类型为 ET_REL) | ELF(类型为 ET_EXEC 或 ET_DYN) |
| 是否可执行 | ❌ 不能直接运行 | ✅ 可通过 ./main 执行 |
| 地址是否固定 | ❌ 使用相对地址或符号占位 | ✅ 各节(如 .text, .data)有确定虚拟地址 |
| 是否包含完整地址信息 | ❌ 需要重定位(Relocation) | ✅ 已完成重定位 |
| 是否可参与链接 | ✅ 可与其他 .o 文件链接 | ❌ 一般不再参与链接(除非是共享库) |
| 重定位表 | ✅ 包含 .rela.text, .rela.data 等 | ❌ 通常不含(静态链接后已解析) |
| 符号表 | ✅ 包含未解析符号(如 printf) | ✅ 符号可能被保留或剥离 |
| 入口点(Entry Point) | ❌ 无 _start 入口地址 | ✅ 有明确入口地址(如 _start) |
| 依赖外部库 | ✅ 依赖的函数符号未定义 | ✅ 静态链接库已合并,动态链接库在运行时解析 |
前者的代码从 0 开始,后者在 ABI 规范规定的虚拟地址空间中产生,objdump -d 可以看到函数的起始地址,前者从 0 开始,而后者有一个特定的地址。
关于详细的利用工具对编译的文件进行解读,见 编译文件解读。
实际上,可重定位目标文件和可执行目标文件都不是可以直接显示的文本文件,而是不可显示的二进制文件,它们都按照一定的格式以二进制字节序列构成一种目标文件,其中包含二进制代码区、只读数据区、已初始化数据区和未初始化数据区等,每个信息区称为一个节 (section),如代码节 (.text)、只读数据节 (.rodata)、已初始化全局数据节 (.cdata) 和未初始化全局数据节 (.bss) 等。
静态链接器作用
静态链接器将多个可重定位目标文件合成一个可执行目标文件,主要完成以下两个任务。
- 符号解析
符号解析的目的是将每个符号的引用与一个确定的符号定义建立关联(符号引用和符号定义)。符号包括全局静态变量名和函数名,而非静态局部变量名则不是符号。例如,于图 4.1 所示的两个源程序文件 main.c 和 test.c,在 main.c 中定义了符号 main,并引用了符号 add;在 test.c 中则定义了符号 add,而 i、j 和 x 都不是符号。链接时需要将 main.o 中引用的符号 add 和 test.o 中定义的符号 add 建立关联。对于全局变量声明 int *xp=&x;,可看成引用符号 x 对符号 xp 进行定义。编译器将所有符号存放在可重定位目标文件的符号表中。
- 重定位
可重定位目标文件中的代码区和数据区都是从地址 0 开始的,链接器需要将不同模块中相同的节合并起来生成一个新的单独的节,并将合并后的代码和数据区按照 ABI 规范确定的虚拟地址空间划分(也称存储器映像) 来重新确定位置。例如,对于 32 位 Linux 系统存储器映像,其只读代码段总是从地址 0x8048000 开始,而可读可写数据段总是在代码段后面的第一个 4KB 对齐的地址处开始。
重定位
链接器需要重新确定每条指今和每个数据的地址,并且在指令中需要明确给定所引用符号的地址,这种重新确定代码和数据的地址并更新指令中被引用符号地址的工作称为重定位(relocation)。
使用链接的第一个好处就是 ” 模块化 “,它能使一个程序被划分成多个模块,由不同的程序员进行编写,并且可以构建公共的函数库 (如数学函数库、标准 I/0 函数库等) 以提供给不同的程序进行重用。采用链接的第二个好处是 ” 效率高 “,每个模块可以分开编译,在程序修改时只需重新编译那些修改过的源程序文件,然后再重新链接,因而从时间上来说能够提高程序开发的效率;同时,因为源程序文件中无须包含共享库的所有代码,只要直接调用即可,而且在可执行文件运行时的内存中,也只需要包含所调用的函数的代码而不需要包含整个共享库,所以链接也有效提高了空间利用率。
链接的模块化提升效率。
4.2 目标文件格式
目标代码(object code) 指编译器或汇编器处理源代码后所生成我的机器语言目标代码。目标文件(object file) 指存放目标代码的文件。
4.2.1 ELF 目标文件格式
目标文件中包含可直接被 CPU 执行的机器代码以及代码在这运行时使用的数据,还有其他的如重定位信息和调试信息等。不过,目标文件中唯一与运行时相关的要素是机器代码及其使用的数据,例如,用于嵌入式系统的目标文件可能仅仅含有机器代码及其使用数据。
目标文件格式有许多不同的种类,如 COM、COFF 和 ELF。System V UNIX 的早期版本使用的是通用目标文件格式 (Common Object File Format,简称 COFF)。Windows 使用的是 COFF 的一个变种,称为可移植可执行格式 (Portable Executable,简称 PE)。现代 UNIX 操作系统,如 Linux、BSD UNIX 等,主要使用可执行可链接格式(Executableand Linkable Format,简称 ELF),本章采用 ELF 标准二进制文件格式进行说明。
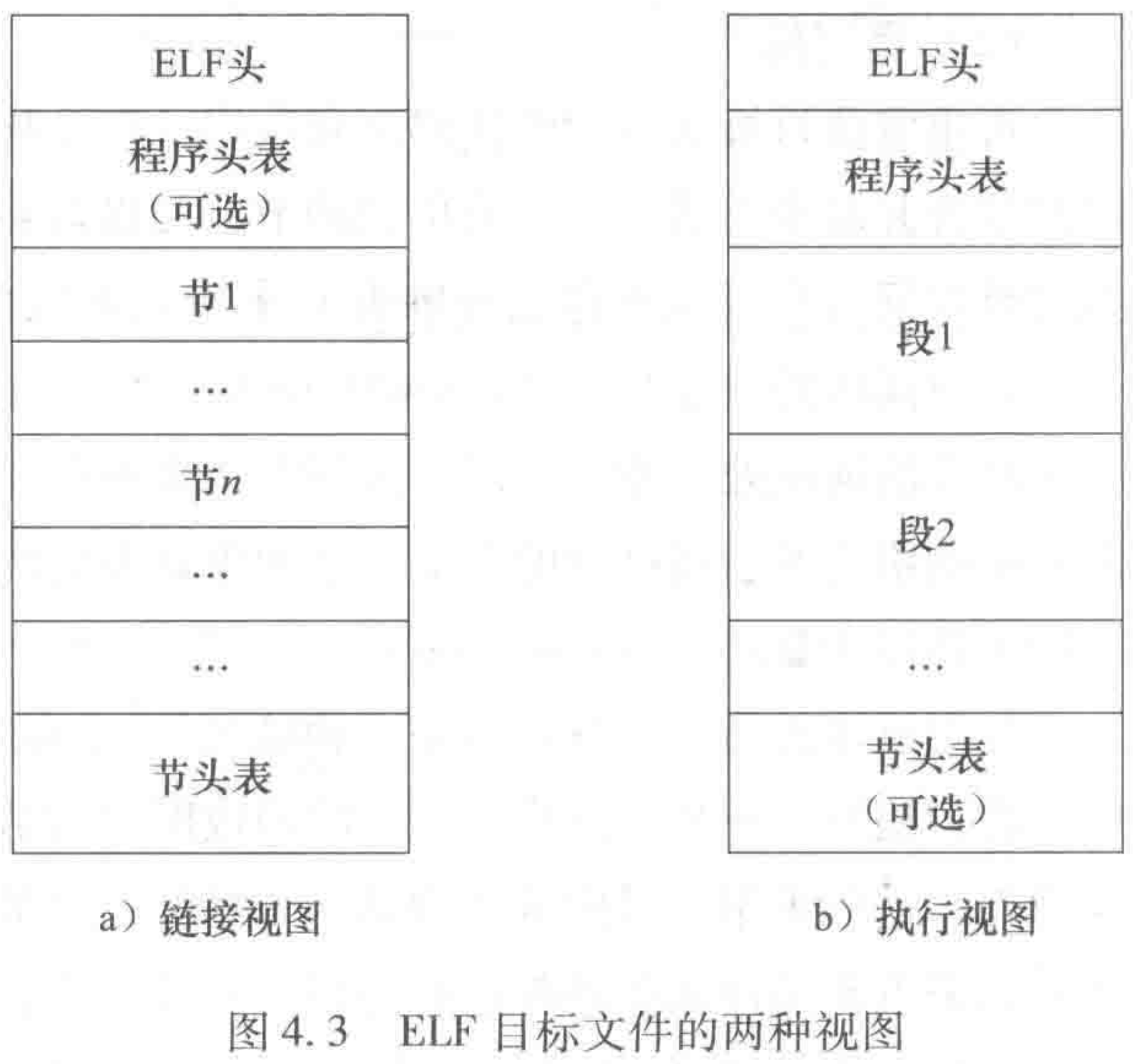
目标文件既用于程序链接,也可用于程序执行。图 4.3 说明了 ELF 目标文件格式的基本框架。
ELF 文件格式
- 图 4.3a 是链接视图,主要由不同的节(section) 组成,节是 ELF 文件中具有相同特征的最小可处理信息单位,不同的节描述了目标文件中不同类型的信息及其特征,例如,代码节 (
.text)、只读数据节 (.rodata)、已初始化全局数据节 (.data)、未初始化全局数据节 (.bss) 等。- 图 4.3b 是执行视图,主要由不同的段(segment) 组成,描述了目标文件中的节如何映射到存储空间的段中。可以将多个节合并后映射到同一个段,例如,可以合并节
.data和节.bss的内容,并映射到一个可读可写数据段中。
前面提到通过预处理、编译和汇编三个步骤后,可生成可重定位目标文件,多个关联的可重定位目标文件经过链接后生成可执行目标文件。这两类目标文件对应的 ELF 视图不同,显然,可重定位目标文件对应链接视图,而可执行目标文件对应执行视图。
节头表包含文件中各节的说明信息,每个节在该表中都有一个与之对应的项,每一项都指定了节名和节大小之类的信息。用于链接的目标文件必须具有节头表,例如,可重定位目标文件就一定要有节头表。程序头表用来指示系统如何创建进程的存储器映像。用于创建进程存储器映像的可执行文件和共享库文件必须具有程序头表,而可重定位目标文件不需要程序头表。
ELF 的核心形态(节的存在形式与功能因形态不同而有差异):
| 形态 | 全称 | 核心用途 | 节的特点 |
|---|---|---|---|
| 可重定位文件(.o) | Relocatable File | 编译后的目标文件(如 main.o),用于链接生成可执行文件或共享库 | 包含未解析的符号和重定位信息,节结构完整,供链接器处理 |
| 可执行文件(.out/.exe) | Executable File | 可直接运行的程序(如 a.out) | 节已被链接器合并、重定位,符号表可能被精简,供加载器加载 |
| 共享库(.so) | Shared Object File | 动态链接库(如 libc.so) | 节结构兼顾链接(供其他目标文件引用)和加载(供程序运行时调用) |
