Ch8 发射
8.1 概述
发射(issue) 就是将符合一定条件的指令从发射队列(Issue Queue, IQ) 中选出来,送到 FU 的过程。对于一个 4-way 的超标量处理器来说,在寄存器重命名阶段可以同时处理四条指令,重命名后的指令被写到 ROB 的同时也被写到发射序列,这时到达了发射阶段。发射队列也可叫做保留站(Reservation Station, RS)。对于 in-order 处理器,指令按原有顺序写入,此时 IQ 相当于 FIFO;对于 OoO,只有少数指令按照这种方式执行,大多都是乱序的。
指令到了 IQ,不会按照程序中的顺序,只要操作数准备好了且满足发射条件就可以送到相应 FU 中去执行。因此发射队列的作用就是使用硬件保存一定数量的指令,然后从这些指令中找出可以执行的指令。IQ 的好坏决定了处理器可以获得的并行度,硬件设计比较复杂,而且它的时序一般都在关键路径上,影响处理器的周期时间。
发射阶段是处理器从顺序指令到乱序执行的分界线,由一些列硬件组成,除了 IQ 用来存储所有等到调度的指令,还有:
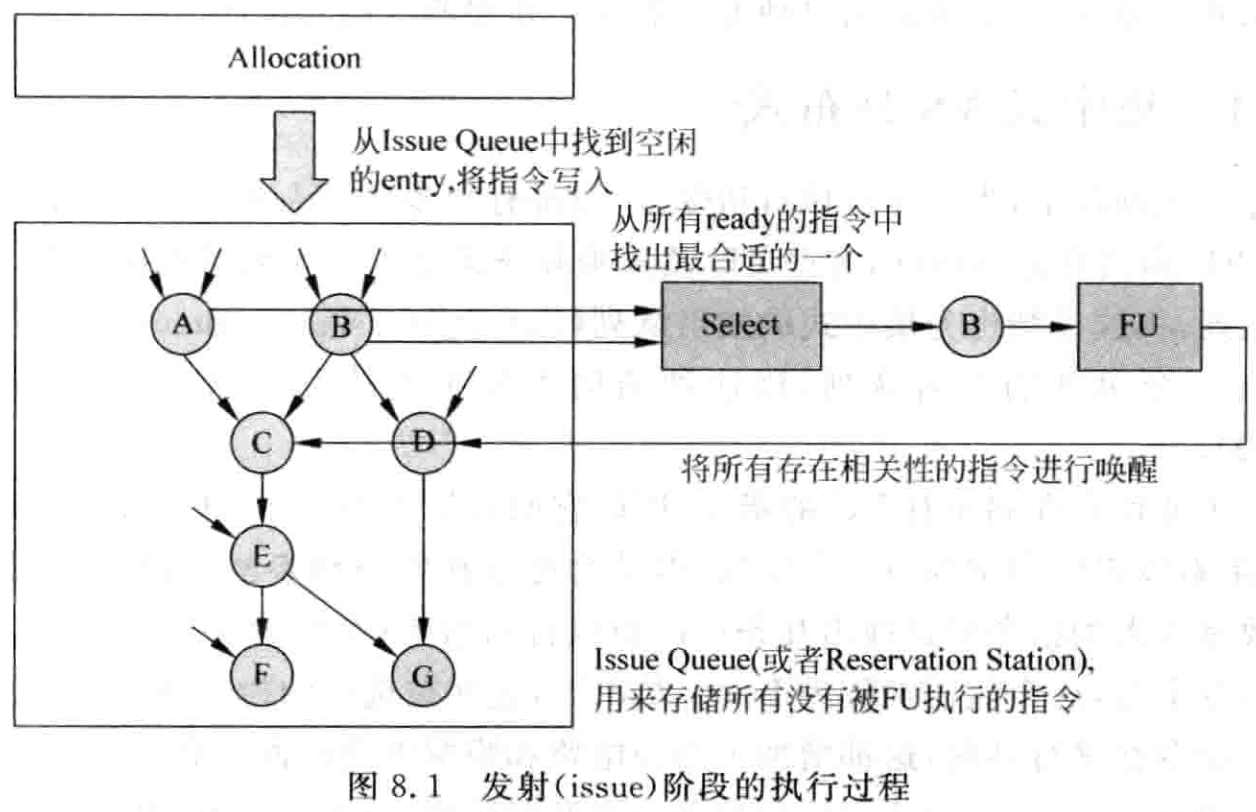
- IQ,用来存储已经被寄存器重命名但是还没有被送到 FU 执行的指令,通常也被称为 RS。
- 分配(Allocation)电路,用来从 IQ 中找到空限定三名,将寄存器重命名后的指令存储到其中,不同的 IQ 的设计方法会直接影响到这部分电路的实现。
- 选择(Select)电路,也称仲裁(Arbiter)电路,如果 IQ 中存在多条指令的操作数都已经准备好,这个电路会按照一定的规则,从其中找到最合适的指令送到 FU 中执行。
- 唤醒(Wake-up)电路,当一条指令经过 FU 执行而得到结果数据时,会将其通知给 IQ 中所有等待这个数据的指令,这些指令中对应的源寄存器就会被设置为有效的状态,这个过程即为唤醒。如果 IQ 中的一条指令的源操作数都有效了,这个指令就处于准备好(ready)的状态,可以向选择电路发出申请。 发射阶段的实现有很多方式,这个阶段的中心部件就是 IQ。IQ 可以设计成集中式(Centralized),也可以是(Distributed);可以是压缩的(Compressing),非压缩的(Non-Compressing);可以是数据捕捉(Data-capture),也可以非数据捕捉(Non-data-capture)。上面的属性彼此正交,可以相互结合。
