Ch 9 执行
9.1 概述
执行(Execution) 阶段负责指令执行,接收至指令的源操作数,功能单元(Function unit)对其进行规定操作,然后执行结果对处理器状态(Architecture State) 更新。一个处理器包括的 FU 的类型取决于这个处理器支持的指令集,一般 RISC 指令集包括以下操作类型:算术、访存、控制流、特殊指令。不同类型的指令有不同的复杂度,在 FU 中的执行时间也不同,称作 latency。现代处理器中为了获得更大并行度,一般会使用几个 FU 并行运算。不同 FU 有不同的延迟,FU 的个数决定了每个周期最大可以并行执行的指令个数,也就是前文所说的 issue width。FU 在运算完成后不会使用它的结果立马对处理器的状态进行更新,而是将结果写道临时的地方,比如不写到 ARF 而是 PRF,这些临时的状态称为推测状态(Speculative State),等到一条指令顺利离开流水线即退休的时候,它才会真正地对处理器对状态更新。
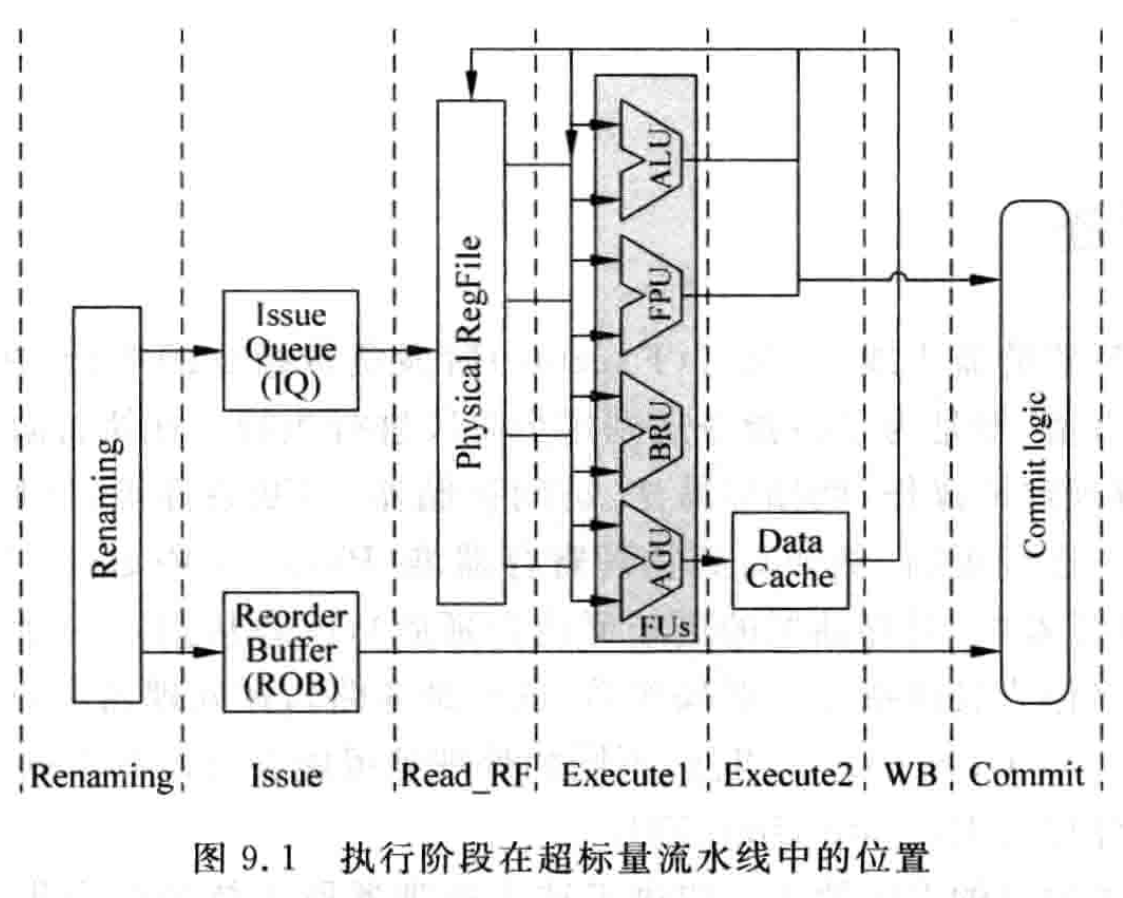
图中的执行阶段包括了所有类型的 FU,如 FPU Floating-Point unit 浮点运算/ALU Arthmetic Logic Unit 算术和逻辑运算/AGU Address Generation Unit 计算访存地址。当使用虚拟存储器时,AGU 计算的地址只是虚拟地址还需要转换为物理地址;BRU Branch Unit 对控制程序流的指令计算目标地址。当然实际还会有很多其他功能 FU。
执行阶段另一个重要部分就是旁路网络(bypassing network),负责将 FU 的运算结果马上送到需要的地方,如 PRF/FU 输入端/Store Buffer。现代超标量处理器中,如果想要背靠背地执行相邻的相关指令,旁路网络是必须的,但是算着并行执行的指令个数增多,旁路网络变得越发复杂,会在处理器中制约速度提升的关键部分。
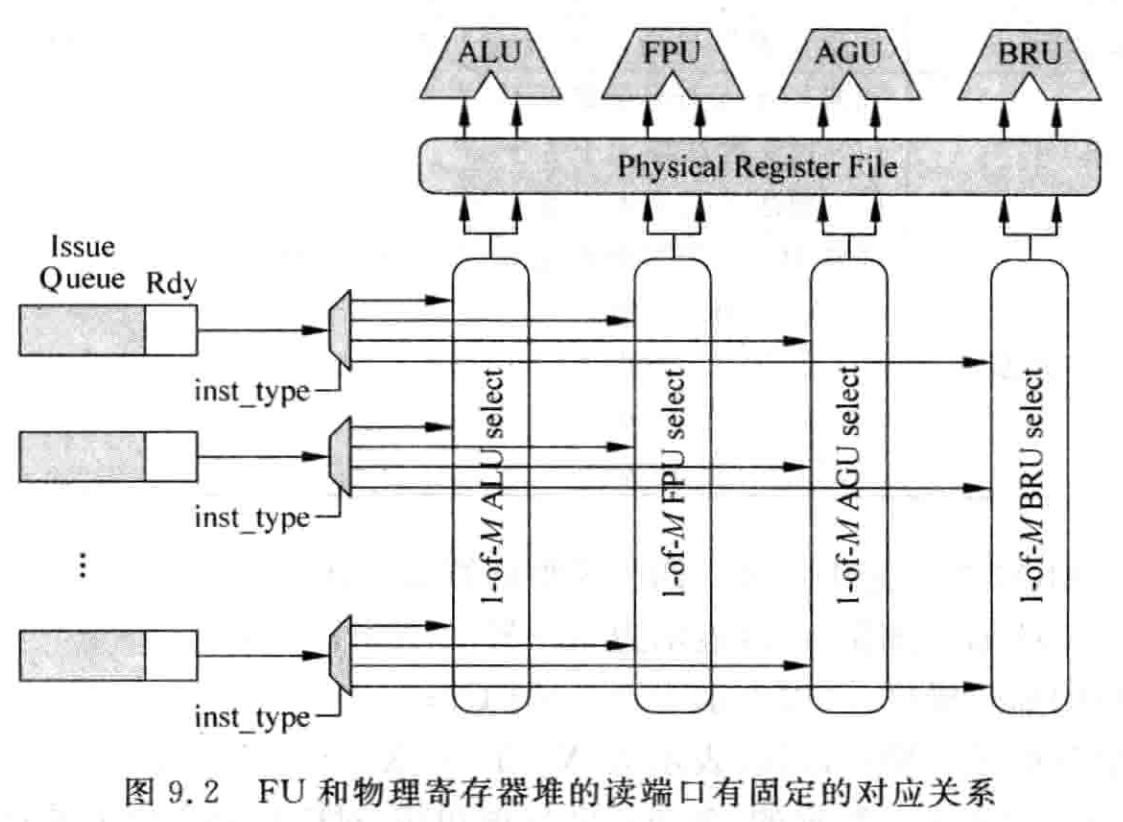
假设不考虑旁路网络,指令的操作数可以来自 PRF(对应非数据捕捉结构),也可以来自 payload RAM(对应看数据捕捉结构),每个 FU 和数据源的端口就是通过仲裁电路联系的。每个 FU 和一个 1-of-M 的仲裁电路一一对应。每个仲裁电路如果选择了一条指令,这条指令就会读取数据源,从而得到对应操作书,然后将这条指令送到对应 FU 中执行。每个仲裁电路、每个 FU 都和 PRF(payload RAM)一一对应。这样使设计得到简化。下图中 PRF 总共需要的读端口个数和 issue width 直接相关,如果追求更大的并行度,就需要更大的 issue width,PRF 也需要更多读端口(payload RAM 和 IQ 绑定,使用分布式 IQ 可以减少对 payload RAM 读端口的需求),又会制约处理器速度的提升。所以现代处理器为了解决矛盾,多采用 cluster 结构。
