FOREWORD
现代通用处理器,按指令集分类:
- 精简指令集(RISC):每条指令定长,降低解码难度,易于流水线;功耗成本低;完成某个功能可能需要组合多个指令来实现。
- 复杂指令集(CISC):指令不定长;力求单指令完成尽量多的事情,使用尽可能多的指令,覆盖各种操作,简化编译器设计;有较多的指令来支持特殊需求。 (80% 的 CISC 指令只在 20% 时间使用)
按处理器实现分类:
- 标量:每周期只能执行一条指令,一般按程序指定的顺序(顺序执行 in-order)。制约性能提高。
- 超标量:每周期可以执行多条指令,可以不按照程序指定的顺序,只要源数据准备好了就可以执行(乱序执行 out-of-order)。不会改变程序功能,需要更多的硬件资源和功耗。(备注:注意不是执行多条指令就是超标量处理器,后面会说的 VLIW,例如 DSP 也是可以多指令的,不过超标量是硬件决定多个指令的执行,VLIM 是靠编译器和程序员来决定并行执行的。)
按照这两个大类,以及各自的两个主要方向可以正交划分出 4 种常见的组合:
- Scalar CISC,处理器早期结构,直接对 CISC 指令解码,可能不带流水线,逐渐淘汰。(Intel 8086 处理器就是这个结构)
- Scalar RISC,RISC 早期结构,常使用流水线来提高性能,主频高成本低。(ARM7,CortexM)
- Superscalar RISC,RISC 指令规整所以首先引入了超标量执行多指令操作,性能提升。(ARM A7/A15)
- Superscalar CISC,CISC 不容易采用流水线和超标量结构,但是 Intel 和 AMD 在内部将一条 CISC 转换为多条 RISC 的方式来达到多指令和流水的需求,可能比普通的 RISC 需要更多的硬件和功耗。(Pentium 4/M) 上述是通用处理器的划分,专用领域可能还有其它架构和指令例如 VLIM,一般不会兼容专用指令,但是在特定领域可以有着比较好的性能。(备注:例如现在的一些加速器,可能就是个标量 RISC 的简化版)
Ch1 概览
1.1 为什么需要超标量
程序执行的经典公式: = 总的指令个数 x 每条指令需要的周期 x 每周期需要的时间