ELF 文件的整体结构可简化为下图:
[ ELF文件头(ELF Header) ] → 描述文件整体信息(类型、架构、节头表位置等)
[ 节头表(Section Header Table) ] → 每个表项对应一个“节”,记录节的名称、类型、大小、偏移等
[ 节内容(Sections) ] → 实际存储数据(代码、数据、符号表等),每个节对应节头表的一个表项
[ 程序头表(Program Header Table) ] → (仅可执行/共享库)描述“段(Segment)”,供加载器使用(段是节的集合)其中,节头表是 “节” 的 “目录” —— 链接器 / 加载器先读取节头表,再根据表项找到对应的节内容。
4.2.2 可重定位目标文件格式
可重定位目标文件主要包含代码部分和数据部分,它可以与其他可重定位目标文件链接,从而创建可执行目标文件、共享库文件。如图 4.4 所示,ELF 可重定位目标文件由ELF 头、节头表以及夹在 ELF 头和节头表之间的各个不同的节组成。
ELF 头
ELF 头位于目标文件的起始位置,包含文件结构说明信息。ELF 头的核心功能是定义 ELF 文件的基本特征,让工具能快速判断:
- 这是否为 ELF 文件(通过 “魔数” 验证);
- 文件的类型(可重定位文件、可执行文件、共享库等);
- 目标架构(如 x86、ARM、x86_64 等);
- 节头表 / 程序头表的位置、大小、条目数量(引导工具找到节和段的信息)。
没有 ELF 头,工具无法识别文件结构,更无法进行链接或加载。
ELF 头的结构由 ELF 规范定义,分为 32 位(Elf32_Ehdr)和 64 位(Elf64_Ehdr)两种,字段基本一致,仅部分字段的类型(如地址、偏移量)因位数不同而变化。32 位系统对应的共占 52 字节,64 位系统对应占 64 字节。
以下是32 位 ELF 头(Elf32_Ehdr) 的核心字段(64 位类似,仅将 Elf32_* 替换为 Elf64_*):
| 字段名 | 类型 | 长度(字节) | 含义与作用 |
|---|---|---|---|
e_ident | unsigned char | 16 | ELF 标识(“魔数”+ 文件属性),是识别 ELF 文件的关键 |
e_type | Elf32_Half | 2 | 文件类型(如可重定位文件、可执行文件、共享库) |
e_machine | Elf32_Half | 2 | 目标架构(如 x86=3、ARM=40、x86_64=62) |
e_version | Elf32_Word | 4 | ELF 版本(固定为 1,即 EV_CURRENT) |
e_entry | Elf32_Addr | 4 | 程序入口地址(可执行文件有效,指向 main 函数前的初始化代码;目标文件为 0) |
e_phoff | Elf32_Off | 4 | 程序头表(Program Header Table)在文件中的偏移量(目标文件可能为 0) |
e_shoff | Elf32_Off | 4 | 节头表(Section Header Table)在文件中的偏移量 |
e_flags | Elf32_Word | 4 | 处理器特定标志(多数架构为 0) |
e_ehsize | Elf32_Half | 2 | ELF 头自身的大小(32 位为 52 字节,64 位为 64 字节) |
e_phentsize | Elf32_Half | 2 | 程序头表中每个条目的大小(32 位为 32 字节,64 位为 56 字节) |
e_phnum | Elf32_Half | 2 | 程序头表的条目数量(目标文件可能为 0) |
e_shentsize | Elf32_Half | 2 | 节头表中每个条目的大小(32 位为 40 字节,64 位为 64 字节) |
e_shnum | Elf32_Half | 2 | 节头表的条目数量(即节的总数) |
e_shstrndx | Elf32_Half | 2 | 节名称字符串表(.shstrtab)在节头表中的索引(工具通过它找到节的名称) |
- 关键字段详解
e_ident:ELF 标识(16 字节) 这是 ELF 文件的 “身份证”,前 4 字节为魔数(Magic Number),固定为0x7f 45 4c 46(对应 ASCII 的DEL E L F),用于快速验证是否为 ELF 文件。 剩余 12 字节描述文件属性,例如:- 第 4 字节:
EI_CLASS(文件位数),1=32 位,2=64 位; - 第 5 字节:
EI_DATA(字节序),1= 小端序(如 x86),2= 大端序(如 PowerPC); - 第 6 字节:
EI_VERSION(版本,固定为 1)。 示例(32 位小端序 ELF 文件的e_ident前 6 字节):0x7f 0x45 0x4c 0x46 0x01 0x01
- 第 4 字节:
e_type:文件类型 常见值:ET_REL(1):可重定位文件(.o);ET_EXEC(2):可执行文件(如 a.out);ET_DYN(3):共享库(.so)或位置无关可执行文件(PIE)。
e_entry:程序入口地址 可执行文件加载到内存后,CPU 从该地址开始执行。例如,C 程序的入口并非main,而是动态链接器初始化后的_start函数地址。e_shoff与e_phoff:节头表与程序头表的偏移e_shoff:从文件开头到节头表的字节偏移(工具通过它找到节的 “目录”);e_phoff:从文件开头到程序头表的字节偏移(仅可执行文件 / 共享库有效,用于加载器映射内存段)。
e_shstrndx:节名称字符串表索引 节头表中每个节的名称存储在.shstrtab节中,e_shstrndx记录该节在节头表中的索引(例如,若值为 8,则第 8 个节头对应.shstrtab)。 文件开头几个字节称为魔数,通常用来确定文件的类型或格式。在加载或读取文件时,可用魔数确认文件类型是否正确。
仅 ELF 头在文件中具有固定位置,即总是在最开始的位置,其他部分的位置由 ELF 头和节头表指出,不需要具有固定的顺序。
可以通过
readelf -h对 ELF 头进行解析,见 编译文件解读

节
“节” 是 ELF 文件中具有相同功能的二进制数据块。可重定位文件的节按功能可分为代码与数据节、符号与字符串表节、重定位节和辅助节四大类,每类节都服务于 “链接过程” 的特定需求。
一、代码与数据节:存储程序实体
这类节直接对应源代码中的代码和数据,是程序的核心逻辑载体,但地址尚未最终确定(需链接器重定位)。
| 节名称 | 类型(sh_type) | 功能描述 | 关键属性(sh_flags) |
|---|---|---|---|
.text | SHT_PROGBITS | 存储函数的机器指令(如 main 函数的二进制代码) | SHF_ALLOC(可加载到内存) + SHF_EXECINSTR(可执行) |
.data | SHT_PROGBITS | 存储已初始化的全局 / 静态变量(如 int a = 10) | SHF_ALLOC + SHF_WRITE(可写) |
.bss | SHT_NOBITS | 存储未初始化的全局 / 静态变量(如 int b;) | SHF_ALLOC + SHF_WRITE |
.rodata | SHT_PROGBITS | 存储只读数据(如字符串字面量 "hello"、const 变量) | SHF_ALLOC(不可写) |