8.1.1 集中式 Vs 分布式
处理器中不同的 FU 共用一个发射队列,称为集中式发射队列 Centralized IQ;每个 FU 有一个单独的发射队列,称为分布式发射队列 Distributed IQ。
- CIQ 要存储所有 FU 的指令,容量需要很大,它利用效率高,不浪费发射队列中的每个空间,但是会使选择电路和唤醒电路变得复杂,因为要从数量庞大的指令中选择几条可以执行的指令(个数取决于每周期最多可以同时执行的指令个数,这个数值成为 Issue Width),这些被选中的指令还需要将 IQ 中的所尊相关指令都进行唤醒,这增加了面积和延时。
- DIQ 每个 IQ 的容量可以很小,简化了选择电路的设计(每个 IQ 都对应一个选择电路)。但是当一个 IQ 已经满了的时候,即使其他 IQ 还有空间,也不能继续向其中写入新的指令,此时需要将发射阶段之前的所有流水线都暂停,知道这个发射队列中有空闲的空间位置。如一段时间内执行了大量加减法指令,可能加减法的 FU 对应的 IQ 已满,阻碍寄存器重命名,后续所有指令都无法接受继续通过重命名,即使其他 FU 的 IQ 还有空间,也需要将发射阶段之前的流水线都暂停,导致 IQ 利用率低下。而且由于它的分布分散,唤醒操作需要的布线复杂度上升。 这两种方式各有优缺点,现代处理器结合两种,使得某几个 FU 共用一个发射队列。
8.1.2 数据捕捉 Vs 非数据捕捉
一般来说,在流水线哪个阶段读取寄存器对应这两种方法。
数据捕捉
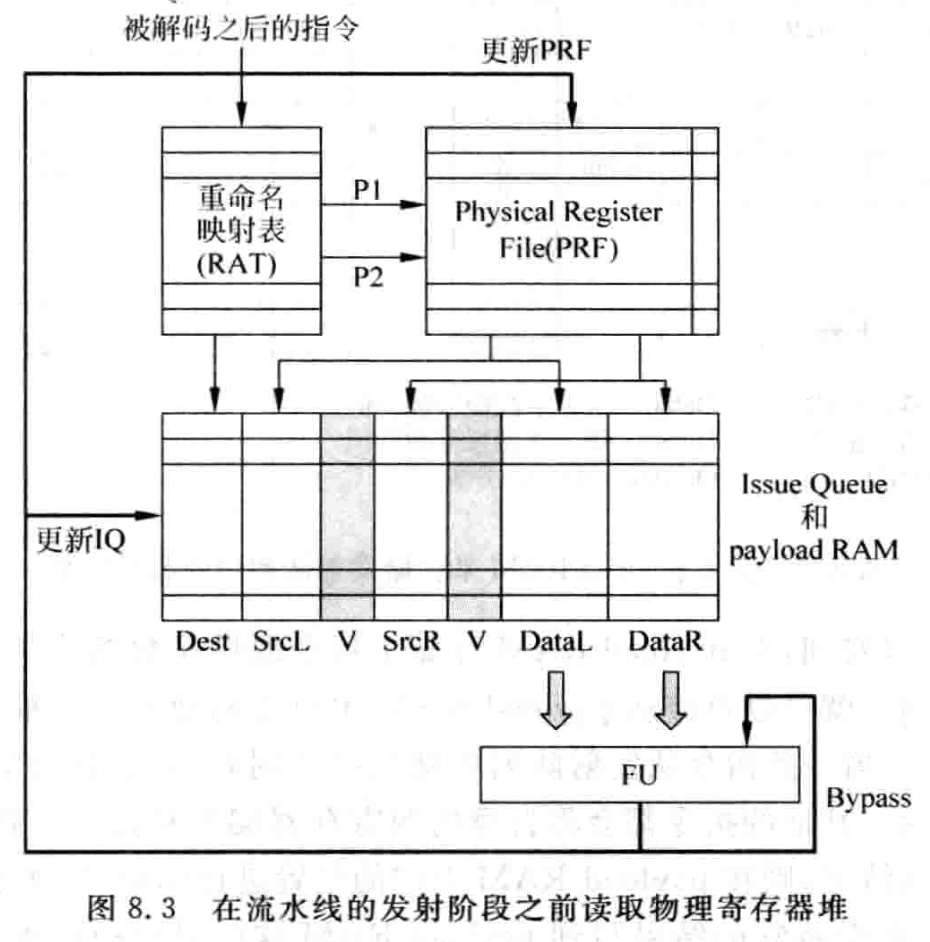
在流水线的发射阶段之前读取寄存器,称为数据捕捉 Data-capture 的结构。被寄存器重命名后的指令首先读取 PRF,然后将读取的数值随着指令写入发射队列中,如果有的寄存器的值还没有被计算出来,则会将寄存器编号写入 IQ,以供唤醒的过程使用,它会被标记为无法获得的状态,这些寄存器在之后通过旁路网络得到它们的值,不再需要访问物理寄存器。IQ 中,存储指令操作数的地方叫做 Payload RAM。