- 总的指令数量:取决于工作量,需要更好的算法,更强的编译器,是否有某个指令特殊功能和扩展的支持,已经完成程序这个值就固定了。
- 每条指令的周期:CPI(Cycles Per Instruction)和 IPC(Instruction Per Cycle)互为倒数,因为 CPI 表示每条指令需要的周期数;IPC 表示一个周期可以执行多少指令。对于非流水线的架构一条指令需要多个周期执行,普通流水线的架构一个周期最多执行一条指令。为了提高 IPC 的值,就需要超标量架构,完成一个周期执行多条指令(硬件自动选择,和 VLIW 不同)。
- 每周期需要的时间:通过电路设计或者提升硅工艺来达到,比如从 90nm 升级到 45nm 也许就可以提高主频,从而降低每周期的时间。 超标量处理器提升 IPC,通过每周期从 I-Cache 中取出 n 条指令送到流水线,称为 n-way 超标量处理器。通过硬件决定。 VLIW 也是一周期执行多条指令,不过 VLIW 需要编译器和程序员来决定哪些指令可以并行执行。
1.2 普通处理器流水线
概述
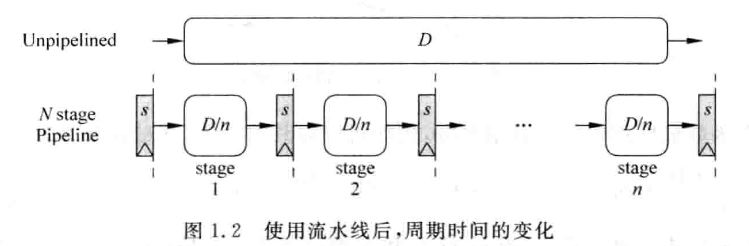
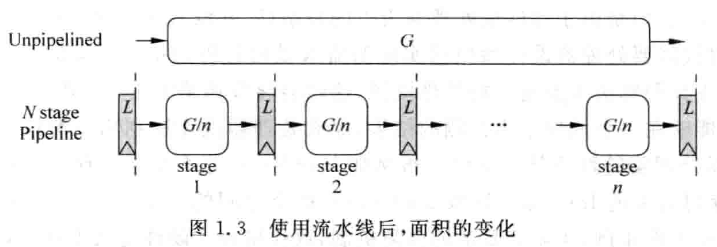 流水线后的面积、周期变化为(用频率表示性能):
流水线后的面积、周期变化为(用频率表示性能):
G 表示不加入流水线的硬件面积,L 表示流水线寄存器面积;D 表示不加流水线的电路延迟,S 表示流水线寄存器延迟。函数在 取得最优,但实际需要结合诸多需求来决定流水线级数。
流水线划分
理想的流水划分需要满足几个条件:
- 流水中被划分的每个阶段所消耗的时间要接近,最长的流水段决定了处理器的周期时间。
- 流水中的各个阶段都会被重复执行。当然在不需要的流水阶段直接跳过。
- 各个流水阶段的操作互相独立、互不相干,由于指令的相关性最难满足,常见的就是读写依赖。一般是影响流水执行的关键因素。
对于 CISC 指令集,指令不等长,执行时间不等,所以直接实现流水会比较难;而 RISC 指令集因为指令等长,每条指令完成的任务比较规整,所以容易实现流水。
经典 MIPS 处理器如下:
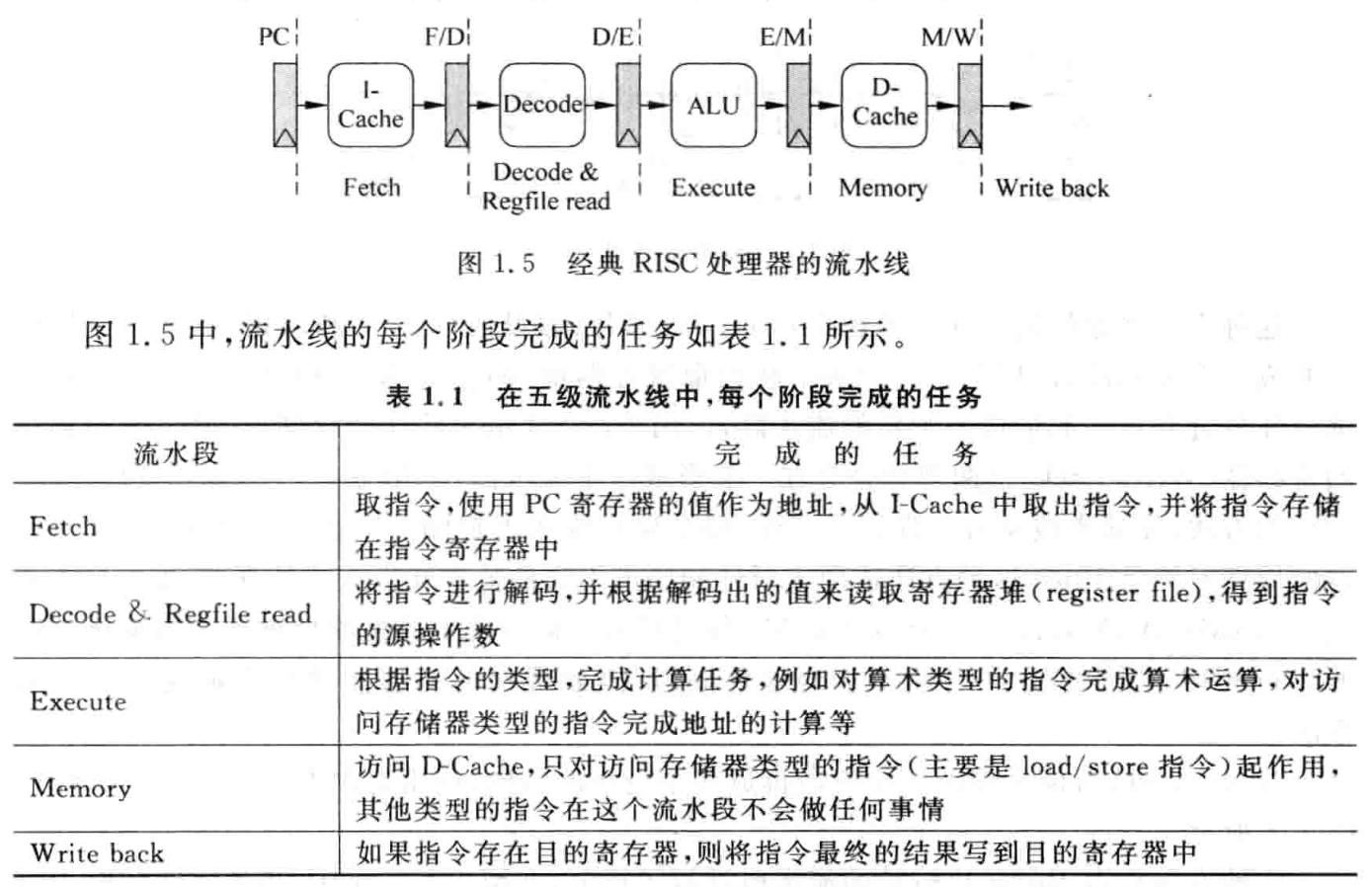 但这种流水未必最优,因为每个阶段的时间相差很多。