.init / .fini | SHT_PROGBITS | 存储程序初始化 / 终止代码(如全局对象的构造 / 析构函数) | SHF_ALLOC + SHF_EXECINSTR |
特点:
- 地址字段(
sh_addr)为 0(尚未分配内存地址,由链接器最终确定); .bss节存储未初始化的全局变量和静态变量(如int g_var;或static float s_var;)。由于未初始化的值没有具体的值,所以不占用文件空间(sh_size记录大小,但文件中无数据,加载时由链接器分配全 0 空间)。仅为一个占位符,提高空间利用效率- 类型(
sh_type):SHT_NOBITS(特殊类型,表示 “无实际数据”)。 - 特点:
- 不占用文件磁盘空间:
.bss节仅在节头表中记录变量的大小(sh_size),但文件中不存储实际数据(节省磁盘空间)。 - 加载时分配内存:程序加载到内存时,加载器会为
.bss节分配连续内存,并初始化为全 0。 - 属性(
sh_flags):SHF_ALLOC(可加载到内存) +SHF_WRITE(可写,因为变量可被修改)。
- 不占用文件磁盘空间:
- 类型(
二、符号与字符串表节:链接器的 “符号字典”
可重定位文件包含完整的符号信息,用于描述文件内定义的符号(如函数、变量)和引用的外部符号(如库函数),是链接器解析符号依赖的核心依据。
| 节名称 | 类型(sh_type) | 功能描述 | 关联关系 |
|---|---|---|---|
.symtab | SHT_SYMTAB | 完整符号表:存储所有符号(包括本地符号、全局符号、外部符号) | 其 sh_link 指向 .strtab(符号名称来源) |
.strtab | SHT_STRTAB | 字符串表:存储 .symtab 中所有符号的名称(以 \0 结尾) | 无关联节,自身为字符串容器 |
.shstrtab | SHT_STRTAB | 节名称字符串表:存储所有节的名称(如 .text、.data) | 由 ELF 头的 e_shstrndx 索引指向 |
符号表(.symtab)的核心符号类型:符号表中的每个条目(Elf32_Sym 或 Elf64_Sym)描述一个符号,按 “作用域” 和 “定义性” 可分为:
- 本地符号:仅在当前
.o文件中可见(如静态函数、静态变量),st_info绑定属性为STB_LOCAL; - 全局符号:在当前
.o文件中定义,可被其他文件引用(如非静态全局函数 / 变量),绑定属性为STB_GLOBAL; - 外部符号:在当前
.o文件中引用,但定义在其他文件(如调用printf),绑定属性为STB_GLOBAL,st_shndx为SHN_UNDEF(未定义)。
示例:
main.o 中调用 printf 时,.symtab 会包含一个 printf 符号,类型为外部符号(SHN_UNDEF),链接器需从 libc.so 中找到其定义。
三、重定位节:解决 “地址占位” 问题
编译器生成 .o 文件时,无法知道外部符号(如 printf)的最终地址,因此会在代码中用 “占位符” 暂时表示。重定位节存储这些占位符的位置和修正规则,供链接器在链接时填充实际地址。
| 节名称 | 类型(sh_type) | 功能描述 | 关联关系 |
|---|---|---|---|
.rel.text | SHT_REL | 代码节重定位表:记录 .text 节中需要修正的地址(如调用外部函数的指令) | sh_info 指向 .text 节(被重定位的节),sh_link 指向 .symtab(符号来源) |
.rel.data | SHT_REL | 数据节重定位表:记录 .data 节中需要修正的地址(如全局指针变量指向外部符号) | sh_info 指向 .data 节,sh_link 指向 .symtab |
.rela.text / .rela.data | SHT_RELA | 带加数的重定位表(比 SHT_REL 多一个 addend 字段,用于复杂地址计算) | 关联关系同上 |
当链接器把目标文件合并时,.text .data 节的文件被合并后,一些指令引用的操作数、跳转指令位置、全局变量等信息需要修改:
.rel.text节- 背景:编译器生成
.o文件时,无法知道外部符号(如其他.o文件中的函数或库函数)的最终地址,因此会在代码中用 “占位符” 暂时表示。.rel.text就是这些占位符的 “修正清单”。 - 示例:
若代码中调用
printf,.text节中会有一条call printf指令,但printf的地址未知,.rel.text会记录该指令的偏移和对应的符号索引,链接器据此填充实际地址。
- 背景:编译器生成
.rel.data节- 应用场景:当全局变量是指针且指向外部符号时(如
int *p = &external_var;),p的值(external_var的地址)在编译时未知,需通过.rel.data记录修正信息。 - 示例:
代码
int *ptr = &global_from_other_o;中,ptr的初始值(global_from_other_o的地址)未知,.data节会存储一个占位符,.rel.data会记录该占位符的偏移和符号索引,链接器最终填充实际地址。
- 应用场景:当全局变量是指针且指向外部符号时(如
重定位条目的核心信息:每个重定位条目(Elf32_Rel 或 Elf64_Rel)包含:
r_offset:需要修正的位置在目标节中的偏移(如.text中调用printf的指令地址);r_info:低 8 位为重定位类型(如R_386_PC32表示 32 位 PC 相对寻址修正),高 24 位为符号索引(指向.symtab中对应符号,如printf)。
示例:
main.o 的 .rel.text 中会有一个条目,r_offset 指向 call printf 指令中存储偏移量的位置,r_info 指向 .symtab 中 printf 的符号索引,链接器据此计算并填充实际地址。
四、辅助节:支持编译与链接细节
这类节不直接参与代码执行,但记录编译过程中的辅助信息,帮助链接器或工具正确处理文件。
| 节名称 | 类型(sh_type) | 功能描述 |
|---|---|---|
.comment | SHT_PROGBITS | 存储编译器版本信息(如 GCC: (GNU) 11.2.0) |
.note | SHT_NOTE | 存储文件元数据(如编译时间、目标平台特性) |
.debug_*(如 .debug_info) | SHT_PROGBITS | 存储调试信息(供 gdb 使用,如变量类型、代码行号映射) |
.gnu.attributes | SHT_GNU_ATTRIBUTES | 存储 GNU 扩展属性(如编译器优化选项、架构特性) |
.line | SHT_PROGBITS | 存储源文件行号与 .text 节种机器指令的映射关系,供 gdb 使用 |
节头表
节头表(Section Header Table)是 ELF 文件中用于描述所有节(Section)信息的核心数据结构,相当于 ELF 文件的 “目录”。它存储了每个节的名称、类型、大小、位置、属性等关键信息,是链接器、加载器、调试器等工具解析 ELF 文件的 “导航图”。
- 位置:节头表在 ELF 文件中的偏移量由 ELF 头的