9.2 FU 的类型
9.2.1 ALU
这是一种最普通的 FU,所有的处理器都会有这个部件,它负责对整数类型的数据进行计算,得到整数类型的结果,它一般被称做 ALU (Arithmeticand LogicUnit)。整数的加减、逻辑、移位运算,甚至是简单的乘除法、数据传输指令,例如 MOV 指令和数据交换 (byte-swap) 类型的指令、分支指令的目标地址的计算、访问存储器的地址计算等运算,都会在这个 FU 中完成,具体的运算类型取决于处理器微架构 (microarchitecture) 的设计。
加减法是最普通的算术运算了,但是不同的指令集直接影响着加减法的硬件实现,例如在 MIPS 指令集中,如果加减法发生了溢出 (overflow),那么就需要产生异常 (exception),在异常处理程序中对这个溢出进行处理。而 ARM 指令集则直接定义了状态寄存器 (在 ARM 中称为 CPSR 寄存器),当加减法指令发生溢出时,会在 CPSR 中将相应的位置 1,后续的指令可以直接使用 CPSR 寄存器,从而可以不用产生异常。在 CPSR 寄存器中还包括了运算结果的其他状态位,如表 9.1 表示。
| 标志位 | 全称 | 条件 |
|---|---|---|
| N | Negative 标志位 | 等于 result[31],其中 result 表示运算的结果,通常用于有符号数的运算 |
| Z | Zero 标志位 | 如果运算结果为 0,则设为 1,否则为 0;通常用于比较两两个数是否相等 |
| C | Carry 标志位 | 通常用于无符号数的运算,其为 1 的条件是: (1) 加法的结果大于等于 232 (2) 减法的结果大于等于 0 |
| V | Overflow 标志位 | 通常用于有符号数的运算,其为 1 的条件是: (1) 正 + 正=负 (2) 负 + 负=正 (3) 负一正=正 (4) 正一负=负 |
相应的,在 ARM 指令集中定义了四种类型的算术操作。
- 不带进位的加法操作,可以表示为 ;
- 带进位的加法操作,可以表示为 C_{in};
- 不带借位的减法操作,可以表示为 ,在处理器内部都是采用二进制补码的形式来表达数据的,两个正常数据相减,对应到补码中就是这种加法运算;
- 带借位的减法操作,可以表示为 X - Y - 1 = X + (∼Y) + 1 - 1 = X + (∼Y)。
上面的四种运算可以使用一个普通的加法器,再配合一些控制逻辑就可以实现了,在实际的处理器中,是没有减法器的,都是使用加法器来实现减法的功能,如图 9.3 所示。
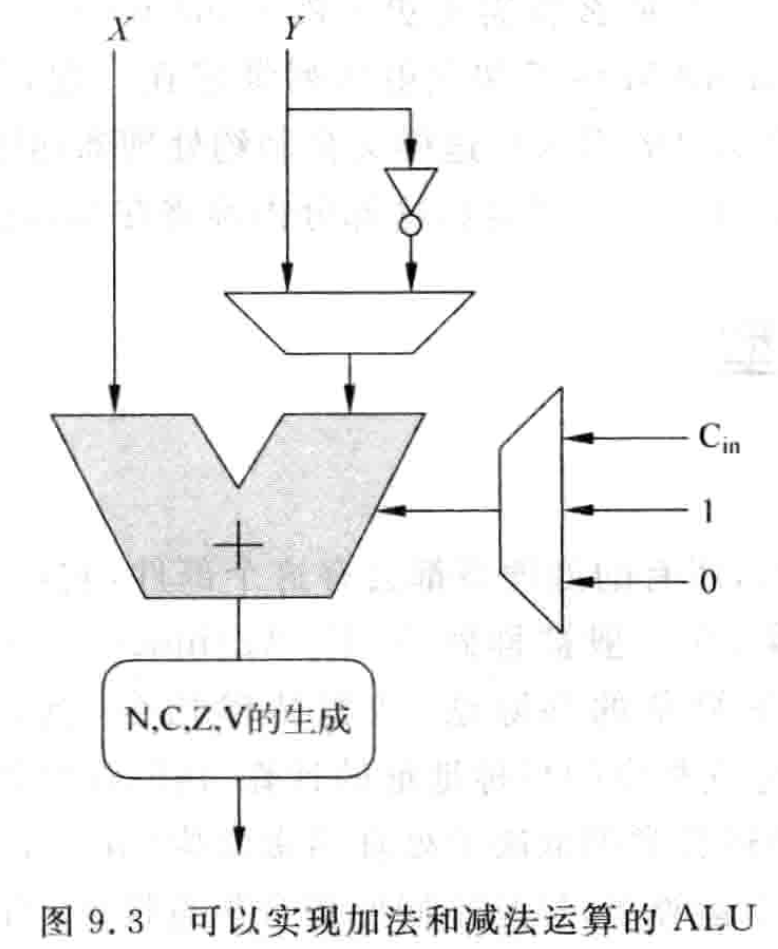
在表 9.1 中,当两个数做减法产生借位的时候(减法结果小于 0),借位标志位 C 是 0。之所以会发生这样的情况,是由于减法的硬件实现决定的,当借位确实存在时,带借位的减法实际上就是 ,由图 9.3 可以看出,要实现 的功能,借位 就需要为 0,也就是上一次的减法运算如果有借位,需要将 置为 0,这样下一次的减法运算才可以真正地将这个借位减掉。