但这种流水未必最优,因为每个阶段的时间相差很多。
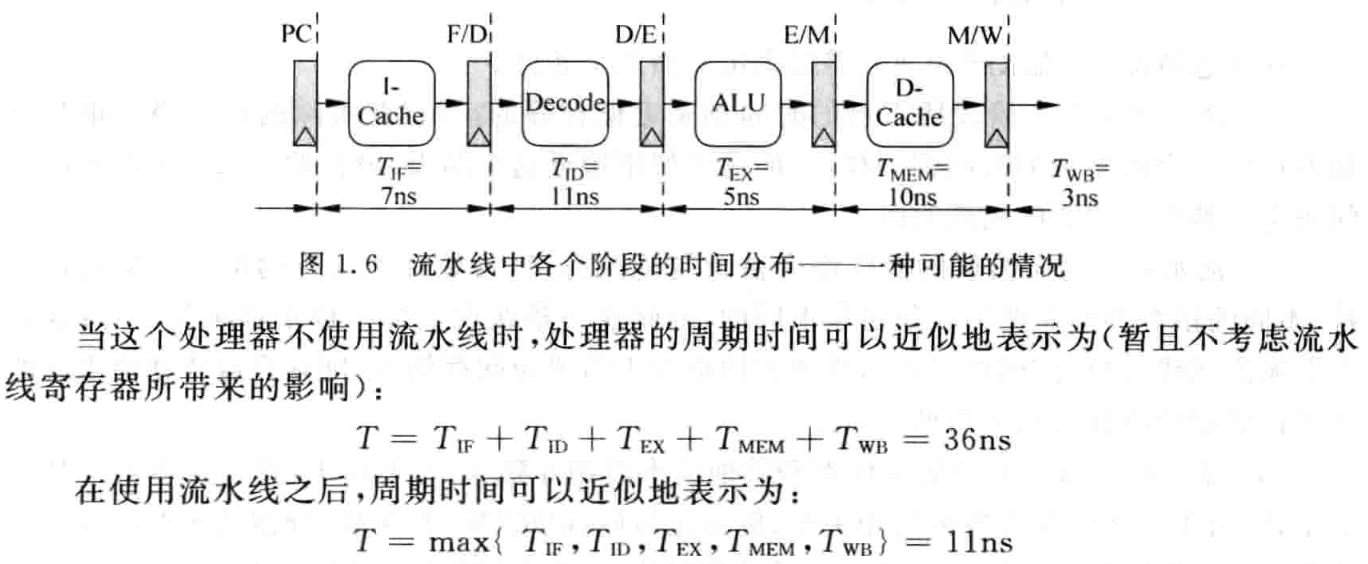 需要对流水线平衡,有两种方法:
需要对流水线平衡,有两种方法:
- 合并
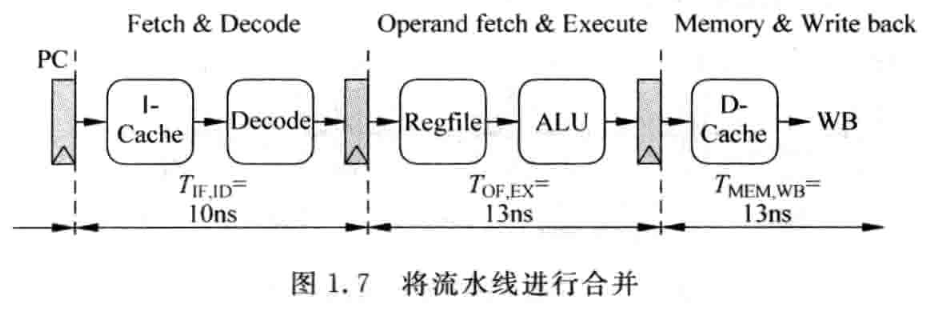 这种合并将流水线级降到三级,周期时间 13ns。这种方法适合性能要求不高的低功耗嵌入式处理器(ARM7/9、Cortex-M0/3)。
这种合并将流水线级降到三级,周期时间 13ns。这种方法适合性能要求不高的低功耗嵌入式处理器(ARM7/9、Cortex-M0/3)。 - 拆分
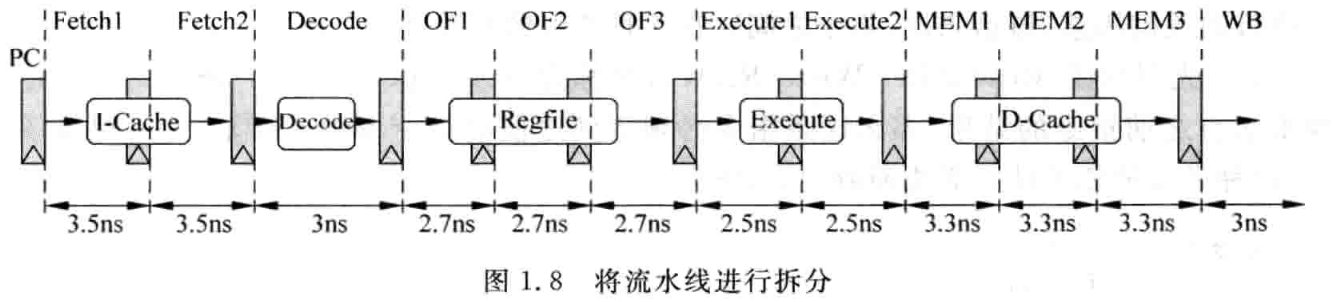 这种拆分方式将周期时间降低到 3.5ns,进一步提升了处理器性能。但是深流水线导致硬件消耗增大,如更多流水线寄存器和控制逻辑;寄存器端口、存储器端口需求也增多。同时功耗增大,预测的惩罚也增大。适合高频,高性能,不太在意功耗的场景。常见的就是 Intel,AMD 处理器。(Pentium 4 处理器,增加流水深度,最后导致功耗高,分支预测失败影响执行效率等因素,导致其还不如 Pentium 3,是“高频低能”)
在一定范围内拆分流水线是可以明显提高处理器性能的,虽然可能会增加功耗和硬件开销。
这种拆分方式将周期时间降低到 3.5ns,进一步提升了处理器性能。但是深流水线导致硬件消耗增大,如更多流水线寄存器和控制逻辑;寄存器端口、存储器端口需求也增多。同时功耗增大,预测的惩罚也增大。适合高频,高性能,不太在意功耗的场景。常见的就是 Intel,AMD 处理器。(Pentium 4 处理器,增加流水深度,最后导致功耗高,分支预测失败影响执行效率等因素,导致其还不如 Pentium 3,是“高频低能”)
在一定范围内拆分流水线是可以明显提高处理器性能的,虽然可能会增加功耗和硬件开销。
指令相关性
指令相关性一般有三种
- 先写后读(Read After Writer,RAW) 称为 true dependence,某条指令的操作数来自之前指令的结果,那就比较等之前指令执行完成才行。这类相关性无法避免,必须等前一条指令执行完成。
