计算机体系结构简介
作为计算机技术的基础,计算机体系结构数十年来经历了多次变革,近年摩尔定律(Moore’s law)和登纳德缩放定律(Dennard scaling)的失效、多处理器(multiprocessor)和领域专用体系结构(domain specific architecture,DSA)的发展,以及开源 RISC-V 指令集的兴起等诸多因素给计算机体系结构的未来带来了新的机遇和挑战。
在中央处理器(central processing unit,CPU)诞生的早期,复杂指令集计算机(complex instruction set computer,CISC)是主流的计算机,因为它可以用较少的指令(instruction)完成一些复杂的操作。但是随着指令集的发展,CISC 风格指令集的弊端也渐渐显现,具体如下:
- 在程序运行过程中存在着著名的“二八定理”,即程序中 80% 的指令只占所有指令类型的 20%,这使得 CISC 中定义的大量指令并不会经常用到,降低了 CISC 的指令编码空间的利用效率。
- CISC 中定义的那些并不常用的特殊指令让处理器的设计变得极为烦琐和复杂,大大增加了处理器的设计成本。
- CISC 指令集不利于处理器流水线(pipeline)的分割,从而限制了处理器性能的进一步提高。
体系结构定义
ISA
不同 ISA 的区别在于几个方面:
- 操作数来源
- 存储器寻址
- 寻址模式
- 操作数类型和大小
- 操作指令
- 指令编码
玄铁 C 910
玄铁 C910 采用了 RV64GC/GCV 基本指令集和 T-Head 性能增强指令集,主要面向对性能要求严格的高端嵌入式应用。玄铁 C910 处理器架构的主要特点如下:
- 同构多核架构,支持 1~4 个玄铁 C910 核可配置。每个玄铁 C910 核采用自主设计的微架构,并重点针对性能进行优化。
- 引入“3 发射 8 执行”的超标量架构、深度乱序流水线和多通道的数据预取等高性能技术。
- 集成片上功耗管理单元,支持多电压和多时钟管理的低功耗技术。玄铁 C910 核支持实时检测并关断内部空闲功能模块,从而进一步降低处理器的动态功耗。
- 拥有两级高速缓存结构,即基于哈佛架构一级高速缓存和共享的二级高速缓存。其中一级高速缓存支持 MESI(modified, exclusive, shared, invalid)一致性协议,二级高速缓存支持 MOESI(modified, owner, exclusive, shared, invalid)一致性协议。二级高速缓存支持 8 路组相联或 16 路组相联,以及可配置的错误检查纠正机制和奇偶校验机制。
- 支持私有中断控制器 CLINT(core-local interrupter)和公有中断控制器 PLIC。
- 支持自定义且接口兼容 RISC-V 的多核调试框架。
微架构
玄铁 C910 的架构层次分为多核子系统和核内子系统。