一些处理器的 ALU 还实现了比较简单的乘除法功能,这些乘除法可能需要比较长的时间才可以完成,这里对于如何实现乘除法不再进行介绍。在 ALU 中加入乘除法操作后,会使 ALU 的执行时间是一个变化的值,例如执行普通的加减法指令需要一个周期,而执行乘除法需要 32 个周期,这样会给旁路(bypass)的功能带来一定的麻烦,在本章会进行详细的介绍。一个比较典型的 ALU 可能是图 9.4 所示的样子。
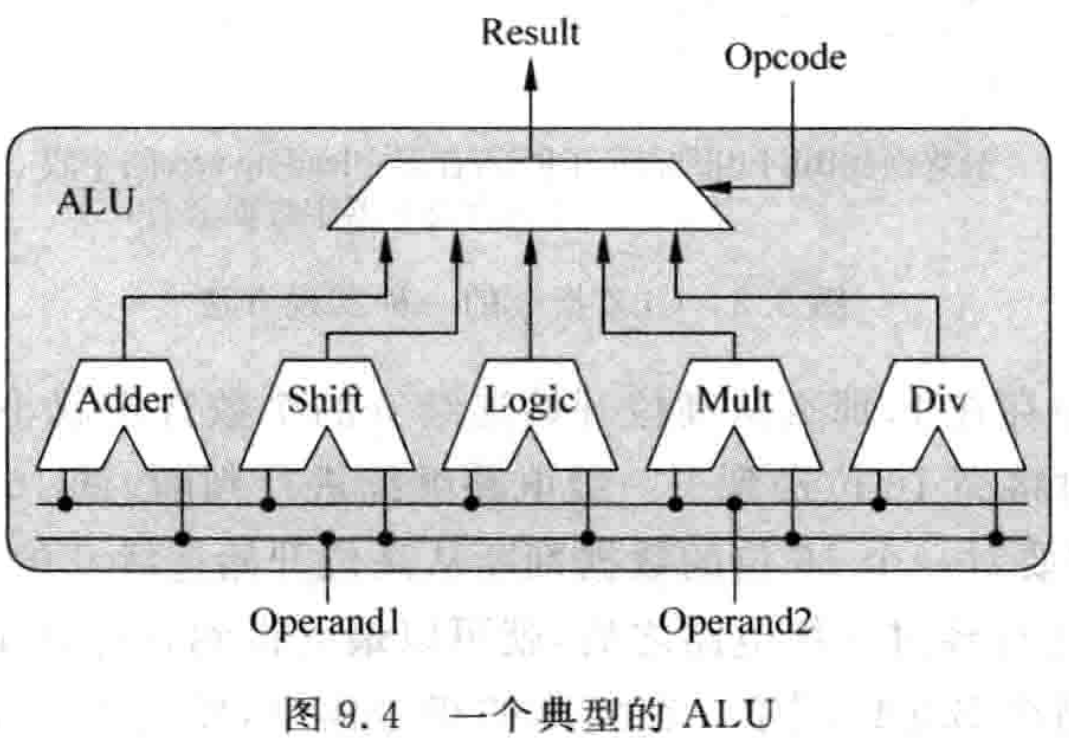
在图 9.4 中,ALU 中的所有计算单元都会接收到同一条指令的操作数,因此它们都会进行运算,最后需要根据这条指令的类型来选择合适的结果,由于一条指令只需要一个计算单元进行计算,但是实际上所有的计算单元都进行了运算,这样会浪费一部分功耗,可以在每个计算单元之前都加入寄存器来锁存指令的操作数,根据指令的类型来选择性地更新这些操作数寄存器,这样可以节省一定的功耗。
在 MIPS 指令集和 ARM 指令集中,还有一条比较特殊的指令 CLZ(Counting Leading Zero),用来判断一个 32 位的寄存器中。从最高位算起,连续的 0 的个数,在某些场合的应用中,例如任务优先级的判断,使用这种指令可以快速地获得结果,否则就需要使用软件来实现这个功能,浪费了时间和功耗,从这个角度来看的话,CLZ 指令可以理解为一条硬件加速指令。当然,要实现这条指令,需要消耗一定的硬件资源,图 9.5 给出了这条指令的一种实现方法。
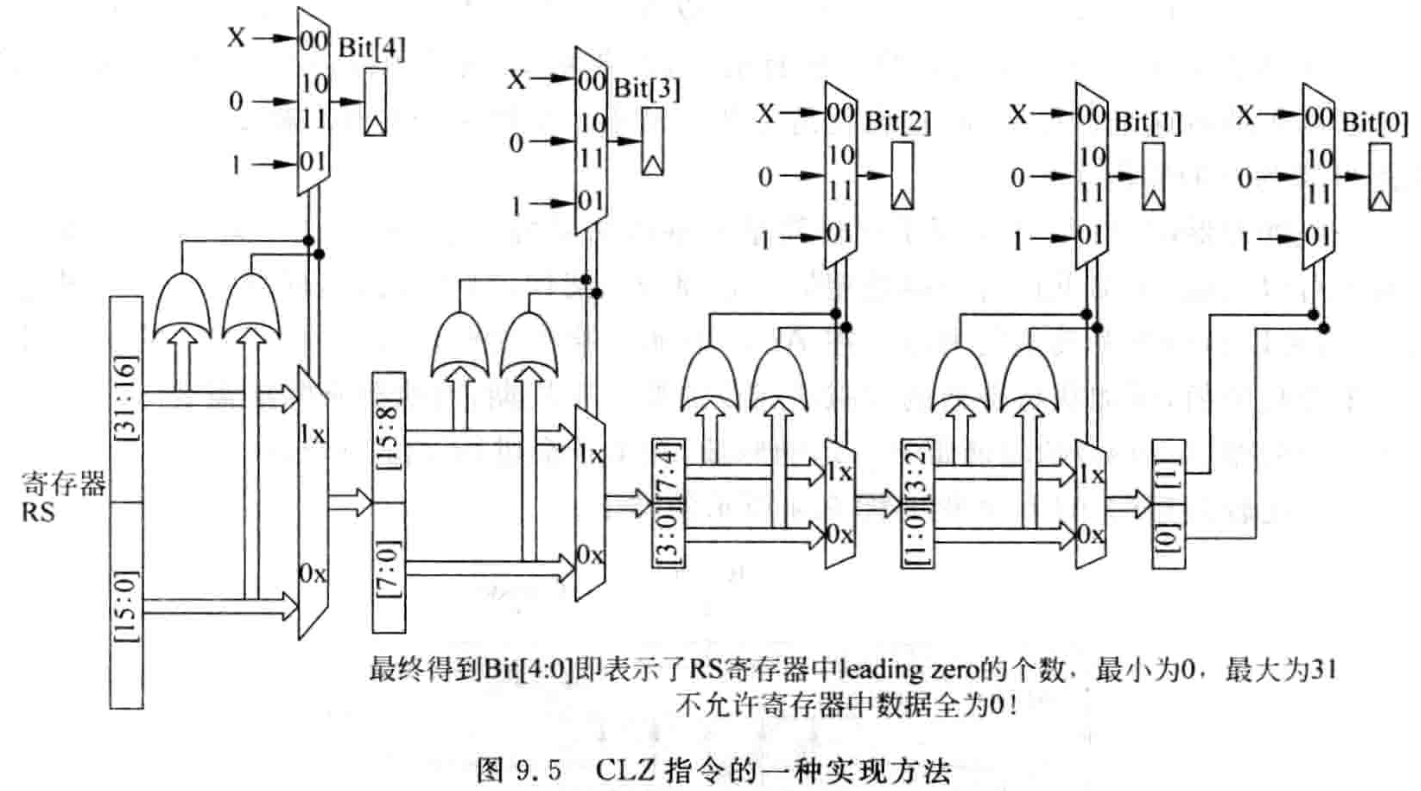
需要注意的是,CLZ 指令对于数据是有要求的,对于一个 32 位的寄存器 RS 来说,要使用 CLZ 指令,它其中的数据就不能够全为 0,这在 MIPS 指令集中进行了明确的定义。这需要在使用 CLZ 指令之前,使用一段小程序对数据进行判断,因此对于参与 CLZ 指令的寄存器 RS 来说,最多有 31 个 0,所以需要 5 位的数据才可以表达。图 9.5 使用了 Bit[4:0] 来表示寄存器中从高位开始连续 0 的个数,首先需要判断寄存器 RS 的高 16 位(RS[31:16])和低 16 位(RS[15:0])是否全为 0,如果高 16 位全是 0,则表示 RS 中从高位开始连续 0 的个数最少有 16 个,则将 Bit[4] 置为 1,此时需要将低 16 位送到后一级电路继续进行判断;而如果高 16 位中存在 1,那么从高位开始连续 0 的个数肯定就小于 16 个了,此时需要将 Bit[4] 置为 0,同时将高 16 位送到下一级电路继续进行判断,低 16 位此时就不需要考虑了。下一级电路就需要对一个 16 位的数据判断从高位开始连续 0 的个数,判断的过程和上一级电路是一样的,这样经过 5 级电路之后,就可以最终得到寄存器 RS 中从高位开始连续 0 的个数,并将其存储在 Bit[4:0] 中。在实际的指令集中,使用了一个通用的 32 位寄存器来记录这个结果,实际上只使用了这个寄存器的低 5 位,其余的 27 位并没有使用到。