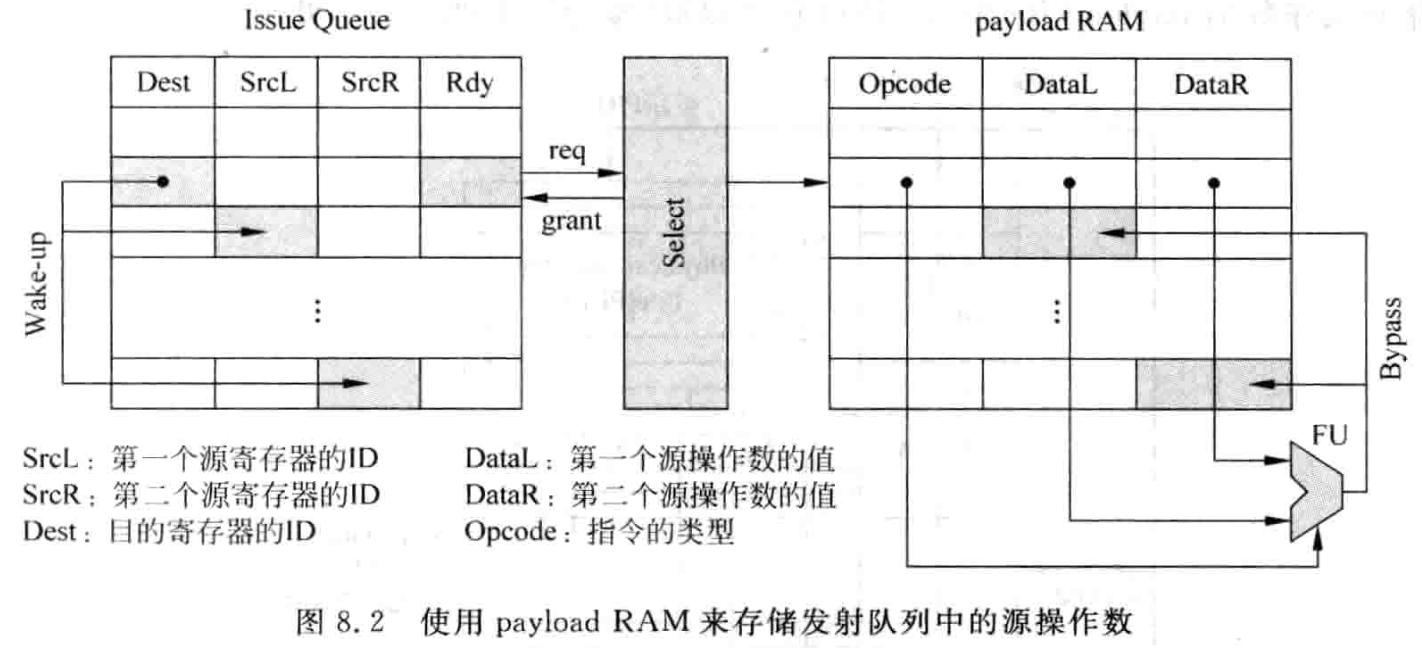
可以看出,在 payload RAM 存储了指令源操作数的值,当指令从 IQ 中被仲裁电路选中时,就可以直接从 Payload RAM 中对应的地方将源操作数读取出来,并送到 FU 中去执行。当一条指令从 IQ 中被选中的同时,它会将目的寄存器的编号值进行广播,IQ 中其他指令都会将自身的源寄存器编号和这个广播的编号值进行比较,一旦发现相等的情况,则在 payload RAM 对应位置标记,当那条被选中的指令在 FU 中计算完毕时,就会将它的结果写到 payload RAM 这些对应位置中,这是通过 bypassing network 实现的,这个方式就像是 payload RAM 在捕捉 FU 计算结果,所以称为数据捕捉结构,IQ 负责比较寄存器的编号是否相等,而 payload RAM 负责存储源操作数,并捕捉对应 FU 结果。
machine width 标记每周期实际可以解码和重命名的指令个数;issue width 标记每周期最多可以在 FU 中并行执行的指令个数。在一般的 CISC 处理器中,处理器内部将一条 CISC 指令转化为几条 RISC 指令,而存储到 IQ 的是 RISC 指令,只有使 issue width 大于 machine width,才能使处理器的流水线平衡;而 RISC 处理器中,一般这两个值都是相等的,但是考虑到由于指令之间存在相关性等原因,即使每周期可以解码和重命名四条指令,很多时候,也不能每周期将四条指令送到 FU。因此只有使 issue width 大于 machine width,才能最大限度寻找在 FU 中可以并行执行的指令,所以现代高性能处理器会采用很多个 FU,使每周期可以并行执行的指令个数尽可能多。
这种方法在流水线的发射阶段之前就读取物理寄存器堆 PRF,所以 PRF 需要的读端口个数是 (假设每条指令只有两个操作数),是直接和 machine width 相关的,过程如下:
非数据捕捉