e_shoff字段指定(可通过readelf -h查看)。 - 组成:由多个节头(Section Header)组成,每个节头对应一个节(包括 “空节”)。
- 作用:提供所有节的元数据,工具通过节头表可快速定位和解析各个节的内容。
节头在 ELF 规范中定义为 Elf32_Shdr(32 位)或 Elf64_Shdr(64 位)结构体,核心字段如下(以 32 位为例):
| 字段名 | 类型 | 含义 | 关键作用 |
|---|---|---|---|
sh_name | Elf32_Word | 节名称在 “字符串表节” 中的偏移 | 例如:偏移对应 “.text”,则节名为 .text |
sh_type | Elf32_Word | 节的类型 | 区分节的功能(如代码节、数据节、符号表节) |
sh_flags | Elf32_Word | 节的属性 | 标记节是否可执行、可写、可读取(如代码节不可写) |
sh_addr | Elf32_Addr | 节加载到内存后的地址 | 可执行文件中有效,目标文件中为 0(未分配地址) |
sh_offset | Elf32_Off | 节在 ELF 文件中的偏移量 | 从文件开头计算,用于找到节的实际数据 |
sh_size | Elf32_Word | 节的大小(字节) | 描述节的实际数据长度 |
sh_link | Elf32_Word | 关联节的索引 | 例如:符号表节(.symtab)的 sh_link 指向字符串表节(.strtab) |
sh_info | Elf32_Word | 节的额外信息 | 例如:重定位节的 sh_info 指向被重定位的节(如 .text) |
sh_addralign | Elf32_Word | 节的内存对齐要求 | 例如:代码节需 4 字节对齐,此字段为 4 |
sh_entsize | Elf32_Word | 节中每个条目(entry)的大小 | 仅用于 “表类型节”(如符号表节,每个符号占固定大小) |
可以通过
readelf -S对节头表解析,见 编译文件解读
4.2.3 可执行目标文件格式
链接器将相互关联的可重定位目标文件中相同的代码和数据节 (如 .text 节、.rodata 节、.data 节和 .bss 节) 合并,以形成可执行目标文件中对应的节。因为相
同的代码和数据节合并后,在可执行目标文件中各条指令之间、各个数据之间的相对位置就可以确定,因而所定义的函数 (过程) 和变量的起始位置就可以确定,也
即每个符号的定义 (即符号所在的首地址) 即可确定,从而在符号的引用处可以根据确定的符号定义进行重定位。
可执行目标文件(ELF)的核心结构
ELF 可执行目标文件由 ELF 头、程序头表、节头表以及夹在程序头表和节头表之间的各个不同的节组成,如图 4.6 所示。与可重定位文件(.o)相比,可执行文件的结构更侧重运行时加载,其整体布局如下:
[ ELF头(Elf Header) ] → 描述文件整体信息(类型、架构、入口地址等)
[ 程序头表(Program Header Table) ] → 描述“段(Segment)”信息,供加载器映射内存
[ 节(Sections) ] → 实际存储代码、数据等内容(与.o文件的节类似但已重定位)
[ 节头表(Section Header Table) ] → 描述节信息(可选,主要用于调试)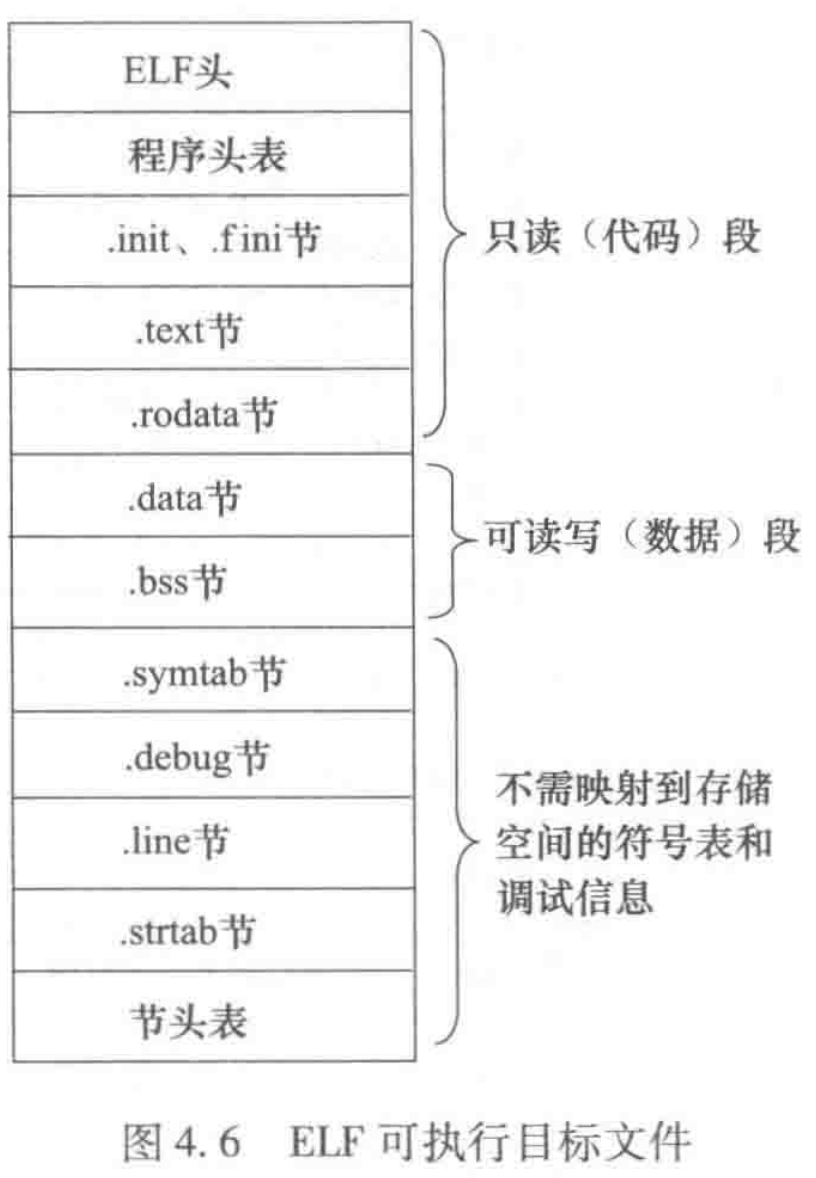
可执行文件格式与可重定位文件格式类似,例如,这两种格式中,ELF 头的数据结构一样 .text 节、.rodata 节和 .data 节中除了有些重定位地址不同以外,大
部分都相同,核心区别在于:可执行文件增加了程序头表,且所有节的地址已被链接器分配为内存中的实际地址。
与 ELF 可重定位目标文件格式相比,ELF 可执行目标文件的不同点主要有:
- ELF 头中字段
e_entry给出系统将控制权转移到的起始虚拟地址 (入口点),即执行程序时第一条指令的地址。而在可重定位文件中,此字段为 0。 - 通常情况下,会带有一个
.init节和一个.fini节,其中.init节定义了一个_init函数,用于可执行目标文件开始执行时的初始化工作,当程序开始运行时,系统会在进程进人主函数之前,先执行这个节中的指令代码。.fini节中包含进程终止时要执行的指令代码,当程序退出时,系统会执行这个节中的指令代码。 - 少了
.rel .text和.rel.data等重定位信息节。因为可执行目标文件中的指令和数据已被重定位,故可去掉用于重定位的节。 - 多了一个程序头表,也称段头表(segment header table),它是一个结构数组。
可执行目标文件中所有代码位置连续,所有只读数据位置连续,所有可读可写数据位置连续。如图 4.6 所示,在可执行文件中,ELF 头、程序头表、.init 节、.fini 节、.text 节和 .rodata 节合起来可构成一个只读代码段(read-onlycodesegment);.data 节和 .bss 节合起来可构成一个可读写数据段(read/writedata segment)。显然,在可执行文件启动运行时,这两个段必须装入内存且需要为之分配存储空间,因而称为可装入段。
程序头表
为了在可执行文件执行时能够在内存中访问到代码和数据,必须将可执行文件中这些连续的、具有相同访问属性的代码和数据段映射到存储空间 (通常是虚拟地址空间) 中,这就是程序头表的作用。
程序头表
程序头表是可执行文件的核心结构,是加载器(如操作系统内核)将文件映射到内存的依据。它是连接 ELF 文件与内存布局的关键桥梁,决定了程序加载到内存后的分段、权限和地址分布。
- 存在场景:仅在可执行文件(ET_EXEC)和共享库(ET_DYN)中存在,可重定位文件(.o,ET_REL)中通常不存在(
e_phoff=0)。 - 位置:由 ELF 头的
e_phoff字段指定(文件中的偏移量)。 - 组成:由多个程序头(Program Header) 组成,每个程序头对应一个段(Segment)。
- 作用:告诉加载器 “哪些内容需要加载到内存”“加载到什么地址”“具有什么权限(读 / 写 / 执行)”。
它由多个 “程序头” 组成,每个程序头描述一个段(Segment)。段是节的集合,按 “内存访问权限” 划分(加载器只关心内存权限,不关心具体节功能)。例如:
- 代码段(LOAD):包含
.text(代码)、.rodata(只读数据)等 “只读 / 可执行” 节; - 数据段(LOAD):包含
.data(已初始化数据)、.bss(未初始化数据)等 “可写” 节; - 动态链接段(DYNAMIC):包含动态链接所需的信息(如依赖的共享库)。
程序头的结构由 ELF 规范定义,32 位和 64 位格式分别对应 Elf32_Phdr 和 Elf64_Phdr 结构体,核心字段如下(以 64 位为例):
| 字段名 | 类型 | 含义与作用 |
|---|---|---|
p_type | Elf64_Word | 段的类型(决定段的功能,如可加载段、动态链接段等) |
p_flags | Elf64_Word | 段的内存权限(R= 读、W= 写、X= 执行,组合表示权限,如 R+X) |
p_offset | Elf64_Off | 段在 ELF 文件中的偏移量(从文件开头计算,用于定位段的内容) |