在 MIPS 指令集中还有 CLO 指令(Counting Leading One),用来判断一个 32 位的通用寄存器中从高位开始连续的 1 的个数,这个指令实际上可以使用 CLZ 指令的硬件来实现,只需要将一个寄存器的内容全部按位取反,然后再使用图 9.5 所示的电路就可以实现了,所以在硬件上实现 CLO,是完全可以和 CLZ 共用一套硬件电路的,除非是要在每周期内并行地执行 CLZ 和 CLO 指令,此时才需要使用两套上述的硬件电路。
很多处理器在 ALU 中也实现了比较简单的乘法功能,用来支持乘法指令(大部分处理器不支持除法指令),当然,为了追求比较高的并行度,高性能的处理器都会选择将乘法器单独使用一个 FU 来实现,并且在这个 FU 中支持乘累加的功能,这样可以快速地执行指令集中乘累加类型的指令,例如 MIPS 中的 MADD 指令。有些处理器出于功耗和成本的考虑,会将整数类型的乘法功能在浮点运算的 FU 中完成(浮点运算必须有硬件乘法器),Intel 的 Atom 处理器就采用了这种方法。举例来说,如果要进行整数的乘法,首先需要将进行运算的操作数转换为浮点数,然后使用浮点运算 FU 中的乘法器进行乘法运算,最后将浮点的乘法结果转换为整数,这样就完成了两个整数的乘法运算,当然,这样肯定导致乘法指令需要的执行周期数(也就是 latency)变大,但是考虑到这种做法会节省面积(也就相当于节省了功耗),而且很多应用并不会使用太多的乘除法指令,所以这种方法也是一种可以接受的折中方案。
9.2.2 AGU
顾名思义,AGU(Address Generate Unit) 用来计算地址,访问存储器类型的指令(一般指 load/store 指令)通常会在指令中携带它们想使用的存储器地址,AGU 负责对这些指令进行处理,计算出指令中所携带的地址。其实,在普通流水线的处理器中,都是在 ALU 中计算这个地址,但是在超标量处理器中,由于需要并行地执行指令,而且访问存储器类型指令的执行效率直接影响了处理器的性能,所以单独使用了一个 FU 来计算它的地址。AGU 的计算过程取决于指令集,对于 x86 这样的复杂指令集的处理器,其访问存储器指令的寻址模式很复杂,所以它的 AGU 也相对比较复杂,而对于本书重点介绍的 RISC 指令集,访问存储器所需要的寻址模式很简单,例如对于 MIPS 处理器来说,load/store 指令的地址等于 ,其中 Rs 是指令携带的源寄存器,offset 是指令携带的立即数,AGU 只需要将两者进行加法运算就可以得到指令所携带的地址了。