在发射阶段之后读取 PRF,称为非数据捕捉 Non-data-capture 结构。被重命名的指令不会去读取 PRF,而是直接将源寄存器的编号放到 IQ 中,当指令从 IQ 被选中时,会使用这个源寄存器的编号来读取 PRF,将读取的值送到 FU 中执行。由于 IQ 中不需要存储源操作数的 payload RAM,处理速度增加。由于指令在发射后才读取 PRF,所以寄存器堆需要的读端口数是 ,这个值一般比较大,对读端口个数要求多一些。
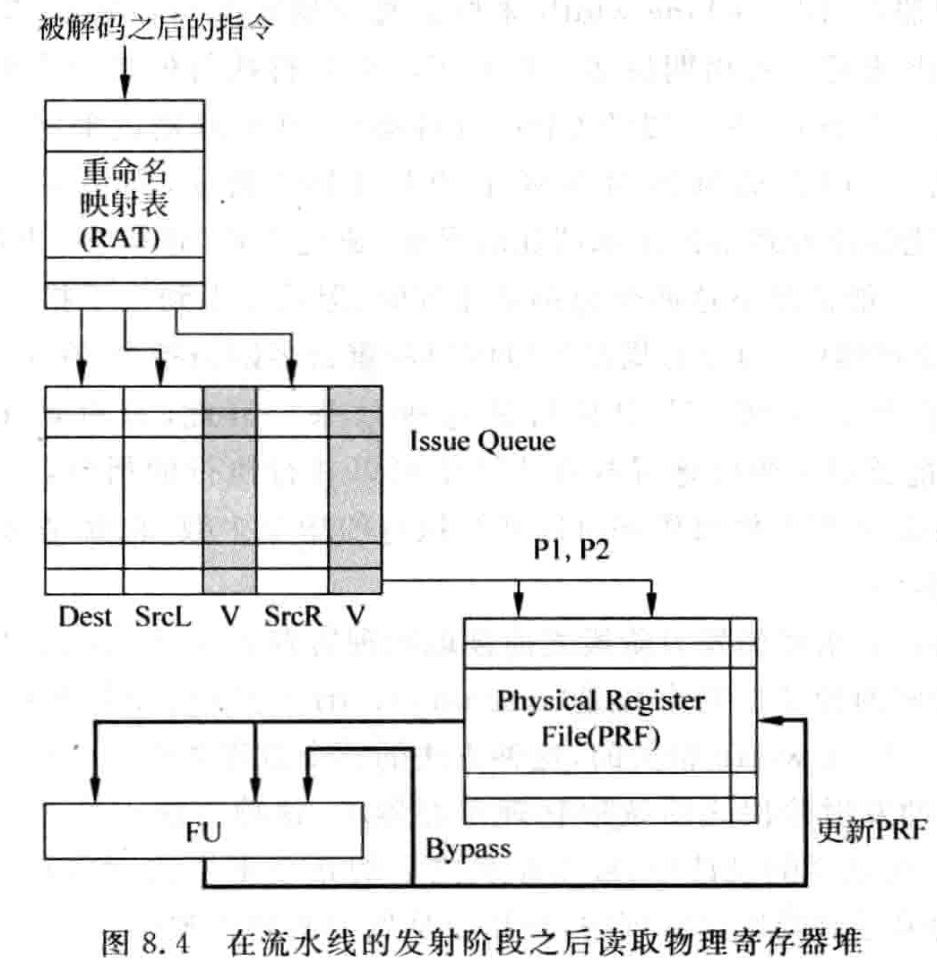
数据捕捉方式所需要的 PRF 读端口少,但是由于需要在 IQ 中存储操作数,占用面积更大,而且这种方法中,很多源操作数需要经历两次读和一次写的过程,即从寄存器中读取,写到 IQ,然后从 IQ 中读取送到 FU,这会消耗更多能量。非数据捕捉的面积功耗更低。这两种方法都有使用。它们决定了寄存器重命名的实现方式,使用 ROB 重命名时需要配合数据捕捉的发射方式,因为这种方式中,指令在离开流水线时,需要将它的结果从 ROB 搬移到 ARF,采用数据捕捉可以不用关心这种指令结果的位置变化。
8.1.3 压缩 Vs 非压缩
根据发射队列的工作方式,又可以将其分为压缩 (Connpressing) 和非压缩 (Non compressing) 两种结构,这两种结构直接决定了发射阶段的其他部件设计的难易,也影响着处理器的功耗。
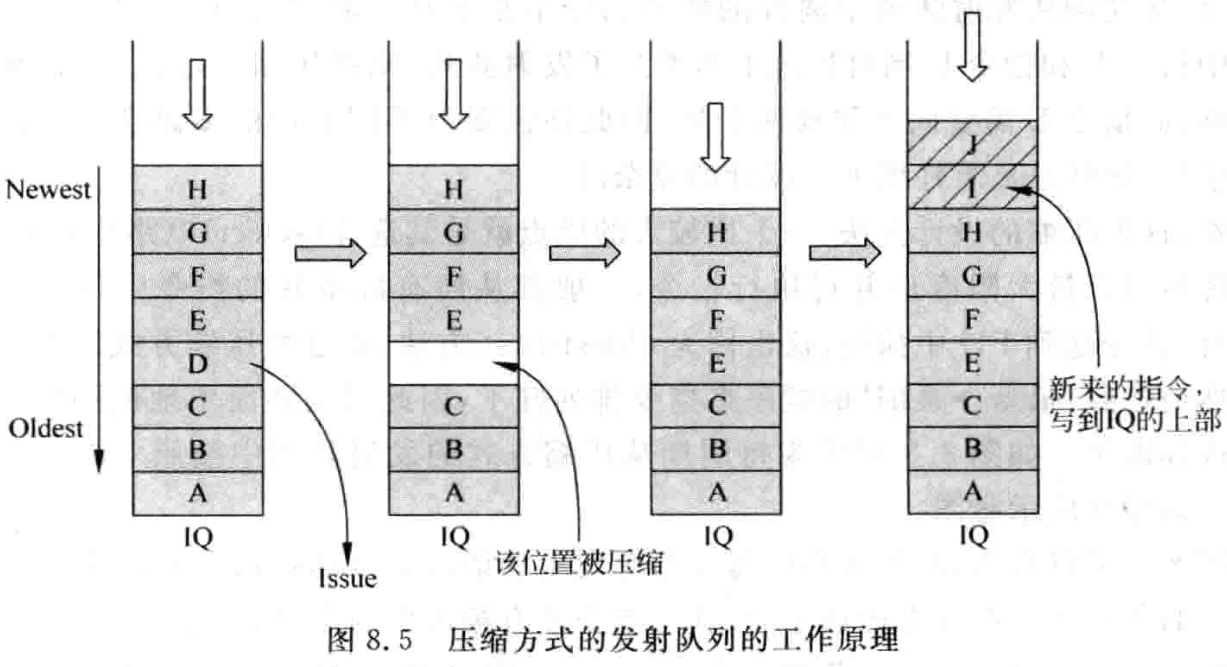
压缩的发射队列 (CompressingIssue Queue)
这种方法如图 8.5 所示,每当一条指令被选中而离开发射队人列时,会出现一个 ” 空隙 “,这条指令上面所有的指令都会下移一格,将刚才那条指令的 ” 空隙 ” 填上。想象一下,有 n 本一模一样的书,一本压一本地放到桌子上, 当从其中抽出某本书时,这本书上面的书都会下移,此时整体上这摞书的高度下降了,但是在这摞书中间并没有空隙。再看图 8.5 中的发射队列,想象有一个东西在向下压它,当一条指令离开而导致发射队列中出现空闲的空间时,在下压力的作用下,那个空闲的空间就会被 ” 挤走 “,这样发射队列当中所有的指令又都是紧紧地靠在一起了。而且发射队列当中的这些指令,从上往下看,是按照 ” 最新→最旧 ” 的顺序排列的,新来的指令会从发射队列上面的空闲空间开始写入。