p_vaddr | Elf64_Addr | 段加载到内存后的虚拟地址(最终在内存中的位置) |
p_paddr | Elf64_Addr | 物理地址(通常与 p_vaddr 相同,仅嵌入式系统可能使用)通常无效,由操作系统决定 |
p_filesz | Elf64_Xword | 段在文件中的大小(字节,如代码和已初始化数据的实际大小) |
p_memsz | Elf64_Xword | 段在内存中的大小(字节,可能大于 p_filesz,如包含未初始化数据 .bss) |
p_align | Elf64_Xword | 段的内存对齐要求(必须是 2 的幂,如 8 字节对齐表示 p_align=8) |
可以通过
readelf -l对程序头表解析,见 编译文件解读
可重定位文件与可执行文件的节差异
可重定位文件(如 .o 目标文件)与可执行文件(如 Linux 下无后缀的可执行程序)的核心差异,体现在用途定位、地址状态、链接依赖、文件结构四个维度,具体差异如下表清晰对比:
| 对比维度 | 可重定位文件(Relocatable File) | 可执行文件(Executable File) |
|---|---|---|
| 核心用途 | 作为 “代码片段”,用于与其他目标文件(如多个 .o)链接合并,生成可执行文件或共享库 | 直接被操作系统加载到内存,由 CPU 执行具体功能(如运行程序) |
| 地址空间状态 | 地址未确定(使用 “相对偏移” 或 “符号引用”),无固定内存地址 | 地址已完全确定(包含 “加载地址”“执行地址”),符合操作系统内存布局 |
| 符号与链接 | 包含未解析符号(如引用其他 .o 中的函数 / 变量),需链接器(ld)处理符号重定位 | 无未解析符号,所有符号已绑定到具体内存地址,无需后续链接 |
| 文件结构特征 | 1. 程序头表(Program Header)可选(或仅基础信息); 2. 节头表(Section Header)完整(含 .text/.data/.rel 重定位节) | 1. 程序头表必须完整(描述 “如何加载到内存”,如 LOAD 段); 2. 节头表可选(执行时无需,调试时才需要) |
| 操作系统交互 | 无法被操作系统直接加载执行,需先经链接器处理 | 可被操作系统加载器(如 /lib64/ld-linux-x86-64.so.2)识别,加载到内存后直接执行 |
| 典型文件后缀 | Linux 下为 .o(目标文件),Windows 下为 .obj | Linux 下无固定后缀(如 ls/bash),Windows 下为 .exe |
文件结构差异体现:
| 对比维度 | 可重定位文件(.o) | 可执行文件(ELF) | 核心结构差异说明 |
|---|---|---|---|
| 文件类型标识 | ELF 头中e_type = ET_REL | ELF 头中e_type = ET_EXEC或ET_DYN(PIE) | 类型字段直接区分文件用途(ET_REL 表示待链接,ET_EXEC 表示可执行) |
| 程序头表 | 通常无(e_phoff = 0)或仅空表 | 必须存在(e_phoff ≠ 0) | 可执行文件通过程序头表描述段的内存映射(加载器依赖此表),.o 文件无需加载故无此表 |
| 节头表 | 完整且包含重定位节(.rel.text、.rel.data 等) | 可选(可能被 strip 命令移除) | .o 文件依赖节头表进行链接,可执行文件运行时无需节头表(仅调试时用) |
| 地址信息 | 所有节的sh_addr = 0(未分配内存地址) | 节和段的地址均为实际内存地址(非 0) | .o 文件地址为相对偏移,可执行文件地址由链接器分配,直接对应内存布局 |
| 代码与数据节 | .text、.data、.bss 等节独立存在 | 相同权限的节被合并为段(如.text+.rodata→代码段) | 可执行文件按内存权限合并节为段,提升加载效率;.o 文件保留独立节便于链接时重定位 |
| 符号表 | 包含未解析外部符号(如引用其他.o 的函数) | 符号表仅保留必要调试符号(无未解析符号) | .o 文件需符号表进行跨文件符号引用,可执行文件所有符号已绑定到具体地址 |
| 重定位信息 | 包含重定位节(.rel.*),记录需修正的地址 | 无重定位节(所有地址已由链接器修正) | .o 文件依赖重定位信息实现地址修正,可执行文件无需后续修正 |
| 入口地址 | ELF 头中e_entry = 0(无意义) | e_entry为程序启动地址(如 0x400500) | 可执行文件需明确入口地址供 CPU 启动,.o 文件为代码片段故无入口 |
| 动态链接信息 | 无(.dynamic 节为空或不存在) | 若为动态链接,包含.dynamic、.plt、.got 等节 | 可执行文件通过动态链接节加载共享库,.o 文件不直接处理动态依赖 |
总结:可重定位文件的结构围绕 “链接兼容性” 设计(保留独立节、重定位信息、完整符号表),而可执行文件的结构围绕 “内存加载与执行” 优化(合并为段、确定地址、包含加载指令),二者分别对应编译链路的 “中间产物” 和 “最终产物”。
4.2.4 可执行文件的存储器映像
对于特定的系统平台,可执行目标文件与虚拟地址空间之间的存储器映像(memory mapping) 是由 ABI 规范定义的。例如,对于 IA-32+Linux 系统,i386 System V ABI 规范规定,只读代码段总是映射到从虚拟地址为 0x8048000 开始的一段区域,可读写数据段映射到只读代码段后面按 4KB 对齐的高地址上,其中 .bss 节所在存储区在运行时被初始化为 0。运行时堆(run-time heap) 则在可读写数据段后面 4KB 对齐的高地址处,通过调用 malloc 库函数动态向高地址分配空间,而运行时用户栈(run-timeuser stack) 则是从用户空间的最大地址往低地址方向增长。堆区和栈区中间有一块空间保留给共享库目标代码,栈区以上的高地址区是操作系统内核的虚拟存储区。
图 4.8 展示了一个可执行文件 main对应的存储器映像。其中,左边为可执行文件 main 中的存储信息,右边为虚拟地址空间中的存储信信息。可以看出,可执行文件最开始长度为 0x004d4 的可装入段映射到从虚拟地址 0x8048000 开始的只读代码段;可执行文件中从 0x00f0c 到 0x01013 之间为 .data 节和 .bss 节 (实际上都是 .data 节信息,而 .bss 节不占磁盘空间),映射到从虚拟地址 0x8049000 开始的可读写数据段,其中 .data 节从 0x8049f0c 开始,共占 0x00108=264 字节,随后的 8 个字节空间分配给 .bss 节中定义的变量,初值为 0。
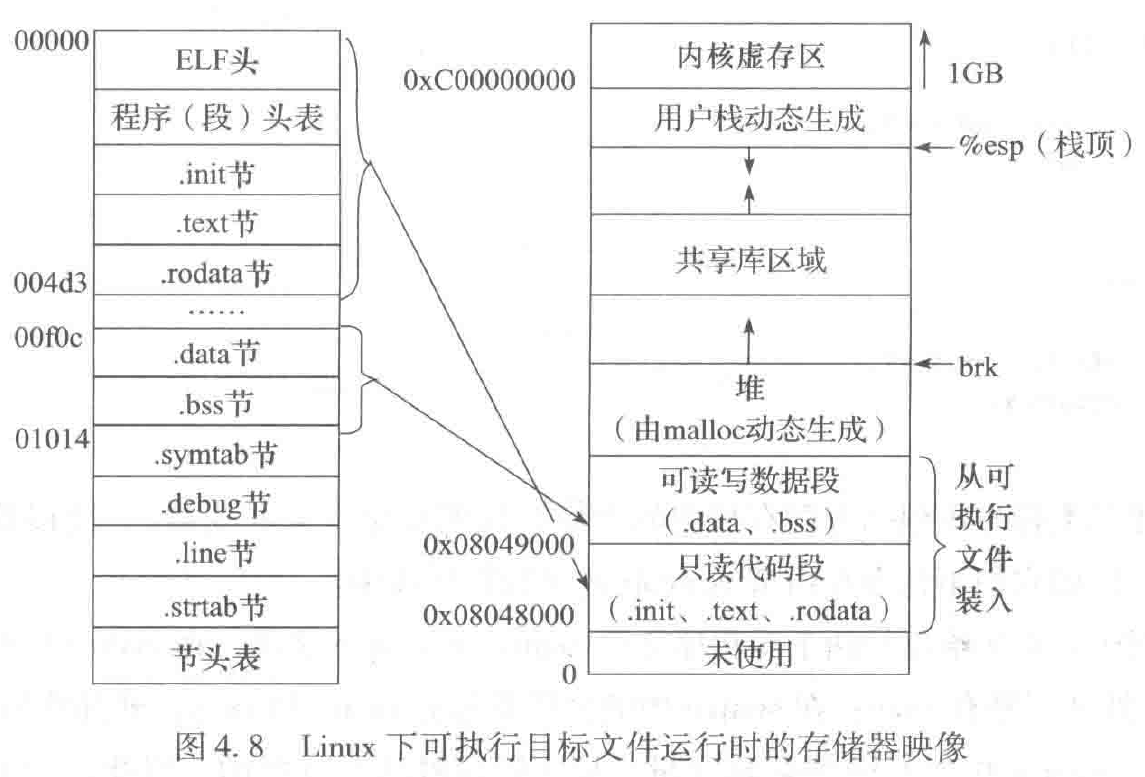
当启动一个可执行目标文件执行时,首先会通过某种方式调出出常驻内存的一个称为加载器(loader) 的操作系统程序来进行处理。例如,任何 UNIX 程序的加载执行都是通过调用 execve系统调用函数来启动加载器进行的。加载器根据可执行目标文件中的程序头表信息,将可执行目标文件中相关节的内容与虚拟地址空间中的只读代码段和可读写数据段通过页表建立映射,然后启动可执行目标文件中的第一条指令执行。