多核子系统包含数据一致性接口单元(consistent interface unit,CIU)、二级高速缓存(简称 L2 Cache)、可配置的 AXI4.0 从设备接口、主设备接口单元、平台级中断控制器(platform-level interrupt controller,PLIC)、计时器;核内子系统主要包含指令提取单元(instruction fetch unit,IFU)、指令译码单元(instruction decode unit,IDU)、整型单元(integer unit,IU)、浮点单元(floatingpoint unit,FPU)、加载存储单元(load-store unit,LSU)、指令退休单元(instruction retireunit,RTU)、内存管理单元(memory management unit,MMU)和物理内存保护(physicalmemory protection,PMP)单元。玄铁 C910 的总体架构如图 1-17 所示。
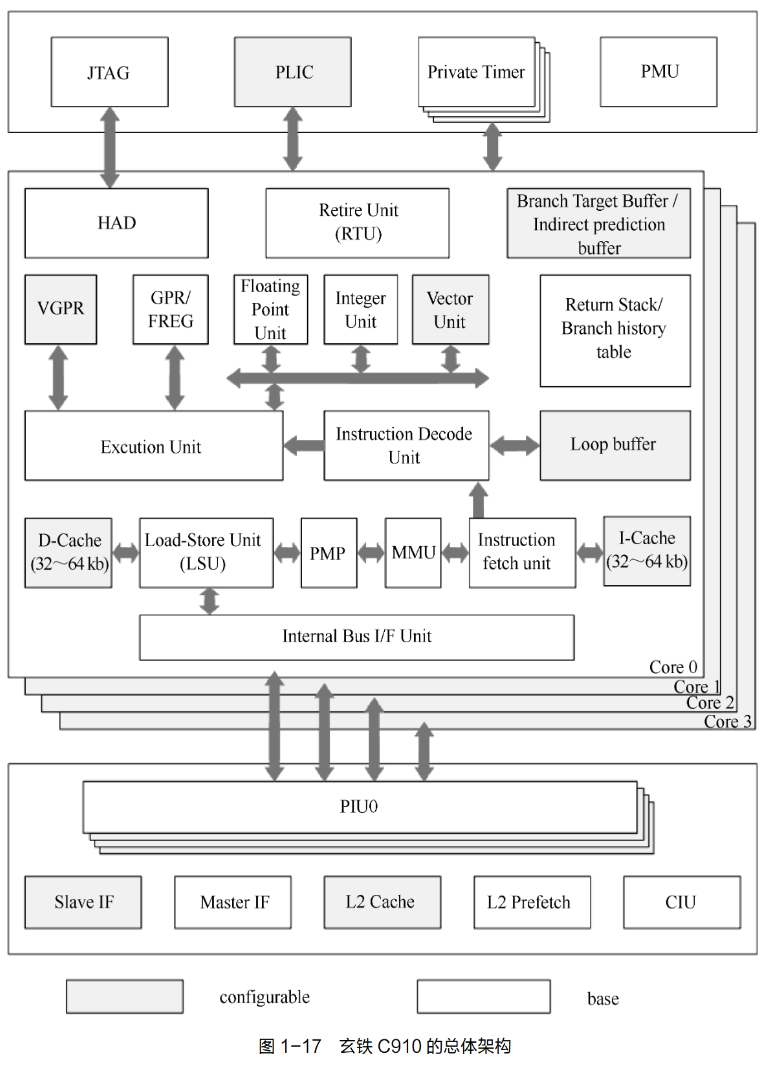
多核子系统
(1)CIU:CIU 采用 MOESI 的写失效协议维护各个一级数据高速缓存(简称 L1D-Cache)的一致性;CIU 通过一组处理器接口单元(processor interface unit,PIU)连接各个玄铁 C910 核,完成各类请求的接收和转换。该结构实现了 CIU 与各玄铁 C910 核的完全解耦,使玄铁 C910 核的数量可以被灵活配置。CIU 设置两路监听缓冲器,可并行处理多个监听请求,最大化地利用了监听带宽。并且,CIU 采用了高效的数据旁路机制,当监听请求命中被监听的 L1 D-Cache 时,直接将数据旁路传递给请求发起核。另外,CIU 支持地址转换后援缓冲器(translation lookaside buffer,TLB)和指令高速缓存(instructioncache,I Cache)无效操作请求的广播,降低了 TLB/I Cache 与 D Cache 数据一致性的软件维护成本。(2)L2 Cache:通过将 L2 Cache 与 CIU 紧耦合,实现了 L2 Cache 和 L1 D-Cache 的同步访问。L2 Cache 采用分块的流水线架构,每条流水线拥有独立的控制逻辑和随机存取存储器(random access memory,RAM)资源,单个周期可并行处理两个访问请求,最大访问带宽可达到 1024 位。L2 Cache 采用和玄铁 C910 相同的工作频率,因此 TAG RAM 和 DATA RAM 的访问延时可以通过软件配置;另外,L2 Cache 设置 16 个回填/牺牲缓冲器,可支持回填 16 条缓存行或 16 条牺牲缓存行的内存回写。
(3)从设备接口:采用可配置的 AXI 4.0 从设备接口,实现外设对 L1 D-Cache 和 L2Cache 的访问。接口支持 128 位的总线宽度,支持传输长度为 0 和 3 的 INCR(incrementingburst of undefined length)传输。第(4)主设备接口单元:主设备接口单元支持 AXI 4.0 协议,并支持关键字优先的地址 11 章访问,可以在不同的系统时钟与 CPU 时钟比例(1∶1 至 1∶8)下工作。计算机体系结构简介(5)PLIC:PLIC 支持最多 1023 个外部中断源采样和分发,支持电平和脉冲中断,可以设置 32 个级别的中断优先级。
(6)计时器:整个多核系统中的核心共用一个 64 位系统计时器。各个核心拥有私有的计时器比较值寄存器,并通过采集系统计时器的数值与软件设置的私有计时器比较值寄存器进行比较,产生计时器信号。
核内子系统