在图 8.5 中,当指令 D 被选中而离开时,在发射队列中就会出现空闲的位置,经过压缩之后,这个空闲的位置会被 ” 挤掉 “,这样所有的指令又都靠在一起了,这就是压缩方式的发射队列。通过这种方式,可以保证空闲的空间都是处于发射队列的上部,此时只需要将重命名之后的指令写到发射队列的上部即可,例如图 8.5 中的指令 J 和指令 I。
要实现这种压缩的方式, 需要发射队列中每个表项 (entry) 的内容都能够移动到其下面的表项中,因此需要在每个表项前加入多路选择器,用来从其上面的表项 (压缩时) 或自身 (不压缩时) 选择一个,如图 8.6 所示。
图 8.6 表示了每周期能够 ” 压缩 ” 一个表项的发射队列的示意图,当然,如果发射队列每周期可以压缩两个表项,则每个表项的内容有三个来源,即上上面的表项、上面的表项以及自身,因此需要更多的多路选择器和布线资源,如图 8.7 所示。
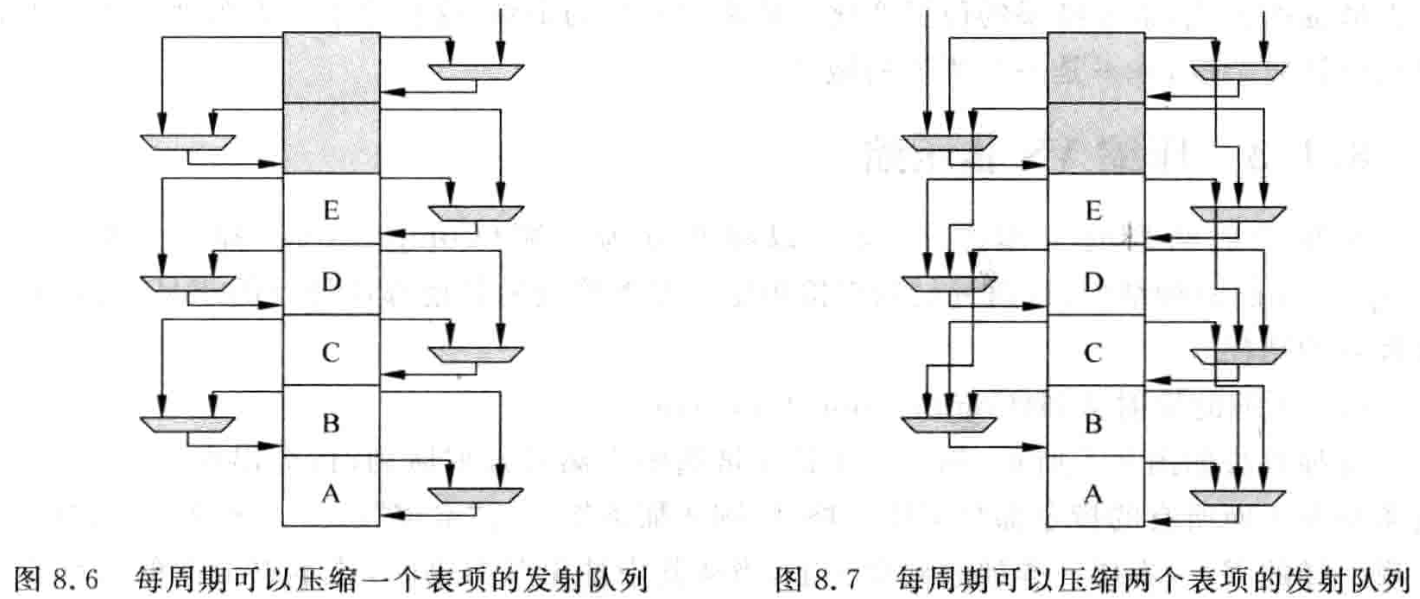
而且,每周期从发射队列中离开的两条指令不是靠在一起时 (这种情况很常见),例如图 8.7 中指令 B 和指令 D 同时被选中而离开了发射队列,则在压缩时,指令 C 需要向下移动一个格,而指令 E 需要向下移动两个格,因此还需对不同表项的多路选择器产生不同的控制信号,这样也显著地增加了设计的复杂度。
当然,这种压缩的设计方法,一个比较大的优点就是其选择 (select) 电路比较简单,为了保证处理器可以最大限度地并行执行指令,一般都从所有准备好的指令中优先选择最旧 (oldest) 的指令送到 FU 中执行,这也称为 oldest-first) 方法,而这种压缩方式的发射队列已经很自然地按照 ” 最新→最旧 ” 的顺序将指令排列好了,因此只需要简单地使用优先级编码器进行选择即可。如图 8.8 所示为每周期从压缩方式的发射队列中按照 oldest-first 的方式选择一条指令的示意图。