根据 ABI 规范,特定的系统平台中的每个可执行目标文件都采用统一的存储器映像,映射到一个统一的虚拟地址空间,使得链接器在重定位时可以按照一个统一的虚拟存储空间来确定每个符号的地址,而不用关心其数据和代码将来存放在主存或磁盘的何处。因此,引入统一的虚拟地址空间简化了链接器的设计和实现。
同样,引入虚拟地址空间也简化了程序加载过程。因为统一的虚拟地址空间映像使得每个可执行目标文件的只读代码段都映射到从0x8048000开始的一块连续区域,而可读写数据段也映射到虚拟地址空间中的一块连续区域,因而加载器可以非常容易地对这些连续区域进行分页,并初始化相应页表项的内容。IA-32中页大小通常是4KB,因而,这里的可装入段都按对齐。
加载时,只读代码段和可读写数据段对应的页表项都被支初始化为”未缓存页”(即有效位为0),并指向磁盘中可执行目标文件中适当的地方。因此,程序加载过程中,实际上并没有真正从磁盘上加载代码和数据到主存,而是仅仅创建了只读代码段和可读写数据段对应的页表项。只有在执行代码过程中发生了”缺页”异常时,才会真正王从磁盘加载代码和数据到主存。有关虚拟存储管理、虚拟地址空间、页表、缺页异常等相关内容见6.5节层次结构存储系统。
关于这个内存区域划分的详细解读,见程序的结构与运行。
符号表和符号解析
符号和符号表
符号解析
与静态库的链接
4. 重定位
重定位信息
重定位过程
4.5 动态链接
动态链接与静态链接
这是一个非常好的问题,它涉及到 C++ 程序的组织、编译和链接方式。我们来逐一解释。
1. 静态库 (Static Library) vs. 动态库 (Dynamic Library)
这两者是库文件(Library Files)的不同形式,它们包含了预先编译好的代码(函数、类等),供其他程序链接和使用。主要区别在于链接的时机和库代码的存放位置。
| 特性 | 静态库 (Static Library) | 动态库 (Dynamic Library) |
|---|---|---|
| 文件扩展名 | Windows: .lib Linux/macOS: .a (Archive) | Windows: .dll (Dynamic Link Library) Linux: .so (Shared Object) macOS: .dylib |
| 链接时机 | 编译时链接 (Link Time) | 运行时链接 (Run Time) |
| 链接过程 | 在编译你的程序时,链接器 (linker) 会将静态库中被用到的代码直接复制到你的最终可执行文件 (exe/out) 中。 | 你的可执行文件只包含一个引用(符号),指向动态库。程序运行时,操作系统动态链接器/加载器才将所需的动态库加载到内存,并建立连接。 |
| 可执行文件大小 | 较大,因为它包含了所有用到的库代码。 | 较小,因为它不包含库代码本身。 |
| 内存占用 | 多个使用同一静态库的程序运行时,每个程序都有一份库代码的副本,内存占用高。 | 多个程序可以共享同一份动态库在内存中的副本,节省内存。 |
| 更新库 | 更新库后,必须重新编译和链接所有使用该库的程序。 | 更新库文件(.dll, .so)后,只要接口不变,无需重新编译使用它的程序,重启程序即可使用新版本。 |
| 部署 | 只需分发可执行文件。 | 需要同时分发可执行文件和它所依赖的动态库文件。 |
| 启动速度 | 略快,因为代码已在可执行文件中。 | 略慢,因为需要加载和链接动态库。 |
| 依赖性 | 无外部库文件依赖。 | 有外部库文件依赖,如果库缺失,程序无法启动(“DLL Hell” 问题)。 |
| 示例 | libstdc++.a (GCC 的静态 C++ 标准库), libcmt.lib (MSVC 静态 C 运行时) | libstdc++.so (GCC 的动态 C++ 标准库), msvcp140.dll (MSVC 动态 C++ 运行时), kernel32.dll |
简单比喻:
- 静态库: 就像你写一篇文章时,把所有引用的段落都复制粘贴到了文章末尾。文章独立,但很长。
- 动态库: 就像你在文章里写了一个脚注,写着“详见《某本书》第 X 页”。文章本身很短,但需要那本书在手边才能完整阅读。 非常好的问题!这涉及到实际开发中的决策和底层机制。我们来详细解答。
如何确定该使用静态库还是动态库?
选择静态库还是动态库没有绝对的对错,取决于你的具体需求和场景。以下是关键的决策因素:
选择 静态库 (.a, .lib) 的场景
-
追求极致的独立性和部署简单性:
- 场景: 你需要分发一个独立的可执行文件,不希望用户安装任何额外的依赖库。
- 优点: 只需一个
.exe文件,用户双击即可运行,避免了“DLL Hell”(依赖库缺失或版本冲突)。 - 例子: 小型工具软件、嵌入式系统、某些游戏发行版。
-
性能敏感,且希望最小化运行时开销:
- 场景: 对启动时间和函数调用速度有极致要求,且库代码不会被多个程序共享。
- 优点: 消除了动态链接的加载和符号解析开销。函数调用是直接的,没有间接跳转。
- 注意: 现代动态链接器优化得很好,这种差距通常很小。
-
库非常小,或使用频率极低:
- 场景: 你有一个小的、特定功能的库,只有你的一个程序使用。
- 优点: 避免了管理一个独立的
.dll/.so文件的麻烦,即使它被复制到可执行文件中也增加不了多少体积。
-
避免动态库版本管理的复杂性:
- 场景: 你无法控制目标环境,或者不希望因为系统更新了某个动态库而导致你的程序行为改变或崩溃。
- 优点: “冻结”了库的版本,程序行为完全确定。
选择 动态库 (.so, .dll, .dylib) 的场景
-
代码共享和节省内存:
- 场景: 多个应用程序(或同一程序的多个实例)都需要使用同一个库。
- 优点: 操作系统可以将库的代码页在内存中共享,显著减少整体内存占用。这是操作系统级库(如 C/C++ 运行时、GUI 库)几乎总是动态库的主要原因。
-
模块化和插件架构:
- 场景: 你想实现一个支持插件的程序,或者希望将大型程序拆分成独立的模块,可以独立更新。
- 优点: 可以在程序运行时动态加载 (
dlopen/LoadLibrary) 和卸载库。更新某个模块(如一个插件)时,只需替换对应的.dll/.so文件,无需重新编译主程序。 - 例子: Web 浏览器插件、图像处理软件的滤镜、游戏模组。
-
减小可执行文件体积:
- 场景: 你的程序很大,或者分发带宽/存储空间是瓶颈。
- 优点: 可执行文件本身很小,库文件可以单独下载或预装。
-
热更新 (Hot Update):
- 场景: 服务器程序需要在不中断服务的情况下更新某些功能模块。
- 优点: 可以卸载旧的动态库模块,加载新的模块,实现功能更新。
-
遵守许可协议:
- 场景: 你使用的第三方库要求以动态链接方式分发(例如,某些 LGPL 许可的库)。
- 优点: 避免将你的专有代码与该库的代码“静态链接”在一起,从而可能避免你的整个程序也必须开源。
决策流程图 (简化):
你的库会被多个程序使用吗? -- 是 --> 强烈推荐 **动态库**
|
否
|
你的程序需要独立分发,不希望有外部依赖吗? -- 是 --> 推荐 **静态库**
|
否
|
你希望实现插件或模块热更新吗? -- 是 --> 必须 **动态库**
|
否
|
性能/内存/体积哪个是首要瓶颈? --> 内存/体积优先 --> **动态库**
--> 性能/独立性优先 --> **静态库**
printf, scanf, fopen 和 C++ 标准库到底是静态还是动态链接?