- 先读后写(Write After Read,WAR) 称为 anti dependence,指令结果将被写入某个寄存器,但是这个寄存器还在被其它指令读取。可以避免,将后执行的(下图中的 B)指令的结果写入其它寄存器即可。
- 先写后写(Write After Write,WAW) 称为 output dependence,两条指令想将结果写到同一个寄存器中去。可以避免,将其中一条指令(一般也是后一条)的结果写入其它寄存器即可。
除了指令相关性还有控制相关性(control dependence),一般是由分支指令引起
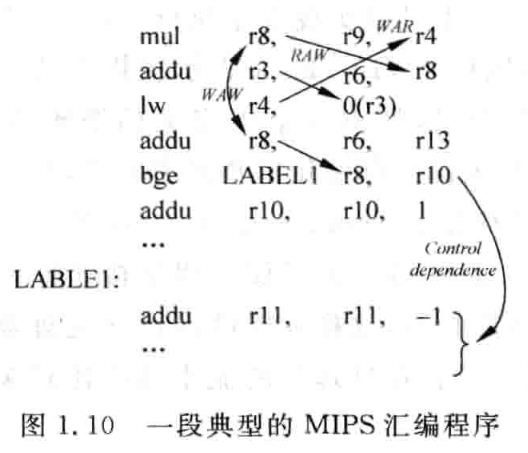 同时上面说的是指令相关性对寄存器的关系,其实这写相关性对存储器地址也是适用的。不过存储器依赖会更隐蔽一些,可能需要将一些 load/store 指令携带的地址计算出来才能知道。
同时上面说的是指令相关性对寄存器的关系,其实这写相关性对存储器地址也是适用的。不过存储器依赖会更隐蔽一些,可能需要将一些 load/store 指令携带的地址计算出来才能知道。
各种指令相关性导致在处理器中无法完全乱序执行,在一般处理器(标量) 中一个周期只执行一条指令的话,WAW 和 WAR 这两种相关性就不存在问题,RAW 则可以用旁路(bypass)来解决。对于超标量处理器WAW,WAR,RAW 这三种相关性都会阻碍乱序执行需要在流水中特殊处理。
1.3 超标量处理器的流水线
超标量处理器的定义:处理器在每个周期可以取出多于一条的指令送到流水线中执行,并且使用硬件来对指令进行调度。有两种指令执行方式,顺序执行(in-order) 和乱序执行(out-of-order)。

Frontend 表示取指令(Fetch)和解码(Decode),乱序执行很难或者无意义;
Issue 表示将指令送到对应的功能单元(FU)中执行,源数据准备好就可以乱序执行;
Write Back 表示将指令结果写到寄存器中,通过内部寄存器重命名(逻辑寄存器 ARF→物理寄存器 PRF)来达到乱序写回;
Commit 表示指令被允许更改处理器状态(Architecture state),为了保证程序按照本意执行且实现精准一场,需要顺序执行。
顺序执行