如果处理器支持虚拟存储器,那么经过 AGU 运算得到的地址就是虚拟地址,还需要经过 TLB 等部件转化为物理地址,只有物理地址才可以直接访问存储器(在一般的处理器中,L2 Cache 以及更下层的存储器都是使用物理地址进行寻址的),因此在支持虚拟存储器的处理器中,AGU 只是完成了地址转换的一小部分,它只是“冰山的一角”,真正的“重头戏”是从虚拟地址转化为物理地址,以及从物理地址得到数据的过程(即访问 D - Cache)。这个过程直接决定了处理器的性能,尤其是对于 load/store 指令也采用乱序执行的处理器,需要一套复杂的硬件来检测各种违例情况,例如 store/load 违例或者 load/load 违例,并且还需要对它们进行修复,这些任务都增加了设计的复杂度,使访问存储器类型的指令成为了超标量处理器中最难以处理的指令,这部分内容涉及到 load/store 指令的相关性处理,在计算机的术语中称为 Memory Disambiguation,在本章会进行介绍。
9.2.3 BRU
BRU(Branch Unit) 负责处理程序控制流 (control flow) 类型的指令,如分支指令 (branch)、跳转指令 (jump)、子程序调用 (CALL) 和子程序返回 (Return) 等指令,这个 FU 负责将这些指令所携带的目标地址计算出来,并根据一定的条件来决定是否使用这些地址,同时在这个 FU 中还会对分支预测正确与否进行检查,一旦发现分支预测失败了,就需要启动相应的恢复机制。在 RISC 指令集中,程序控制流类型的指令是一种比较特殊的指令,因为它的目的寄存器是 PC,能够改变指令的执行顺序,对于 RISC 处理器的 PC 寄存器来说,它的来源有三种。
- 顺序执行时,next_PC = PC + N,N 等于每次取指令的字长。
- 直接类型的跳转时 (Direct),next_PC = PC + offset,offset 是指令所携带的立即数,它指定了相对于当前分支指令的 PC 值的偏移量,由于这个立即数不会随着程序的执行而改变,因此这种类型指令的目标地址是比较容易被预测的。
- 间接类型的跳转时 (Indirect),指令中直接指定一个通用寄存器 (例如 Rs) 的值作为 PC 值,next_PC = GPR[Rs],这种类型的指令也称作绝对跳转 (absolute) 类型的指令。由于随着程序的执行,通用寄存器的值会变化,所以这种类型指令的目标地址不容易被预测,如果可以使用直接类型的跳转指令实现同样的功能,就尽量不要使用这种间接类型的跳转指令。
如图 9.6 所示为 BRU 运算单元的实现原理图,这个 FU 其实主要完成了两部分工作,即计算分支指令的目标地址,并判断分支条件是否成立。
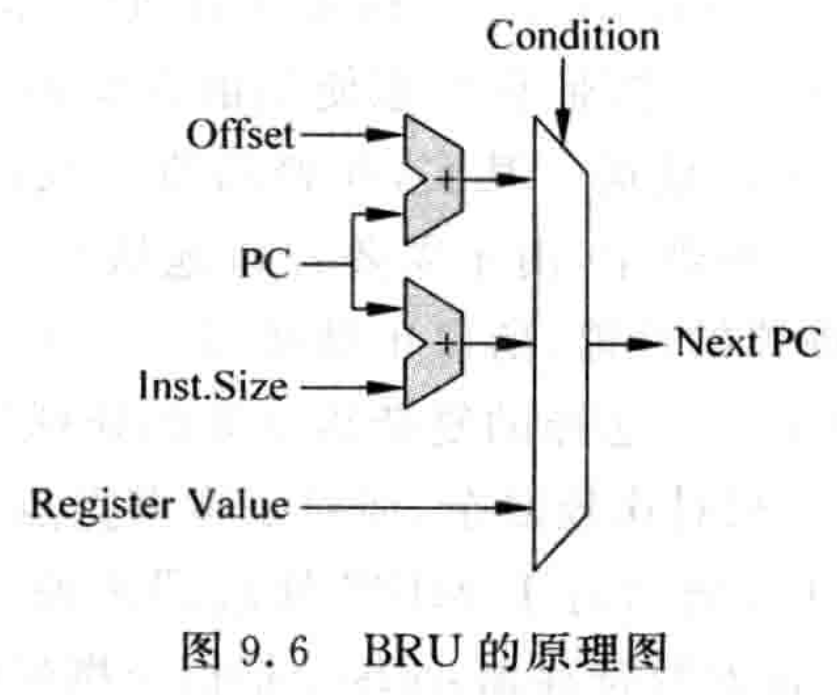
一般来说,分支指令可以分为两种,一种是有条件的,例如 MIPS 中的 BEQ 指令,另一种是无条件的,例如 MIPS 中的 J 指令。有条件的分支指令一般根据一个条件来决定是否改变处理器中的 PC 值,例如 MIPS 指令集中,一般在分支指令中都会携带一个条件,分支指令在执行的时候需要对这个条件进行判断,例如 BEQ 指令对两个寄存器是否相等进行判断,只有相等时才会跳转到指令所指定的目标地址;BLTZ 指令对寄存器的内容是否小于 0 进行判断,只有小于 0 时才会跳转到目标地址。