从图 8.8 可以看出,发射队列中每条指令发出的请求信号都受到它之前指令的影响,只有比它旧的所有指令都没有被选中时,这条指令才有被选中的资格,通过图 8.8 所示的与逻辑可以实现这个功能; 如果有任何一条指令在当前周期被选中了,则比它新的所有指令都不能够在本周期被选中,这样就按照 oldest-first 的原则,从人发射队列的所有指令中选择一条最合适的指令送到 FU 中执行。
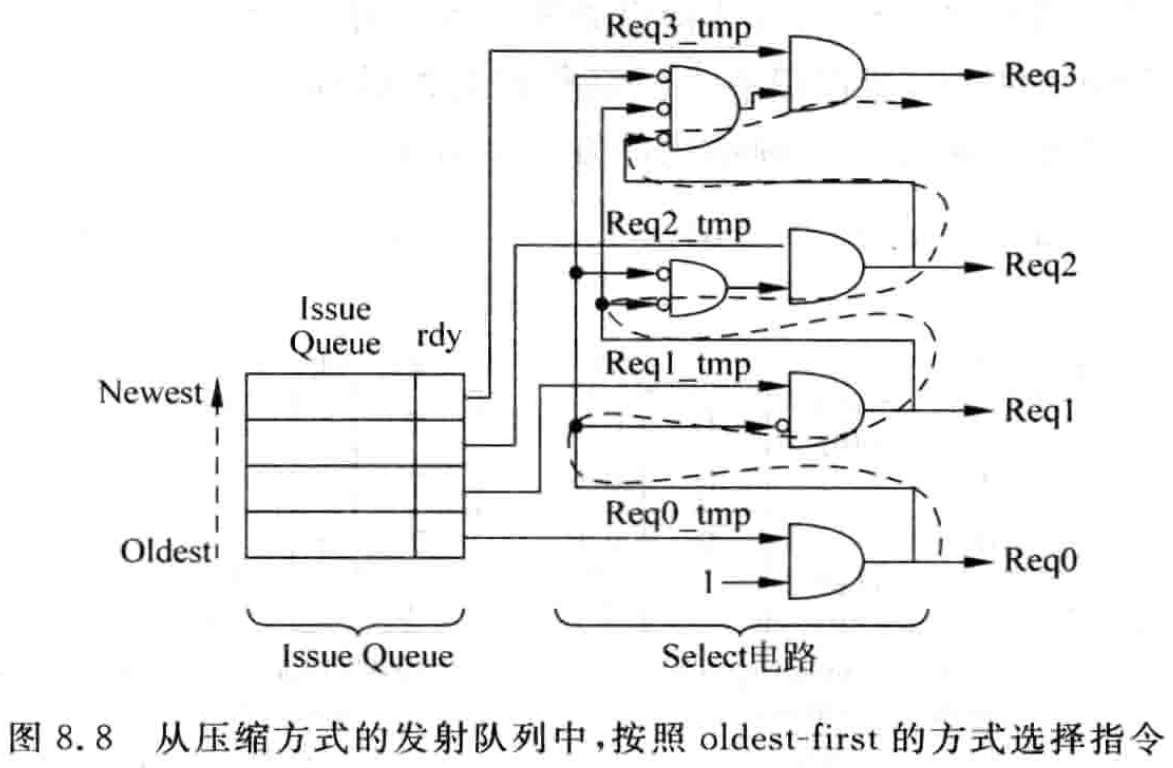
从图 8.8 可以看出,这样的设计方法,它的延迟和发射队列的容量是成正比的,发射队列中可以容纳的指令个数越多、延迟也就越大。图 8.8 中的虚线部分即表示了选择电路最长的路径,可以想象,当使用集中式的发射队列 (CIQ) 时,由于它的容量很大,所以选择电路的延迟会很大,这对于处理器的周期时间会带来很大的负面影响。
总结起来,这种压缩方式的发射队列的优点如下:
- 分配 (allocation) 电路很简单,发射队列中的空闲空间总总是处于上部,只需要使用发射队列的写指针,指向当前第一个空闲的空间即可。
- 选择 (select) 电路简单,因为这种方法已经使发射队列中的指令从下到上按照 ” 最新最旧 ” 的顺序排列好了,此时很容易用优先级编码器 ((priory encoder) 来从所有准备好的指令当中,找出最旧的那条指令,这样很容易实现 oldest-first 功能的选择电路。一般来说,在发射队列中最旧的指令,和它存在先写后读 (RAW) 相关性的指令也是最多的,先使这条最旧的指令送到 FU 中执行,可以最大限度地释放所有和它存在 RAW 相关性的指令,这样可以提高指令执行的并行度。
但是,这种方法的缺点也是很明显的:
- 实现起来比较浪费硅片面积,例如一个发射队列对应两个 FU 时,每周期要从中选择两条指令送到 FU 中执行,则发射队列需要支持最多两个表项 (entry) 的压缩,这需要复杂的多路选择器和大量的布线资源,增加了硬件的复杂度。
- 功耗大,因为每周期都要将发射队列当中的很多指令进行利多动,相当于 ” 牵一发而动全身 “,这显然增大了功耗。
非压缩的发射队列 (Non-Compressing Issue Queue)