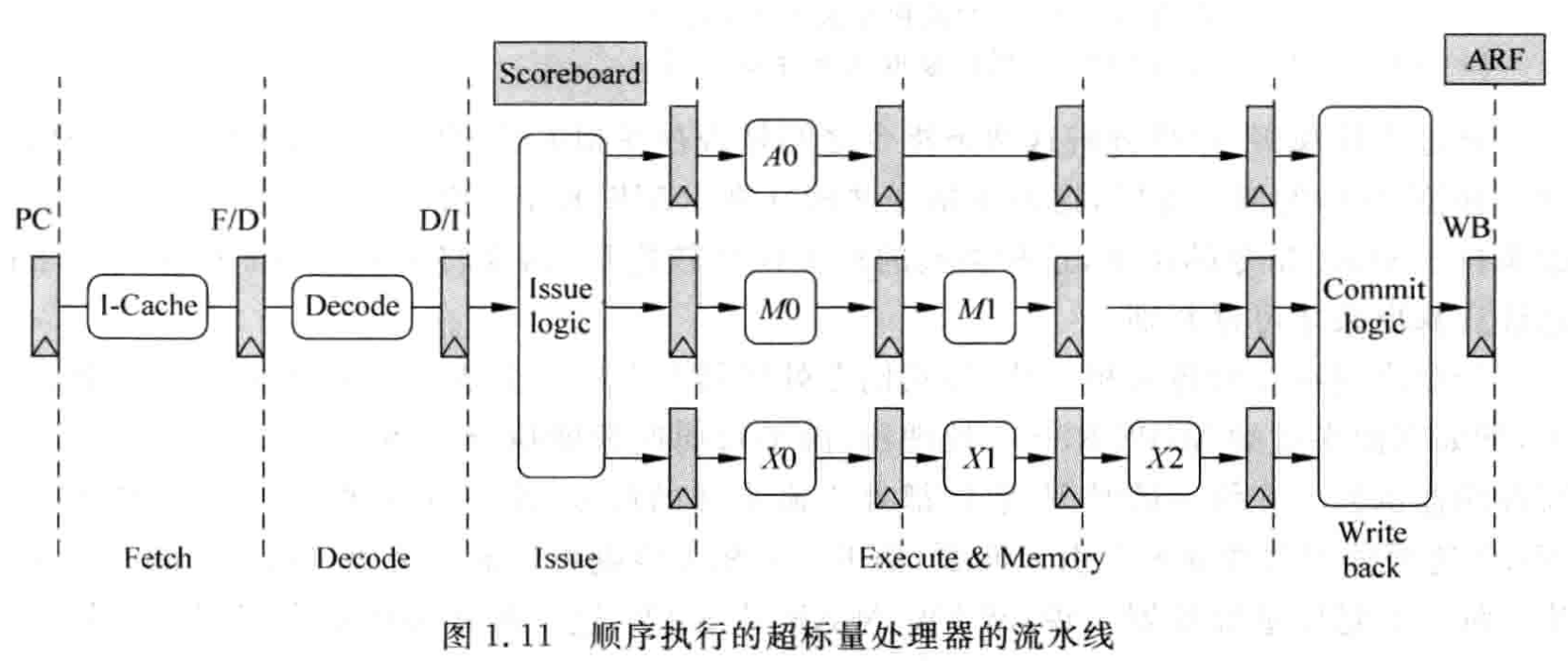
假设流水线每周期可以从 I-Cache 取两条指令执行,就称为 2-way 超标量处理器。指令经过解码后根据自身类型,将两条指令送到对应 FU 中执行,称为发射(Issue)。
发射若放到解码阶段,会影响周期时间,所以发射单独一个流水段。这个阶段,指令读取寄存器得到操作数,根据指令类型将指令送到对应 FU。执行用到三个 FU:1. ALU;2. 访存;3. 乘法。要保证写回阶段顺序执行,所有 FU 经历相同周期流水线,上图中都为三级。
ScoreBoard 记录每条指令的执行情况。记录指令集中定义的每个逻辑寄存器(R0-R31)的执行情况。
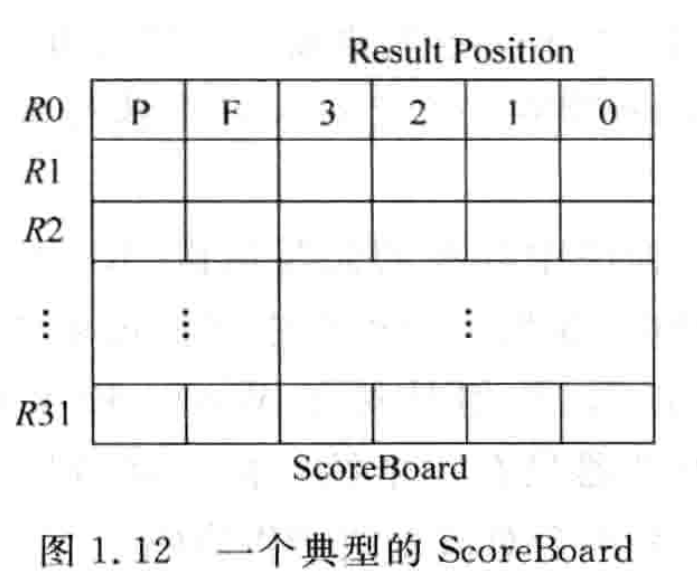
P pending 指令结果还没有写回到逻辑寄存器中
F 某条指令在哪个 FU 中执行,指令结果进行旁路时可能会用到。
Result Position:指令在 FU 中的哪个阶段,3 表示第一个流水阶段,1 表示最后一个流水阶段,0 表示处于回写阶段。在发射阶段,指令的信息写入 ScoreBoard 中,同时该指令查询 ScoreBoard 来获知自己的源操作数是否都准备好。这条指令被送到 FU 中执行的每个周期,这个值右移一位,以表示执行的阶段。不同的 FU 在不同的阶段可以进入旁路,如 ALU 在 3 可以旁路,MUL 在 1 才可以旁路。
下面用一段程序进行示例。

注意这是 2-way 的,其中 F 表示读指令,D 表示解码指令,I 表示发射,W 表示回写。不要和指令 A,B,,,F 搞混了。
对于上图的旁路操作实际上是简化了,正常不需要等回写阶段才能旁路,否则就会像指令 F 一样,它和前面的指令不相关,但因为顺序执行而阻塞到指令 D 发射后,它才能执行。每条指令都可以旁路获得操作数,不需要等待源寄存器写回,但指令需要顺序执行,所以指令很多时候都处于等待状态。
对于图中右边的 RAW 相关性是不可避免的,WAW 和 WAR 相关性由于顺序执行只有位于最后一级的统一写回阶段,所以不会影响流水线。
乱序执行
OoO 超标量处理器中,指令在流水线中不在遵循程序指定的顺序来执行,一旦某条指令的操作数准备好了,就可以送进 FU 执行。