简而言之,MIPS 处理器使用了在分支指令执行的同时判断条件的方法,在 MIPS 指令集中,只有分支类型的指令才可以条件执行。而 ARM 和 PowerPC 等处理器则使用了不同的方法,在每条指令的编码中都加入了条件码(condition code),根据条件码的值来决定指令是否执行。因为每条指令都有这个条件码,所以每条指令其实都可以条件执行,而不仅限于分支类型的指令,这样相当于把程序中的控制相关性(control dependence)用数据相关性(data dependence)替代了,下面的例子如图 9.7 所示。
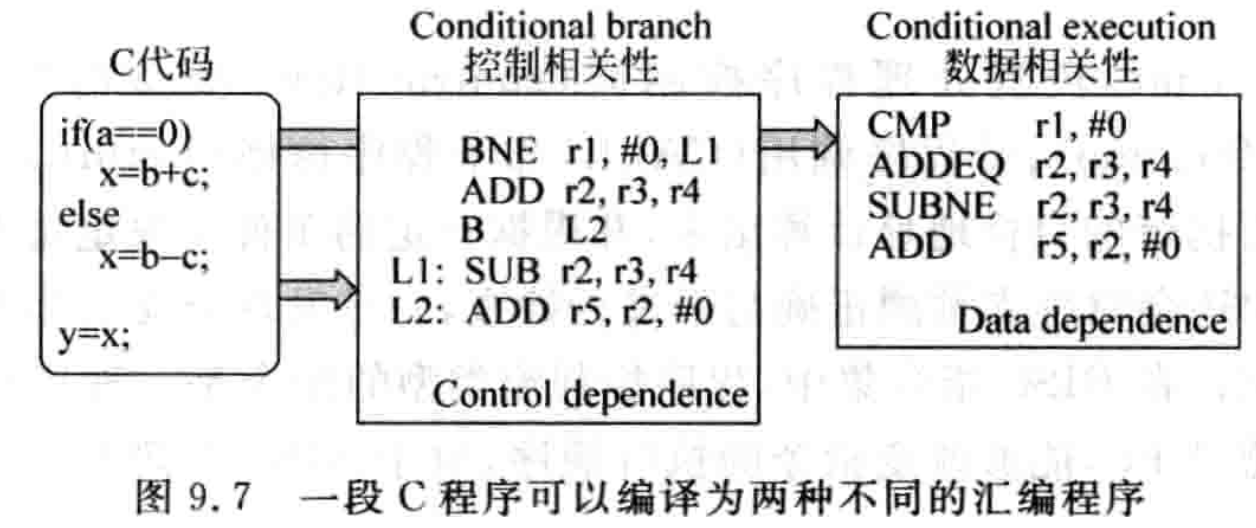
对每条指令都使用条件执行的好处是可以降低分支指令使用的频率,而在超标量处理器中,只要使用分支指令,就有可能存在预测错误的风险,因此从这个角度来看,这种条件执行的实现方式可以获得更好的性能,但是它也是一把双刃剑,因为条件码占据了指令编码的一部分,导致指令中实际可以分配给通用寄存器的部分变少了。例如在 ARM 处理器中,条件码占据了四位的空间,导致 ARM 只能使用 32 - 4 = 28 位的空间对指令进行真正的编码,所以 ARM 使用四位空间对通用寄存器进行编码,支持的通用寄存器个数也就是 16 个,而 MIPS 则是 32 个,更多的通用寄存器可以降低指令访问存储器的频率,也就增加了处理器的执行效率。而且,从上面的例子可以看出,使用条件执行会导致所有的指令都进入流水线中,当需要条件执行的指令很多时,流水线会存在大量无效的指令,这样反而使效率降低了,从这些角度来看,对每条指令都使用条件执行是降低了性能的。因此,孰优孰劣是很难有定论的,MIPS 处理器是最干净纯粹的 RISC 处理器,而 ARM 处理器是商业模式最成功的处理器,它们都是 RISC 阵营优秀的代表。
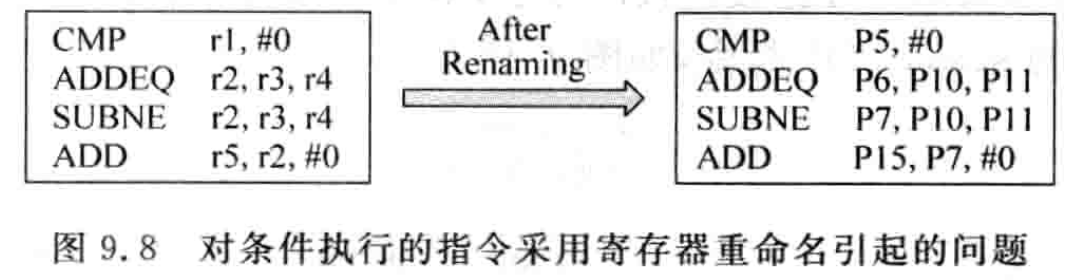
在超标量处理器中使用条件执行,会给寄存器重命名的过程带来额外的麻烦,仍以图 9.7 为例,按照正常流程对条件执行的代码进行重命名,会得到图 9.8 所示的结果。
9.2.4 其他 FU
在处理器中,还包括其他很多类型的 FU,例如处理器如果支持浮点运算,那么就需要浮点运算的 FU;很多处理器还支持多媒体扩展指令,例如单指令多数据(SIMD)类型的指令,则也需要相应的 FU 来处理它们,这些 FU 的架构和指令集是息息相关的。
9.3 旁路网络