这完全取决于你的编译器、编译选项和目标平台。没有一个固定的答案。
如何确定?
-
查看编译器/链接器选项:
- GCC / Clang (Linux/macOS):
- 默认通常是动态链接到
libc(C 库) 和libstdc++(C++ 库)。 - 使用
-static选项会强制静态链接所有库(包括 C/C++ 运行时)。 - 使用
-static-libgcc -static-libstdc++可以只静态链接 C/C++ 标准库,而其他库(如系统库)仍动态链接。
- 默认通常是动态链接到
- MSVC (Visual Studio):
- 在项目设置中,可以配置 C/C++ 运行时库:
/MD或/MDd(Debug): 链接动态的多线程 C 运行时库 (msvcrt.dll/ucrtbase.dll等)。/MT或/MTd(Debug): 链接静态的多线程 C 运行时库 (libcmt.lib/libcmtd.lib)。
- C++ 标准库 (
std::vector,std::string等) 的动态/静态链接通常与 C 运行时库的设置保持一致。
- 在项目设置中,可以配置 C/C++ 运行时库:
- GCC / Clang (Linux/macOS):
-
检查生成的可执行文件:
- Linux/macOS: 使用
ldd <your_executable>(Linux) 或otool -L <your_executable>(macOS) 命令。如果输出中包含libc.so.6,libstdc++.so.6等,说明是动态链接。如果这些库不在列表中,很可能是静态链接(或被其他动态库间接依赖)。 - Windows: 使用
dumpbin /dependents <your_executable.exe>命令。如果输出中包含msvcr140.dll,vcruntime140.dll,ucrtbase.dll等,说明是动态链接。如果这些 DLL 不在依赖列表中,则很可能是静态链接。
- Linux/macOS: 使用
-
文件大小:
- 一个只调用了
printf的简单 “Hello World” 程序:- 动态链接: 可执行文件可能只有几 KB 到几十 KB。
- 静态链接: 可执行文件可能达到几百 KB 甚至上 MB(因为它包含了整个
libc的相关部分)。
- 一个只调用了
一般情况下的默认行为
- Linux: 绝大多数发行版和编译器默认使用动态链接。
libc(glibc或musl) 和libstdc++通常作为系统级动态库 (*.so) 存在。 - Windows: Visual Studio 的默认项目模板通常使用
/MD(动态链接)。这意味着printf等 C 函数和std::vector等 C++ 类的实现代码位于msvcpXXX.dll和vcruntimeXXX.dll等文件中,你的.exe文件在运行时需要这些 DLL。 - macOS: 类似于 Linux,通常使用动态链接,C/C++ 运行时是系统的一部分。
总结:
stdio.h 中声明的 printf 和 <vector> 中定义的 std::vector 的实现代码,在你编译程序时,要么被复制进你的可执行文件(静态链接),要么你的可执行文件保留一个引用,在程序启动时由操作系统加载对应的动态库文件(动态链接)。具体是哪种方式,由你的编译和链接命令决定。现代开发中,动态链接是更常见的默认选择,因为它能实现代码共享、节省内存和便于系统级更新。
编译文件解读
在 Linux 下对 C 程序编译过程中生成的 .o(目标文件)和 ELF(Executable and Linkable Format)文件进行分析,是理解程序结构、调试、逆向工程和性能优化的重要手段。以下是常用的分析工具、使用方法以及如何解读其输出。
一、核心工具概览
| 工具 | 用途 |
|---|---|
readelf | 分析 ELF 文件结构(头、节区、符号表等) |
objdump | 反汇编、查看节区内容、符号、重定位信息等 |
nm | 查看符号表(函数、变量等) |
size | 查看各节区大小 |
strings | 提取文件中的可打印字符串 |
hexdump / xxd | 查看二进制内容 |
file | 查看文件类型(是否为 ELF、动态/静态链接等) |
二、工具使用方法与解读
1. readelf:最强大的 ELF 分析工具
# 查看 ELF 头信息
readelf -h file.o
# 查看节区头表(Sections Header Table)
readelf -S file.o
# 查看程序头表(Program Header Table,仅可执行文件或共享库)
readelf -l a.out
# 查看符号表
readelf -s file.o
# 查看重定位信息(.o 文件中常见)
readelf -r file.o
# 查看动态链接信息(仅动态链接可执行文件或 .so)
readelf -d a.out解读示例:
-
readelf -h:Type: REL→.o文件(可重定位)Type: EXEC或DYN→ 可执行或共享库Machine: Advanced Micro Devices X86-64→ 架构Entry point address→ 程序入口地址(.o文件为 0)
-
readelf -S:.text:代码段.data:已初始化数据.bss:未初始化数据(占位,不占文件空间).symtab:符号表.strtab:字符串表.rel.text:代码段重定位信息(仅.o文件)
-
readelf -s:Num: 1:符号编号Value: 0x0000000000000000:符号地址(.o中相对)Size: 10:符号大小Type: FUNC或OBJECT:函数或变量Bind: GLOBAL或LOCAL:作用域Ndx: 1:所在节区编号(如 1 是.text)
注意:
.o文件中Value是相对地址,链接后才有绝对地址。
执行 readelf -h a.out,输出如下(节选 x86_64 系统结果):
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 # e_ident(魔数+属性)
Class: ELF64 # 64位
Data: 2's complement, little endian # 小端序
Version: 1 (current) # 版本
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file) # 可执行文件(e_type=2)
Machine: Advanced Micro Devices X86-64 # 架构(e_machine=62)
Version: 0x1
Entry point address: 0x400430 # 入口地址(e_entry)
Start of program headers: 64 (bytes into file) # e_phoff=64
Start of section headers: 4464 (bytes into file) # e_shoff=4464
Flags: 0x0
Size of this header: 64 (bytes) # e_ehsize=64(64位ELF头大小)
Size of program headers: 56 (bytes) # e_phentsize=56
Number of program headers: 9 # e_phnum=9
Size of section headers: 64 (bytes) # e_shentsize=64
Number of section headers: 31 # e_shnum=31
Section header string table index: 30 # e_shstrndx=30(.shstrtab的索引)通过 readelf -S 命令可直接打印 ELF 文件的节头表,例如:
There are 12 section headers, starting at offset 0x1d0:
Section Headers:
[Nr] Name Type Address Off Size ES Flg Lk Inf Al
[ 0] NULL 0000000000000000 000000 000000 00 0 0 0
[ 1] .text PROGBITS 0000000000000000 000040 00001a 00 AX 0 0 1
[ 2] .data PROGBITS 0000000000000000 00005a 000000 00 WA 0 0 1
[ 3] .bss NOBITS 0000000000000000 00005a 000000 00 WA 0 0 1
[ 4] .comment PROGBITS 0000000000000000 00005a 00001c 01 MS 0 0 1
[ 5] .note.GNU-stack PROGBITS 0000000000000000 000076 000000 00 0 0 1
[ 6] .note.gnu.property NOTE 0000000000000000 000078 000030 00 A 0 0 8
[ 7] .eh_frame PROGBITS 0000000000000000 0000a8 000038 00 A 0 0 8
[ 8] .rela.eh_frame RELA 0000000000000000 000150 000018 18 I 9 7 8
[ 9] .symtab SYMTAB 0000000000000000 0000e0 000060 18 10 3 8
[10] .strtab STRTAB 0000000000000000 000140 00000c 00 0 0 1
[11] .shstrtab STRTAB 0000000000000000 000168 000067 00 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
D (mbind), l (large), p (processor specific)
test.o: file format elf64-x86-64输出解读