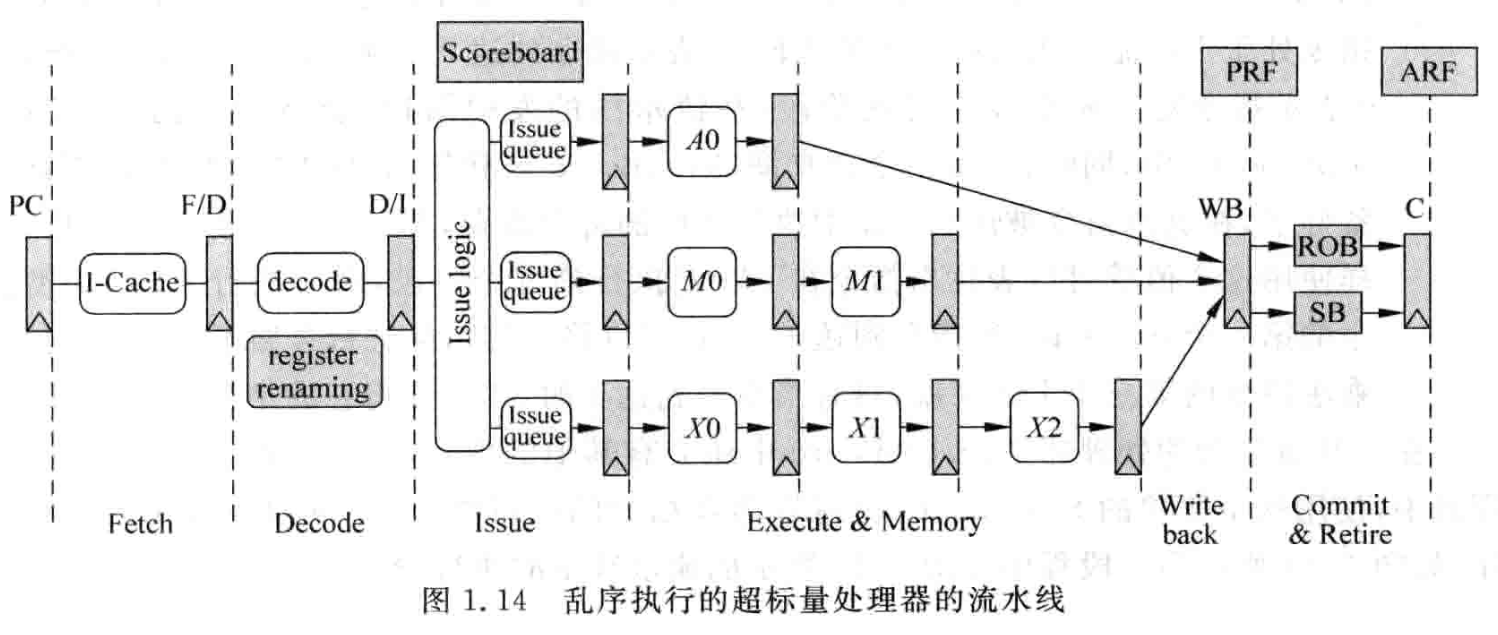
- 要解决乱序执行的 WAW 和 WAR 相关性,需要对寄存器重命名(register renaming),这个过程可以在解码阶段或者单独一个阶段来完成。处理器需要额外增加多于 ARF(逻辑寄存器)个数的 PRF(物理寄存器)来进行映射。
- 发射之前,指令顺序执行。发射阶段,指令被放到发射队列中(Issue Queue,IQ),一旦操作数准备好就可以被发射到 FU 中,发射阶段是顺序和乱序的分界,直到 Commit 之前都是乱序的。
- 每个 FU 都有自己独有的流水级数,比如 ALU 就只有一个阶段,由于 FU 执行周期数不同所以写回也是乱序的。一条指令只要计算完成结果就会写回结果到 PRF 中,但是由于分支预测失败或异常的存在,PRF 的结果不一定都会写入 ARF 中,因此 PRF 也称为 Future File。
- 为了保证程序串行结果,指令要按程序顺序更新处理器状态,因此在 Commit 阶段所有指令经过重排序缓冲(ROB) 来进行顺序更新。指令在这一阶段将结果写回 ARF,同时配合异常处理。如果指令顺利离开流水线并更新处理器状态,就称该指令退休(retire) 了,它也无法回到之前的状态了。
- 这对于 store 指令就需要额外处理,因为 store 指令需要写存储器,如果因为预测失败或异常等原因这条指令要抹掉,之前的存储器结果可能已经被覆盖了,就无法将存储器的状态恢复了。所以需要增加一个 Store Buffer(SB) 来存储 store 在没有退休之前的结果。store 指令的结果,在写回阶段被缓存到 SB 中,只有 store 真的 retire 后才将 SB 的结果写到存储器中。这样,load 指令,除了从 D-Cache 找数据,还需要从 SB 找数据。这会增加一些设计复杂度。
下面是一个 2-way 的乱序超标量处理器示例程序:
 补充一个 r 表示指令计算完成,在 ROB 中等待 retire。一条指令只有等它之前的指令都离开 ROB 了,才可以离开 ROB 然后进入 retire。C 表示经过 Commit 离开流水线而退休,提交是顺序执行的。