在这种方法中,每当有指令离开发射队列的时候,发射队列中其他的指令不会进行移动,而是继续停留在原来的位置,此时就没有了 ” 压缩 ” 的过程。可以想象,在这种方法中,空闲空间在发射队列中的分布将是没有规律的,它可以位于发射队列中的任何位置,因此发射队列当中的指令将不再有 ” 最新→最旧 ” 的顺序,不能够根据指令的位置来判断指令的新旧。当然,此时仍可以使用上面方法中使用的选择电路,从发射队列中最下面的指令开始寻找,直到遇到第一条准备好的指令为止,但是这种选择电路对于非压缩结构的发射队列来说,相当于是一种随机的选择,因为此时指令的年龄信息和它在发射队列中的位置是没有关系的。当然这种基于位置的选择电路实现起来来很简单,也不会产生错误,但是由于没有实现 oldest-first 的功能,所以没有办法获得最好的为性能
图 8.9 以一个例子来解释这两种结构的发射队列的区别。
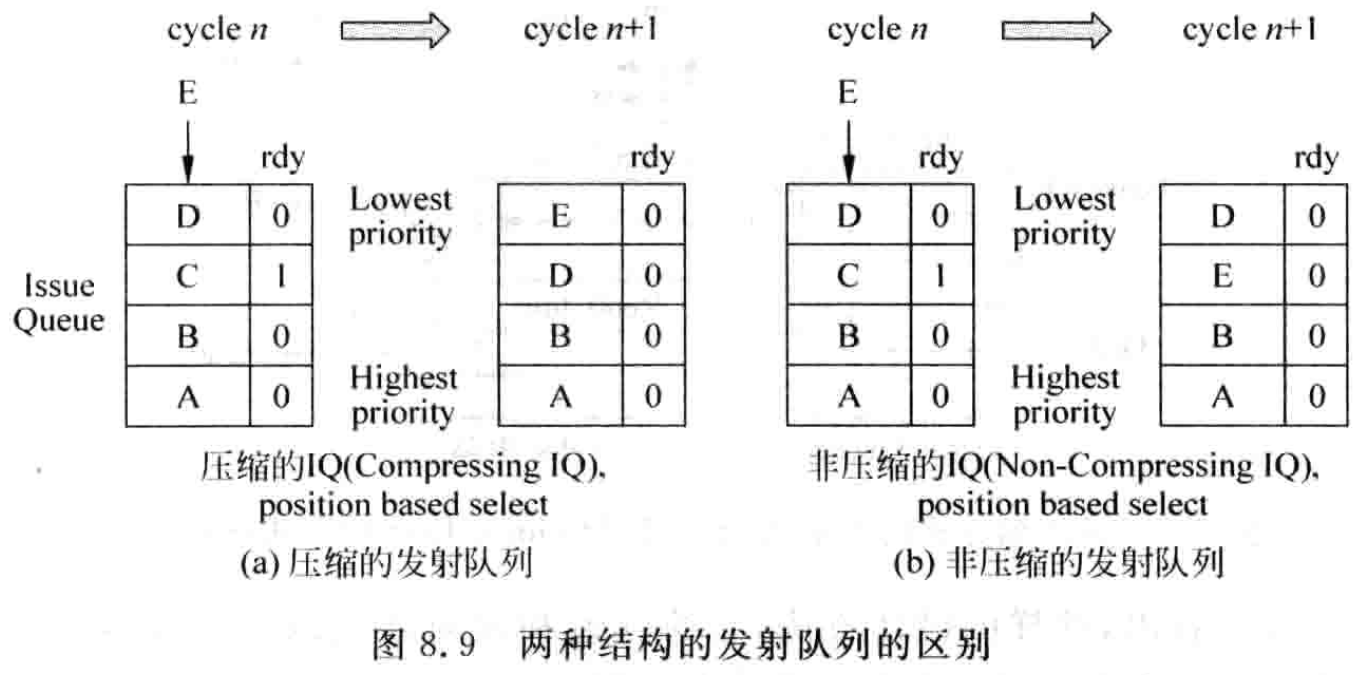
在图 8.9 所示的两种发射队列中,都根据指令在发射队列中的位置对其进行选择 (称为 positionbased select),图 8.9 (a) 的发射队列采用了压缩的结构,每次总是能保证选中最旧的指令,新来的指令只需要从发射队列的上部写入就可以了,如指令 E 所示;图 8.9 (b) 的发射队列采用了非压缩的结构,此时本质上是一种随机的选择,不能保证选中最旧的指令,新来的指令需要从发射队列中找到一个空闲的位置,例如指令 E。当然,这只是找到一个空闲的位置,相对还是比较容易的,当每周期需要找到几个空闲的位置时,实现起来就不是那么容易了。
总结起来,采用非压缩的发射队列,优点是其中的指令不再需要每个周期都移动,这样大大减少了功耗,也减少了多路选择器和布线的面积。当然这种方法的缺点也是很明显的,分别如下:
- 要实现 oldest-first 功能的选择电路,就需要使用更复杂的逻辑电路,这会产生更大的延迟;
- 分配 (allocation) 电路也变得比较复杂,无法像压缩方法中那样直接将指令写入到发射队列的上部即可,而是需要扫描发射队列中所有的空间间,尤其是当每周期需要将几条指令写入时,需要更复杂的电路来实现这个功能。
这两种结构的发射队列各有优缺点,在实际的超标量处理器中也都有使用,例如 Alpha21264 处理器采用了压缩结构的发射队列,而 MIPS R10000 处理器采用了非压缩结构的发射队列。