(1)IFU:IFU 一次最多可提取 8 条指令并对其并行处理。IFU 配备高速缓存,并在高速缓存缺失时采用关键指令预取和发射,以及采用后续指令旁路技术。IFU 可以开启指令高速缓存路预测技术,只访问两路指令高速缓存中大概率命中的一路,避免同时访问两路指令的高速缓存,以降低功耗。IFU 配备指令暂存器,用于缓存预取指令。IFU 还可选配循环加速缓存器,用于加速短循环取指操作;采用双峰指令分支跳转预测,实现了极高的预测精度;可选配间接分支预测器,对间接分支目标地址进行精准预测。整个 IFU 拥有低功耗、高分支预测准确率、高指令预取效率的特点。
(2)IDU:可以同时对 3 条指令进行译码并检测数据相关性。IDU 根据后级流水线执行情况,及时更新指令的数据相关性信息,并将指令乱序发送至下级流水线执行。IDU 支持指令的乱序执行调度,并通过随机发射降低因数据相关性造成的性能损失。(3)执行单元:包含 IU 和 FPU。整型单元包含若干算术逻辑单元(arithmetic and logicunit,ALU)、乘法单元(MULT)、除法单元(DIV)和跳转单元(BJU)。其中,ALU 执行标准的 64 位整数操作,大部分常用指令在单周期内产生运算结果,如加减、移位、逻辑运算等。ALU 通过操作数前馈改善数据冲突,单周期 ALU 指令不存在数据真相关的停顿延时。MULT 支持 16 位×16 位、32 位×32 位、64 位×64 位整数乘法。DIV 的设计采用了快速算法,占用 6~35 个执行周期位不等。BJU 可以在单周期内完成分支预测错误处理,提升处理器性能。FPU 包含若干个浮点算术逻辑单元(FALU)、一个浮点除法开方单元(FDSU)和两个浮点乘累加单元(FMAU),支持单精度、双精度运算。FALU 负责加减、比较、转换、寄存器传输、符号注入、分类等操作。浮点加减法、寄存器传输和符号注入指令可在 3 个周期完成;分类指令为跨流水线操作,需要 2 个周期完成;少部分跨流水线复杂指令被拆分成多条指令(如比较指令、转换指令等),这些指令的执行周期由拆分出的指令共同决定。FDSU 负责浮点除法、浮点开方等操作。FDSU 采用基 4 的 SRT 算法,执行周期为 5~32 不等。FMAU 负责普通乘法、融合乘累加等操作。普通乘法指令在第 4 个周期产生计算结果,融合乘累加指令在第 5 个周期产生计算结果。
(4)LSU:LSU 支持存储/加载指令的双发射及全乱序执行,支持高速缓存的非阻塞访问。LSU 具有内部前馈机制,消除了载入指令回写数据的相关性。支持字节、半字、字和双字的存储/载入指令,并支持字节和半字的载入指令的符号位扩展和零扩展。存储/加载指令可以流水执行,使得数据吞吐量达到每周期存取一个数据。LSU 还支持 8 路数据流预取技术,提高了存储/加载指令的 L1 D-Cache 命中率。
(5)RTU:RTU 包括一个重排序缓冲器与一个物理寄存器堆。其中,重排序缓冲器负责指令的乱序回收与按序退休,物理寄存器堆负责执行结果的乱序回收和传递。RTU 通过每个时钟周期并行退休 3 条指令与快速退休提高指令的退休效率。(6)MMU:MMU 依照 RISC-V SV39 标准,将 39 位虚拟地址转换为 40 位物理地址。o 玄铁 C910 MMU 在 SV39 定义的硬件回填标准的基础上,扩展了软件回填方式和地址属性。C 设计︵附微课视频︶(7)PMP:PMP 遵从 RISC-V 标准,支持配置 8 个或 16 个表项,最小粒度为 4KB,不支持 NA4 模式。