对比两个执行流水周期,乱序的只要 9 个周期,小于之前的 12 个周期,可以说明一定程度的乱序是可以提高执行流水效率的,当指令更多时,这种优势会更明显。
补充一个 r 表示指令计算完成,在 ROB 中等待 retire。一条指令只有等它之前的指令都离开 ROB 了,才可以离开 ROB 然后进入 retire。C 表示经过 Commit 离开流水线而退休,提交是顺序执行的。
对比两个执行流水周期,乱序的只要 9 个周期,小于之前的 12 个周期,可以说明一定程度的乱序是可以提高执行流水效率的,当指令更多时,这种优势会更明显。
超标量流水各个阶段简介
- Fetch(取指令):这部分负责从 I-Cahce 取指令,主要由 I-Cache(存储最近常用指令)和分支预测(决定下一条指令的 PC 值)两个部件组成,在超标量处理器中需要特殊处理。
- Decode(解码):识别指令类型,需要的操作数,控制信号等。和指令集定义非常相关,一般来说 RISC 比 CISC 要简单,CISC 的逻辑会更复杂化,但是对超标量处理器来说 RISC 也需要一些特殊操作,会比一般处理器复杂一些。
- Register Renaming(寄存器重命名):为了解决 WAW 和 WAR 问题,需要将 Decode 阶段得到的逻辑寄存器 ARF 映射到物理寄存器 PRF 上,PRF 会多于 ARF,通常使用一个表格来存储映射关系,以及剩余 PRF 信息等。还需要使用电路来分析 RAW 相关性然后进行指令标记,后续通过旁路网络来解决他们的真相关性。因为这一阶段比较耗时,所以一般是单独一级而不是和解码在一起。
- Dispatch(分发):重命名的指令按顺序写入发射队列(IQ, Issue Queue)、重排序缓存(ROB)和 Store Buffer 等部件,如果这些部件没有空闲,指令就需要在重命名阶段等待,相当于暂停了寄存器重命名及之前的所有流水线。分发可以和寄存器重命名放一起,在对周期时间要求比较高的处理器中,也可以单独放一个流水段。
- Issue(发射):仲裁(Select)电路会从 IQ 中选出合适的指令送到 FU 中。对于顺序发射,只需要判断最旧的那一条是否准备好;对于乱序发射,需要对所有指令进行判断,并选出最合适的送到 FU 中。OoO 中,发射阶段是顺序和乱序的分界,直到 Commit 之前都是乱序的。IQ 中会有唤醒(weak-up)电路,会将 IQ 中对应的源操作数置为有效态,仲裁和唤醒互相配合,是超标量处理器的关键路径。