8.2 发射过程的流水
8 .2.1 非数据捕捉结构的流水线
进入到发射队列 (IssueQueue) 当中的一条指令要被 FU 执行,必须要等到下述几个条件都成立:
- 这条指令所有的源操作数都准备好了;
- 这条指令能够从发射队列中被选中,即需要经过仲裁电路的允许才能够进行发射
- 需要能够从寄存器、payloadRAM 或者旁路网络 (bypassing network) 中获得源操作数的值。
只有上述的三个条件都满足了,一条指令才会真正进入到 FU 中被执行,这三个条件是顺序发生的,对于一个源寄存器来说,如果它被写到发射队列中的时候,还处于没准备好的状态 (notready),等到之后的某个时间,它变为了准备好的状态,这个过程就称为唤醒 (wake-up), 这需要通过旁路网络才可以通知到发射队列中的每个源寄存器。唤醒的过程可以很简单,也可以很复杂,最简单的方法就是当一条指令在 FU 中得到结果时,将发射队列中使用这条指令计算结果的所有源寄存器都置为准备好的状态,这个过程如图 8.10 所示。
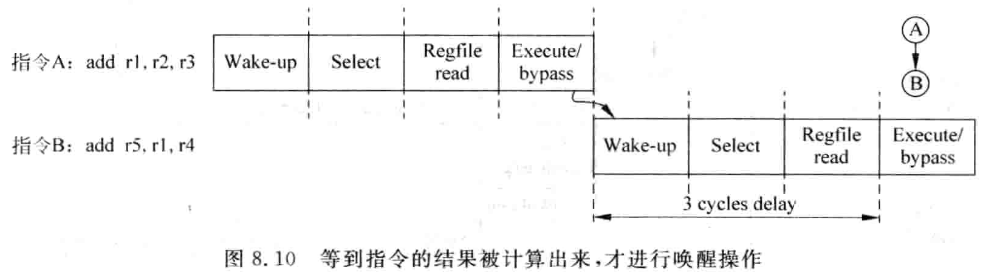
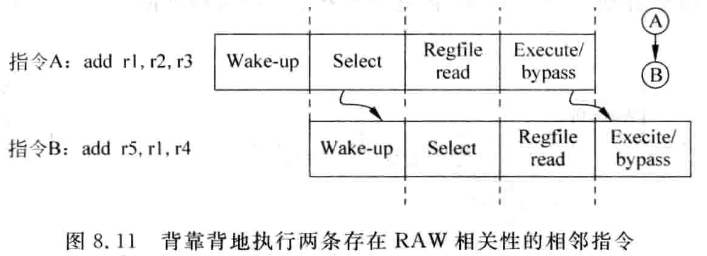
在图 8.10 中,发射 (issue) 过程被分为了唤醒 (Wake-up) 和仲载 (Select) 两个流水线阶段,在唤醒阶段,发射队列中的所有相关的寄存器会被置为准备好的状态,而在仲裁阶段,会使用仲裁电路从发射队列中选择一条最合适的指令送到 FU 中,这是发射过程最典型的流水线划分。从图 8.10 可以看出,两条存在先写后读 (RAW) 相关性的指令,不能获得背靠背的执行,它们的执行之间相差了三个周期,这样的执行效率显然还不是最高的。
其实,这种在指令执行完之后才对相关的指令进行唤醒的了方法正是 tomasulo 算法,早在 20 世纪六七十年代已经在 IBM 的处理器中采用了,这种方法也是现代超标量处理器的基础。为了能够获得更高的性能,一般都会对上述的方法进行改进,将唤醒的过程进行提前,最终可以背靠背地执行上述两条存在 RAW 相关性的指脂令,如图 8.11 所示。