一条指令经过 FU 计算之后,就可以得到结果了,但是由于超标量处理器中的指令是乱序执行的,而且存在分支预测,所以这条指令的结果未必是正确的,此时称这个计算结果是推测状态的 (speculative),一条指令只有在顺利地离开流水线的时候 (即退休的时候),才会被允许将它的结果对处理器进行更新,此时这条指令的状态就变为了正确状态 (在处理器中,这称为Architecture State),此时可能距离这个结果被计算出来已经很久了 (例如这条指令之前存在一条 D-Cache 缺失的 load 指令),后续的指令不不可能等到这条指令顺利地离开流水线的时候才使用它的结果,这样虽然能够保证正确确性,但是执行效率太低; 如果等到指令将结果写到物理寄存器堆之后 (假设采用统一的 PRF 进行重命名),后续相关的指令才从物理寄存器堆中读取数据,这样会提高一些执行效率,但是仍然不是完美的解决方法。事实上,一条指令只有到了流水线的执行阶段才真正需要操作数,到了执行阶段的末尾就可以得到它的结果,因此只需要从 FU 的输出端到输入端之间同架起一个通路,就可以将 FU 的结果送到所有 FU 的输入端。当然,在处理器内部的很多其其他地方可能也需要这个结果,例如物理寄存器堆、payloadRAM 等,因此需要将 FU 的结果也送到这些地方,这些通路是由连线和多路选择器组成的,通常被称为旁路网络 (bypassing network),它是超标量处理器能够在如此深的流水线情况下,可以背靠背执行相邻的相关关指令的关键技术。
其实,在所有的处理器中,为了获得指令背靠背的执行,旁路网络都是必需的,不管是普
通的标量处理器还是超标量处理器都是如此,如图 9.11 所示为在一个普通的标量处理器的
流水线中进行旁路 (bypass) 的示意图。

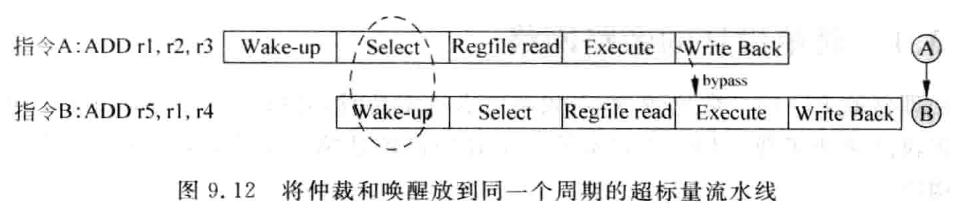
在超标量处理器中,流水线会变得比较复杂,但是在前文已经讲过,只要指令在被仲裁电路选中的那个周期,对发射队列中相关的指令进行唤醒的的操作,仍旧可以保证背靠背地执行相邻的相关指令,如图 9.12 所示。
在更现实的超标量处理器中,对于一条指令来说,它的源操作非数从物理寄存器堆中读出来后,还需要经过一段很长的布线,才能到达 FU 的输入端,而且 FU 的输入端还有大量的多路选择器,用来从不同的旁路网络 (bypassing network) 或者物理寄存器堆的输出中选择合适的操作数,因此为了降低对处理器的周期时间的影响,源操作数从物理寄存器堆读取出来后,还需要经过一个周期的时间,才能够到达 FU 的为输入端,这个周期在流水线中称为Source Drive 阶段。同理,FU 将一条指令的结果计算出来之后,还需要经过复杂的旁路网络才能到达所有 FU 的输入端 (或者 PRF 的输入端),因因此将这个阶段也单独做成流水线的一个阶段,称为Result Drive 阶段,此时的流水线如图 99.13 所示

由图 9.13 可知,只要保证在指令被仲裁电路选中的同一个周期,对发射队列中的相关指令进行唤醒的操作,则下一条指令在 FU 的输入端仍然可以从上一条指令的 Result Drive 阶段获得操作数,也能够实现背靠背的执行。当然,从图 9.13 还可以看出,如果从一个 FU 的输出端到另一个 FU 的输入端经过的时间很长,例如需要经过很长的布线,那么留给第二条指令的执行阶段 (Execute) 的时间就不多了,这样对处理器的周期时间就造成了负面的影响, 现代的很多处理器采用了Cluster的方法来解决这个问题, 在后文会进行介绍。