- Register File Read(读取寄存器):被仲裁电路选中的指令从 PRF 或者旁路网络(大多数都是这种方式)中获得操作数。由于超标量处理器每周期有多个指令,所以 PRF 需要的端口数也比较多,通常多端口寄存器堆的范围速度都不会太快,因此这个阶段常使用单独的流水段。
- Execute(执行):指令得到源操作数之后就进入对应的 FU 执行,超标量处理器通常有多个不同的 FU,比如普通计算,乘累加,分支指令,load/store。部分现代处理器还会有单独的媒体运算 FU 比如单指令多数据的 SIMD 运算 FU。
- Write Back(写回):这个阶段将 FU 的计算结果写到 PRF 以及通过旁路网络将结果送到需要的地方,一般是所有 FU 的输入端,由 FU 的输入端决定需要哪些数据。现代处理器中旁路网络是影响速度的关键因素,因为这部分需要大量布线,随着硅工艺尺寸减少,连线延时甚至会超过门延迟。解决方案多采用 Cluster 结构将 FU 进行分组,组内布局布线紧挨,这个组路径短,可以一周期完成;跨组旁路就需要多周期了。
- Commit(提交):这部分主要部件是 ROB,保证能顺序提交结果和精准异常。重排序信息是在 Dispatch 阶段写入 ROB 的。正常执行和异常执行都必须要在 Commit 阶段处理,不能提前中断。指令一旦从 Commit 离开而 retire 那就是对处理器状态进行了更新,无法回到之前的状态了。 对于超标量处理器,处理器的状态恢复也非常重要,因为深度流水需要预测获得高性能。典型例子是分支预测可以利用分支指令的规律性。但在某些预测失败的时候需要进行错误修正,恢复状态等,那就需要有恢复电路。它不仅将错误指令从流水线抹掉,还要将这些错误指令在流水线中造成的“痕迹”消除如重命名映射表或已写回 PRF。恢复电路和预测技术是天生一对,激进的预测可能会有更好的性能,代价是更复杂的恢复电路。在超标量处理器中对异常的处理也需要抹掉流水中的指令,所以也需要恢复电路来使得处理器恢复到正确的状态。