[Nr]:节的索引(从 0 开始,0 号为空节);Name:节名称(由sh_name和.shstrtab解析得到);Type:节类型(对应sh_type);Addr:内存地址(对应sh_addr);Off:文件偏移(对应sh_offset);Size:节大小(对应sh_size);Flg:节属性(对应sh_flags,如AX表示可执行 + 可加载);Lk/Inf:关联节索引(对应sh_link/sh_info);Al:对齐要求(对应sh_addralign)。
根据节头表地地址和偏移可以计算出整个内存布局,
节头表
节头表通过
[Nr](索引)唯一标识每个节,用Name(名称)、Type(类型)定义节的身份与功能,通过Off(文件偏移)、Size(大小)定位节在文件中的位置与规模,用Addr(内存地址)、Al(对齐)描述节加载到内存的地址与对齐要求,借Flg(属性)明确节的访问权限,再以Lk/Inf(关联索引)建立节间依赖关系,最终完整描述每个节的元数据及关联逻辑。
通过 readelf -l 命令可直接打印 ELF 文件的程序头表,例如:
Elf file type is DYN (Position-Independent Executable file)
Entry point 0x1020
There are 14 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
PHDR 0x000040 0x0000000000000040 0x0000000000000040 0x000310 0x000310 R 0x8
INTERP 0x0003b4 0x00000000000003b4 0x00000000000003b4 0x00001c 0x00001c R 0x1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
LOAD 0x000000 0x0000000000000000 0x0000000000000000 0x000608 0x000608 R 0x1000
LOAD 0x001000 0x0000000000001000 0x0000000000001000 0x000155 0x000155 R E 0x1000
LOAD 0x002000 0x0000000000002000 0x0000000000002000 0x0000bc 0x0000bc R 0x1000
LOAD 0x002e10 0x0000000000003e10 0x0000000000003e10 0x000200 0x000208 RW 0x1000
DYNAMIC 0x002e20 0x0000000000003e20 0x0000000000003e20 0x0001a0 0x0001a0 RW 0x8
NOTE 0x000350 0x0000000000000350 0x0000000000000350 0x000040 0x000040 R 0x8
NOTE 0x000390 0x0000000000000390 0x0000000000000390 0x000024 0x000024 R 0x4
NOTE 0x00209c 0x000000000000209c 0x000000000000209c 0x000020 0x000020 R 0x4
GNU_PROPERTY 0x000350 0x0000000000000350 0x0000000000000350 0x000040 0x000040 R 0x8
GNU_EH_FRAME 0x002004 0x0000000000002004 0x0000000000002004 0x000024 0x000024 R 0x4
GNU_STACK 0x000000 0x0000000000000000 0x0000000000000000 0x000000 0x000000 RW 0x10
GNU_RELRO 0x002e10 0x0000000000003e10 0x0000000000003e10 0x0001f0 0x0001f0 R 0x1
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .note.gnu.property .note.gnu.build-id .interp .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn
03 .init .text .fini
04 .rodata .eh_frame_hdr .eh_frame .note.ABI-tag
05 .init_array .fini_array .dynamic .got .got.plt .data .bss
06 .dynamic
07 .note.gnu.property
08 .note.gnu.build-id
09 .note.ABI-tag
10 .note.gnu.property
11 .eh_frame_hdr
12
13 .init_array .fini_array .dynamic .got .got.plt
./build/test: file format elf64-x86-64基础信息总览
| 核心属性 | 具体值 | 说明 |
|---|---|---|
| 文件类型 | DYN(PIE) | 兼具可执行文件与共享库特性,加载地址随机 |
| 入口地址 | 0x1040 | CPU 启动执行的地址,对应 .text 节的初始化代码(非 main) |
| 程序头数量 | 14 个 | 描述 14 个功能段,覆盖加载、链接、安全控制等需求 |
| 程序头表偏移 | 文件偏移 0x40(64 字节处) | 加载器先读取此表,再解析其他段 |
程序头表
程序头表中各个表项,通过Type定义段的功能类型,将文件从Offset开始FileSiz大小的内容,指定段加载到内存的虚拟地址VirtAddr开始的MemSiz,Flg限制访问权限、Align确保地址对齐,最终实现ELF文件段到内存的精准加载映射。
2. objdump:反汇编与结构分析
# 反汇编 .text 段
objdump -d file.o
# 反汇编所有可执行段(包括 .init, .plt 等)
objdump -D a.out
# 显示所有节区内容(十六进制 + ASCII)
objdump -s file.o
# 显示节区头部信息
objdump -h file.o
# 显示符号表
objdump -t file.o
# 显示重定位条目
objdump -r file.o解读示例:
-
objdump -d输出:0000000000000000 <main>: 0: 55 push %rbp 1: 48 89 e5 mov %rsp,%rbp 4: 48 83 ec 10 sub $0x10,%rsp- 地址是相对
.text起始的偏移 - 每行包含机器码(十六进制)和对应汇编指令
- 地址是相对
-
objdump -s:可查看.data、.rodata等节区的原始数据
3. nm:快速查看符号
nm file.o输出格式: 地址 类型 符号名
常见类型:
T:在.text段的全局符号(函数)t:局部函数D:已初始化全局变量d:已初始化局部静态变量B:未初始化全局变量(.bss)U:未定义符号(需要链接时解析,如printf)
示例:
0000000000000000 T main
U printf
4. size:查看内存布局大小
size file.o
size a.out输出:
text data bss dec hex filename
112 8 4 124 7c file.o
text:代码段大小data:已初始化数据bss:未初始化数据(运行时分配)dec:十进制总和hex:十六进制总和
5. strings:提取字符串
strings file.o
strings a.out常用于查找硬编码字符串、格式化字符串(如 %s)、调试信息等。
6. file:识别文件类型
file a.out
# 输出示例:
# a.out: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 3.2.0, not stripped7. hexdump / xxd:查看二进制
hexdump -C file.o | head -20
xxd file.o | head -20用于查看 ELF 文件的原始字节,理解文件格式(如 ELF 魔数 7f 45 4c 46)。
三、典型分析流程
假设你有一个 hello.c:
#include <stdio.h>
int global_init = 10;
int global_uninit;
void foo() {
static int local_static = 20;
printf("Hello\n");
}
int main() {
foo();
return 0;
}步骤 1:编译生成 .o 文件
gcc -c hello.c -o hello.o步骤 2:分析 .o 文件
# 查看符号
nm hello.o
# 输出:
# 0000000000000000 T foo
# 0000000000000014 T main
# 0000000000000004 D global_init
# 0000000000000008 b global_uninit
# 0000000000000004 d local_static.1706
# U printf
# 查看重定位
readelf -r hello.o
# 可看到对 printf 和 local_static 的重定位条目
# 反汇编
objdump -d hello.o步骤 3:链接生成可执行文件
gcc hello.o -o hello步骤 4:分析可执行文件
# 查看程序头(加载段)
readelf -l hello
# 查看动态链接依赖
readelf -d hello | grep NEEDED
# 查看入口点
readelf -h hello | grep "Entry point"四、关键概念总结
.o文件:可重定位文件(REL),包含符号表、重定位信息,等待链接。- ELF 可执行文件:包含程序头(Segment),用于加载到内存。
- 符号解析:链接器将
U符号(如printf)绑定到库中的定义。 - 重定位:调整地址引用,使代码能在正确地址运行。
五、进阶工具(可选)
gdb:调试时查看符号、内存、寄存器perf/gprof:性能分析(需编译时加-pg)strip:去除符号表(减小体积)ldd:查看动态库依赖
通过这些工具的组合使用,你可以深入理解 C 程序从源码到可执行文件的整个构建过程,对调试、优化和安全分析都极为有用。