到现在可以知道,要使两条存在先写后读 (RAW) 相关性的相邻指令背靠背地执行,必须有两个条件,指令被仲裁电路选中的那个周期进行唤醒操作,还有就是旁路网络 (bypassing network)。在前文已经讲过,一个周期内进行仲裁我和唤醒的操作会严重地制约处理器的周期时间,而现在又引入了旁路网络,需要将 FU 的结果送到每个可能需要的地方,在真实的处理器当中,旁路网络需要大量的布线和多路选择器,已经成为现代处理器当中的一个关键的部分,它影响了处理器的面积、功耗、关键路径经和物理上的布局。但是尽管如此,现代的大多数处理器都实现了旁路网络,目的就是为了得更高的指令并行度。在超标量处理器中,如果不能够背靠背地执行相邻的相关指令,那么理论上来讲,硬件可以找到其他不相关的指令来填充这些空隙,但是这些不相关的指令不一定总是存在的,因此即使在超标量处理器这种硬件调度指令的情况下,背靠背地执行行相邻的相关指令仍然可以获得更好的性能。但是仍旧有少数例外的情况,例如 IBM 的 POWER4[39] 和 POWER5[40] 处理器,并没有实现旁路网络,这样可以使处理器获得很高的频率 (因为复杂度降低了),从而达到以快制胜的目的,在这样的处理器中,两条相邻的相关指令在执行的时候,它们之间会存在气泡 (bubble),但是这些气泡可以使用其他不相关的指令来代替,因为它们都是乱序执行的处理器,只要能够找到不相关的指令,就能够缓解这样的设计对性能的负面影响。
9.3.1 简单设计旁路网络
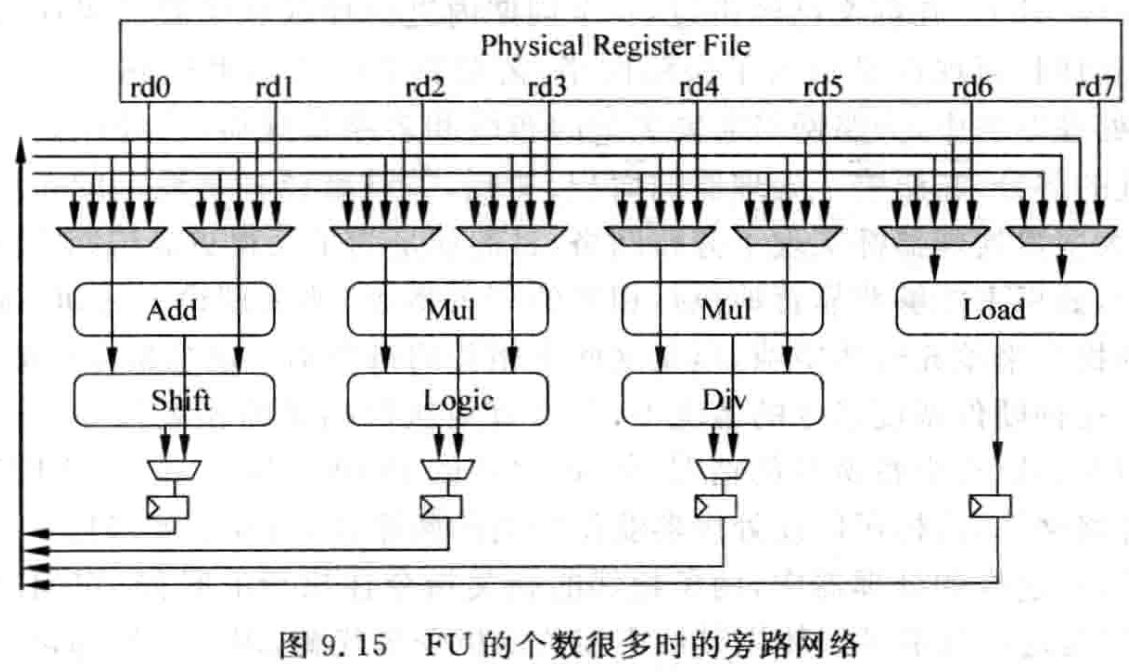
当处理器的FU的个数比较少,对频率要求也不高时,旁路路网络(bypassingnetwork)可以相对比较简单地实现,图9.14表示了一个处理器包括两个FU时,实现和不实现旁路网络的结构图。
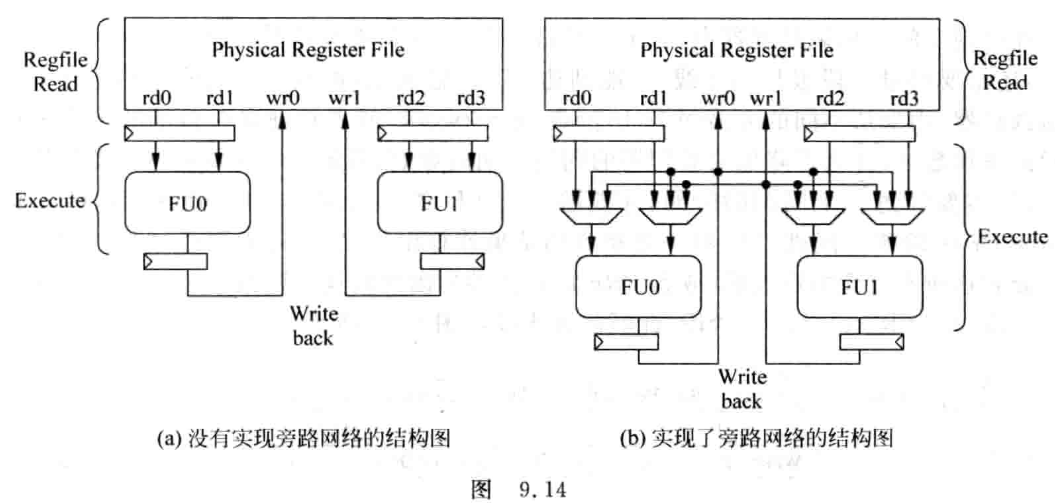
图9.14所示的两幅图,其实对应着上一节讲过的简单流水线 (IF、ID、EX、MEM、WB), 图9.14 (a) 表示了不实现旁路网络的示意图, FU的操作数直接来自于物理寄存器堆, FU的结果也直接送到物理寄存器堆中, 一个FU想使用另一个FU的计算结果只能通过物理寄存器获得; 图9.14 (b) 表示了实现旁路网络的设计, 每个FU的操作数可以有三个来源, 即物理寄存器、自身FU的结果、其他FU的结果, 因此FU的每个操作数都需要一个3:1的多路选择器进行选择, 同时, 每个FU的输出除了送到牛物理寄存器堆之外, 还需要通过一个总线送到所有FU输入端的多路选择器中。由图9.14可以看出, 在只有两个FU的比较简单的处理器中加入旁路网络, 已经增加了设计的复杂度, 可以想象, 当FU的个数比较多时, 就会出现如图9.15所示的样子。